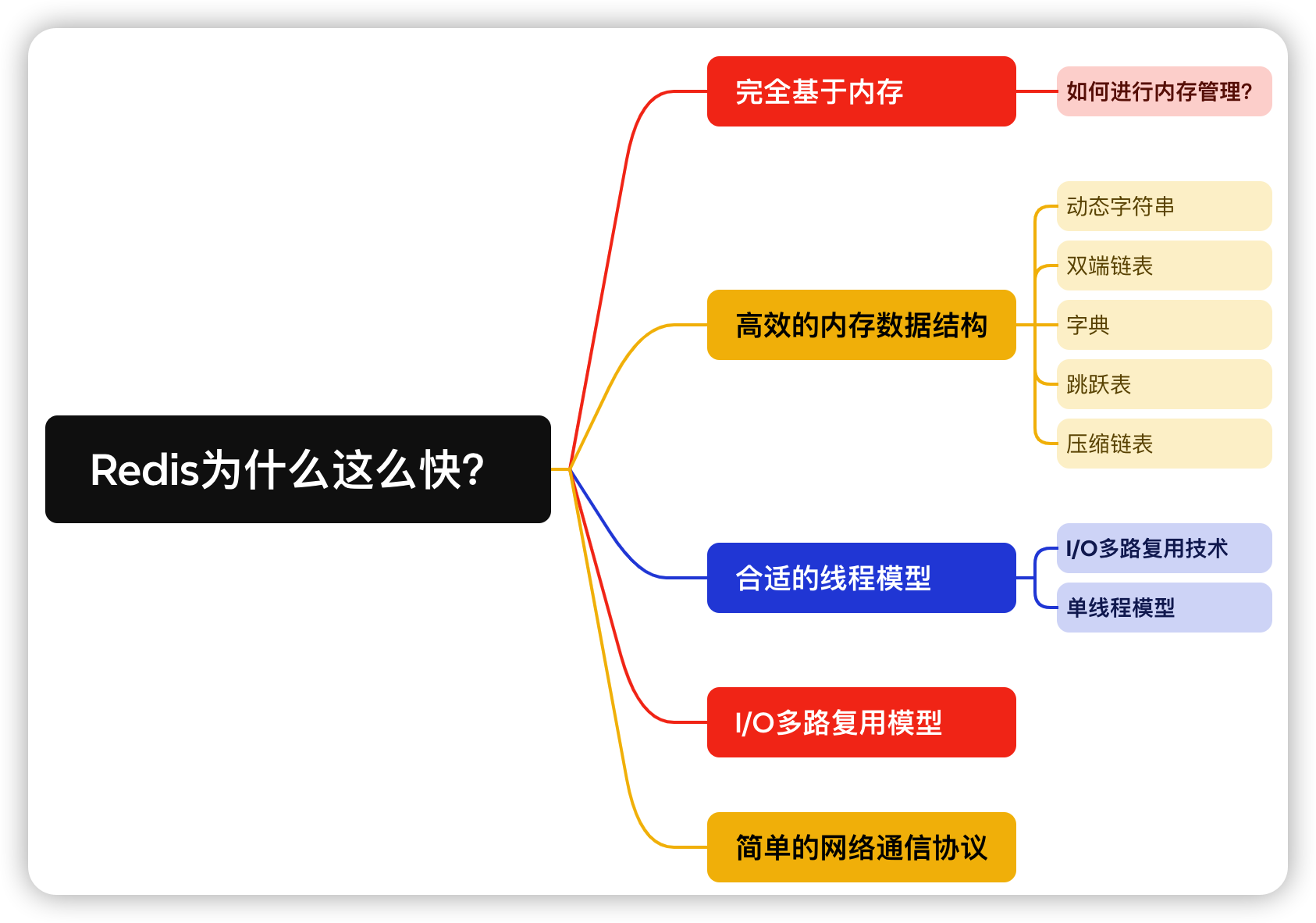
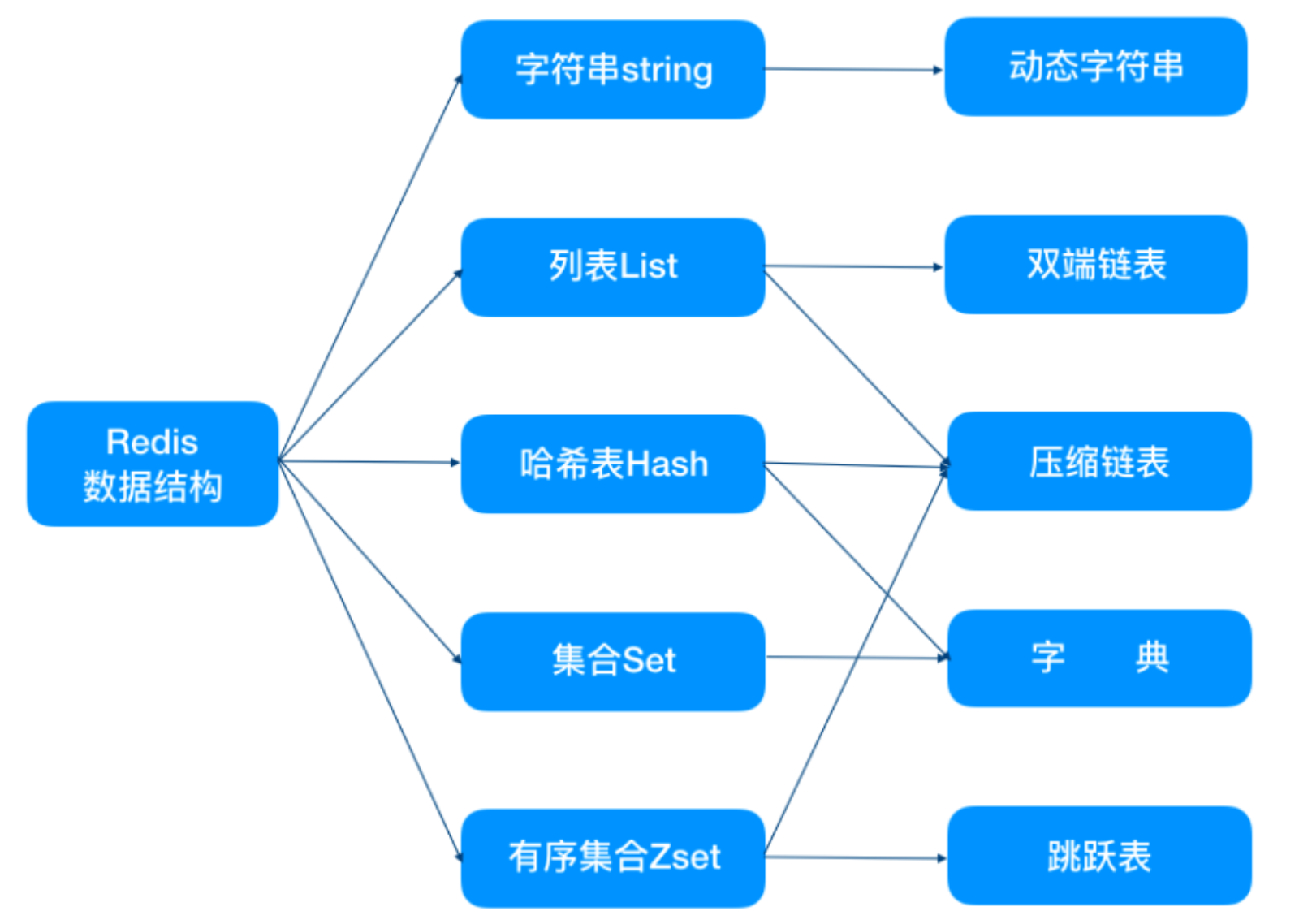
