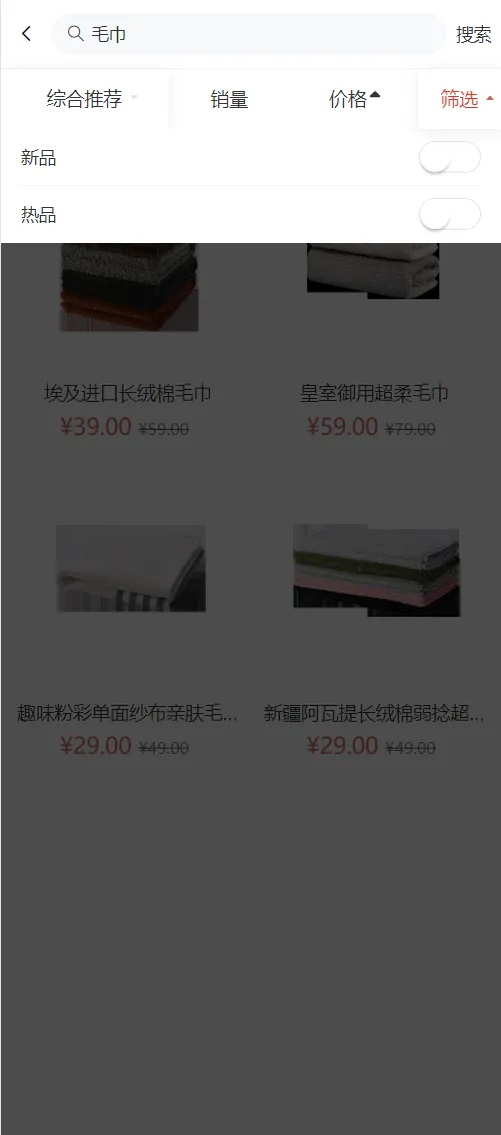
waynboot-mall 是一套全部开源的微商城项目,包罗三个项目:运营背景、H5 商城和后端接口。实现了一套完整的商城业务,有首页展示、商品分类、商品详情、sku 详情、商品搜索、加入购物车、结算下单、支付宝/微信支付、订单列表、商品评论等一系列功能。本文大纲如下,
如果觉得这篇文章写的不错的话,不妨点赞加关注,我会更新更多技能干货、项目教学、经验分享的文章。
| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |