
你正在午休,正梦见中了彩票,突然收到电话告警,说服务对外接口 95 分位延迟突增,惊出一身冷汗,睡意全无,抓紧打开监控体系,查看服务的 SLI 指标,发现确实有问题,已经持续 1 分钟,这服务我刚接手没多久,怎么办?怎么办??对了,告警详情里有 SOP 预案手册,赶紧打开看看。SOP 预案手册里写着:
请求某个依赖的下游服务(假设其名字是 a),发现超时了,打印了超时日记,但是无法区分是网络的问题导致的,还是就是 a 服务返回的慢了。此时,你肯定很想知道 a 服务当前是否康健,a 服务的各项 SLI 是否正常,如果 a 服务的 SLI 都正常,大概就是网络链路问题,如果 a 服务的 SLI 也不正常,那很大概就是 a 服务的问题了。但是,TMD,我不知道去哪里看 a 服务的 SLI 啊…我甚至都不知道 a 服务是否对外袒露了 SLI 指标!!!
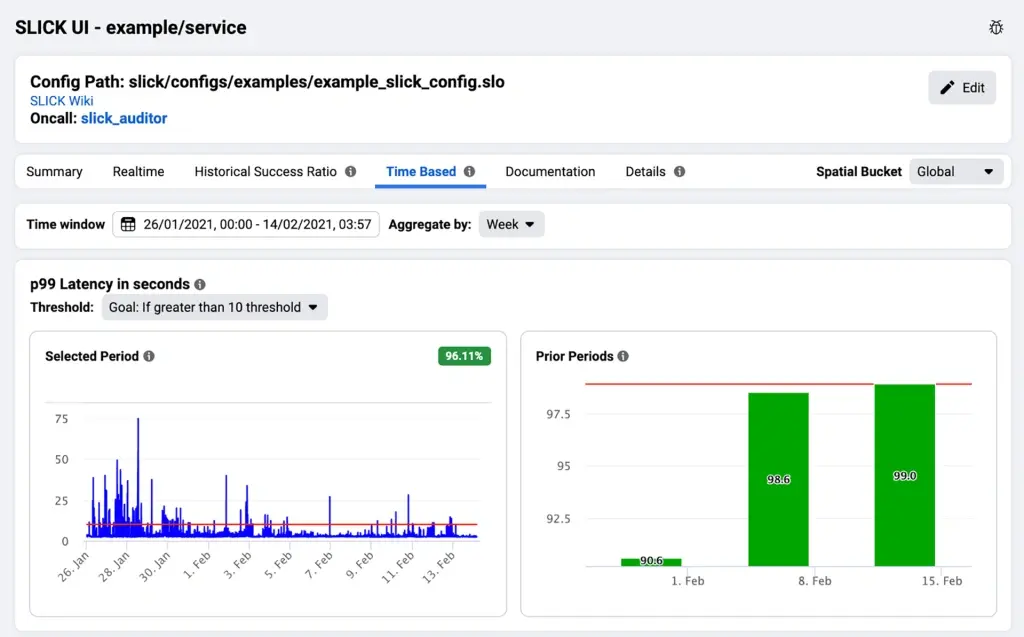
有些朋友听到需要手工配置大概就望而却步了,大可不必,让微服务负责人配置自己的服务,分布式分担这个工作,每个人就比较轻松了。而且这个信息改动极少,一般只有新服务上线或者服务下线才会改动,不会频繁改动。别的,这属于稳固性治理层面的工作,数据颠末治理才能更有价值,才能更好的服务于故障发现和定位,才能更好的反向驱动各个微服务建立这些关键数据,让整体稳固性提拔。治理工作