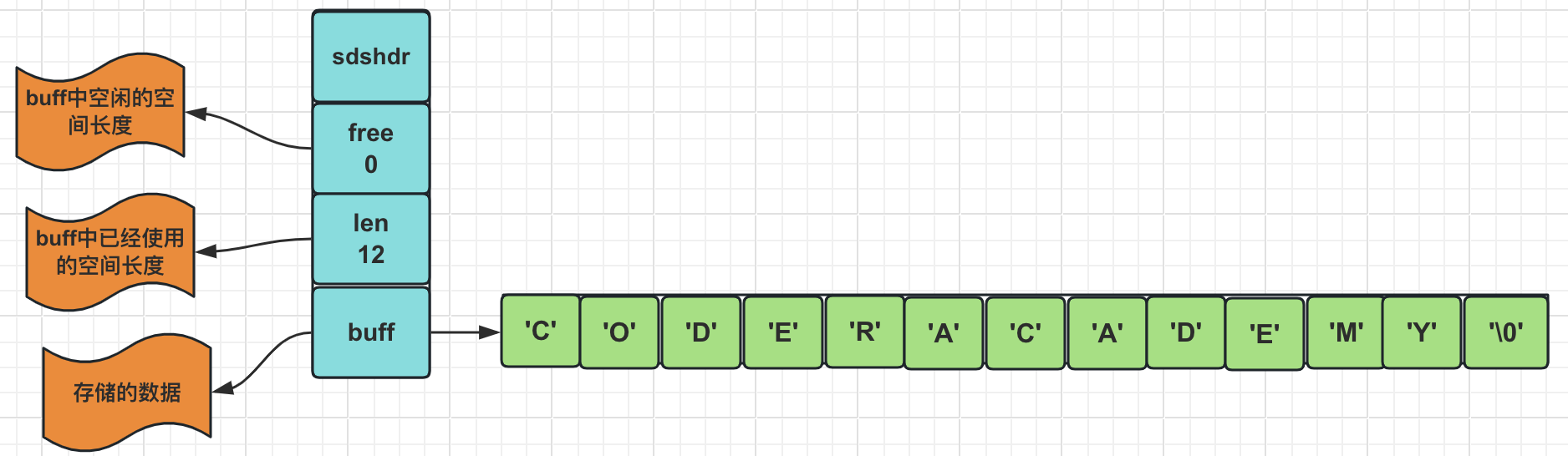
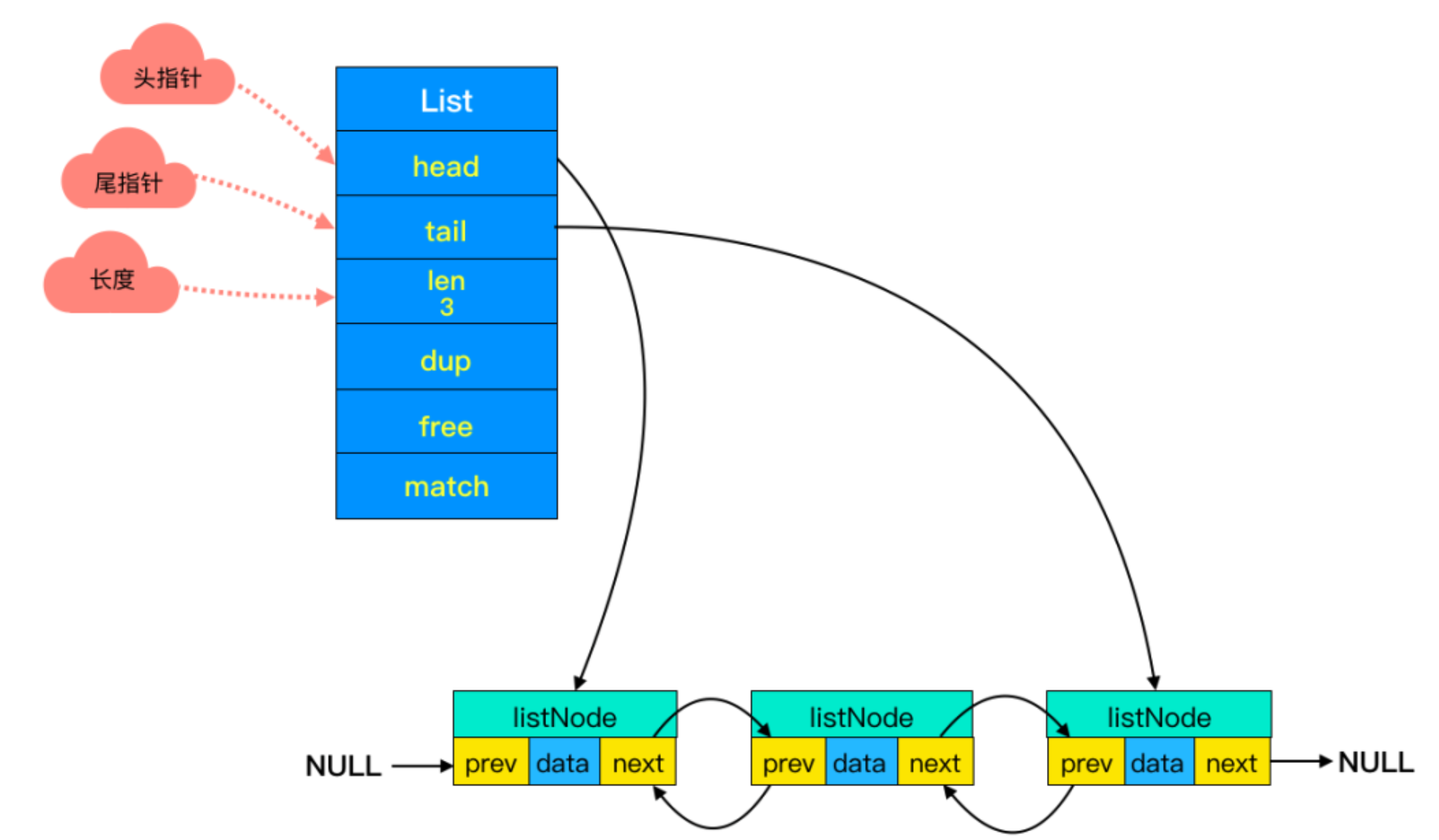
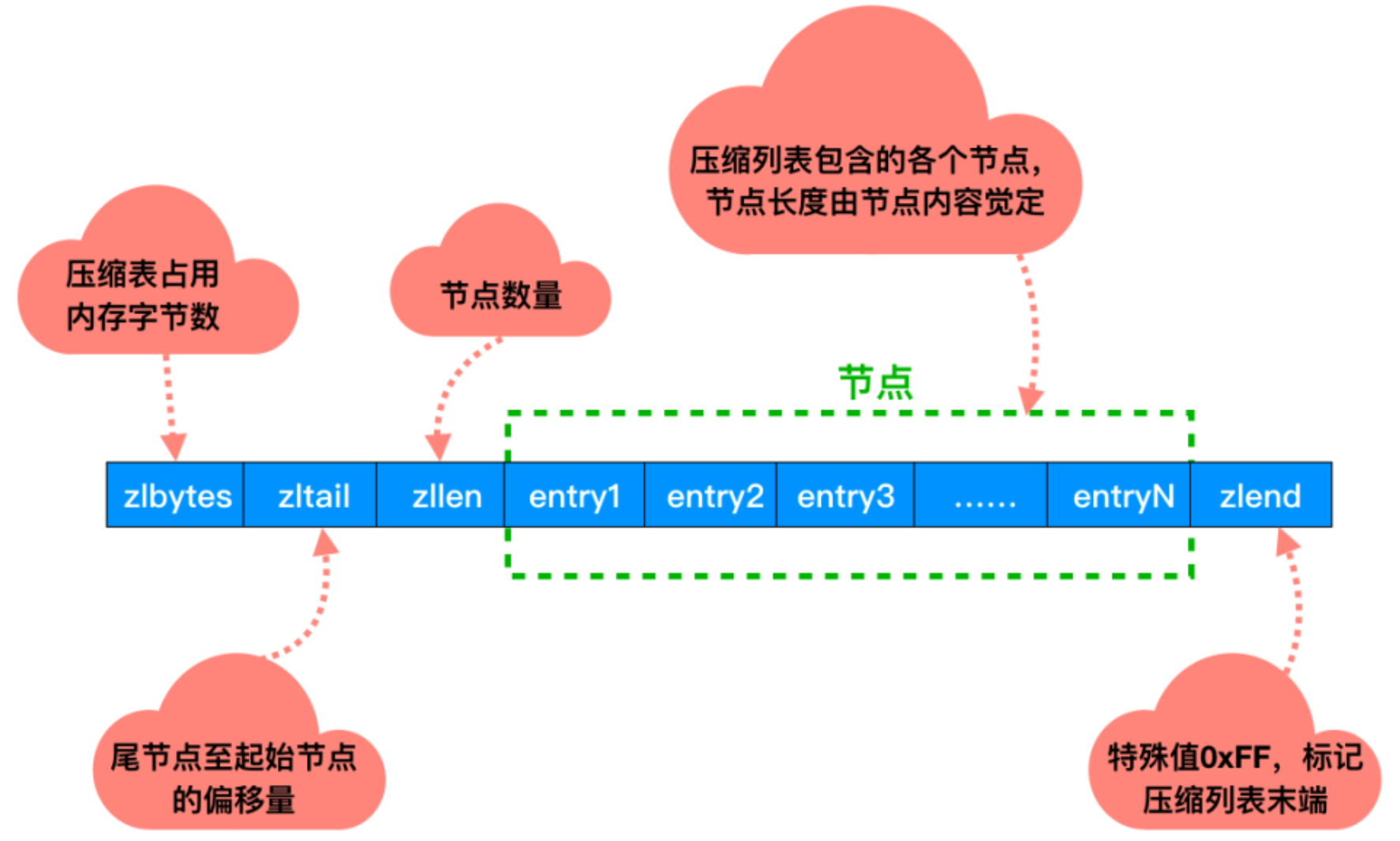
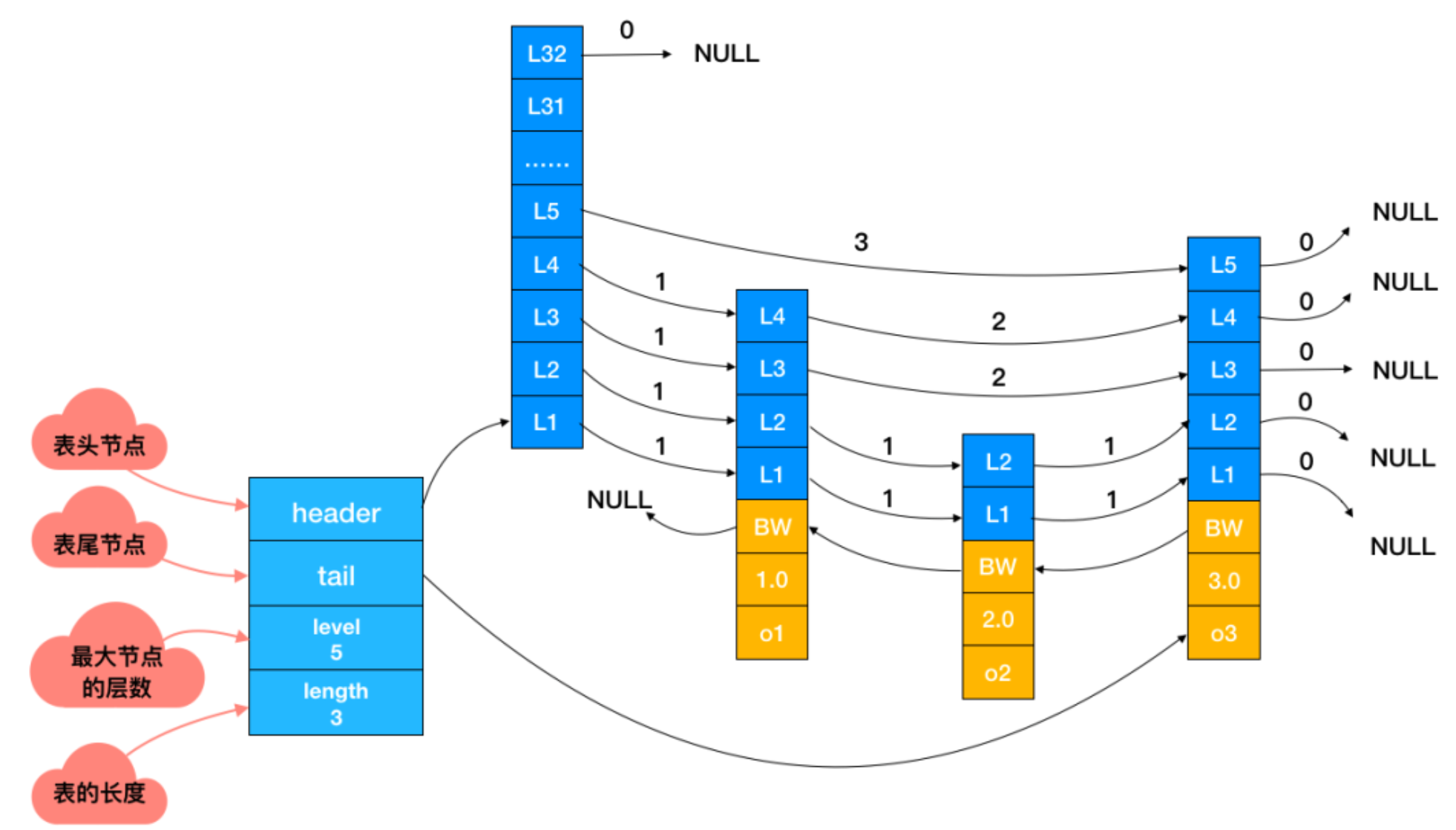
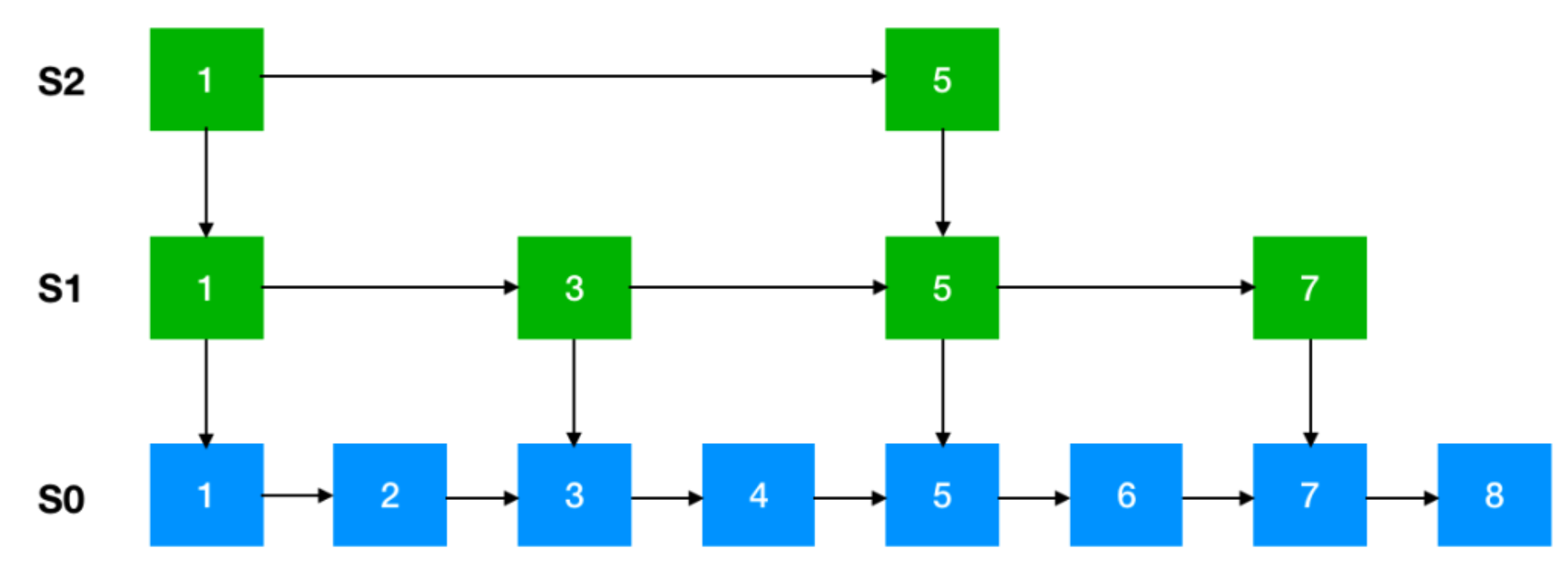
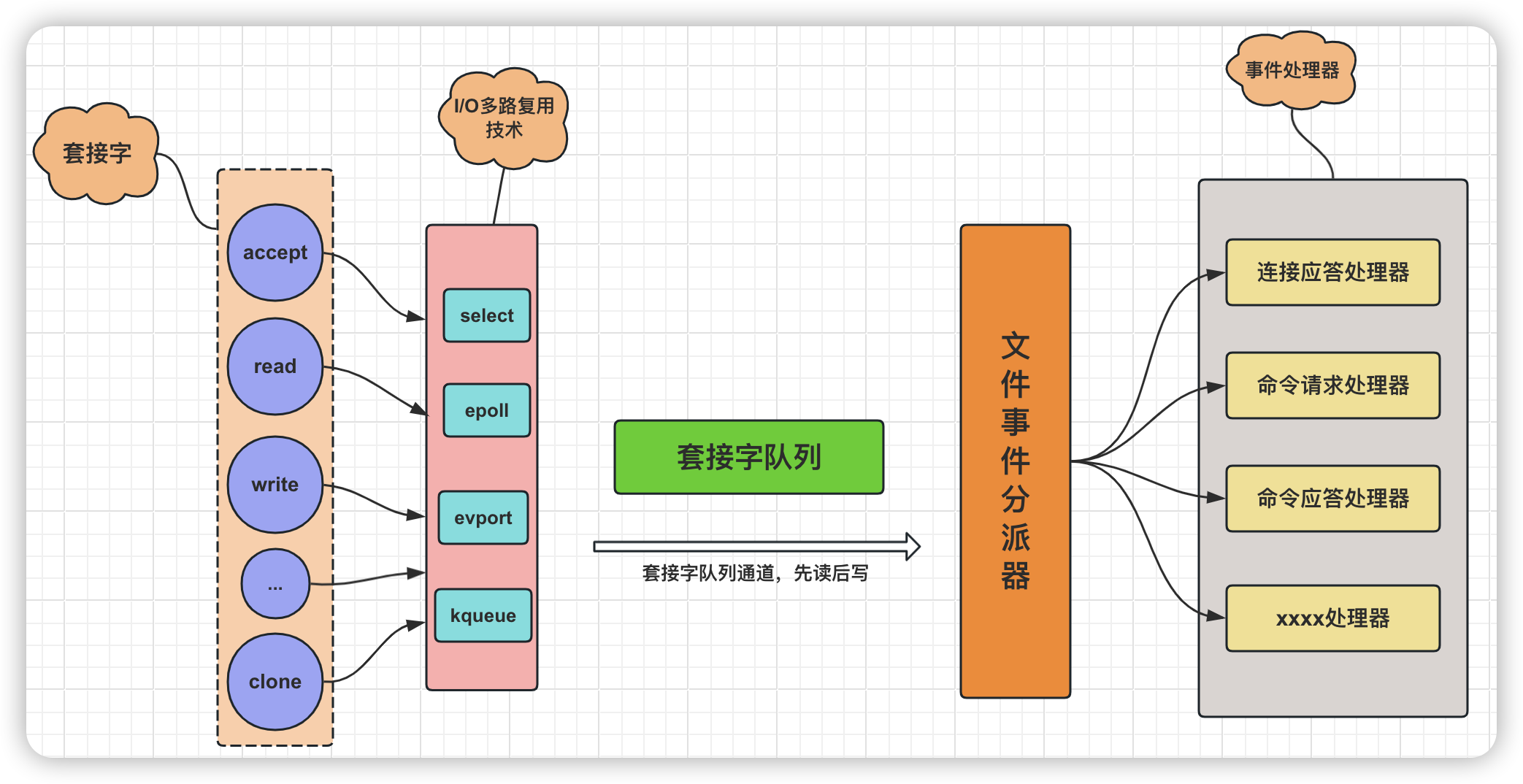
修改内存maxmemory只需要在redis.conf配置文件中配置maxmemory-policy参数即可。
在Redis 6.x版本中,固然引入了多线程处理网络IO的部分,但核心命令实行依然保持单线程事故驱动的模型,以维持Redis原有的性能优势。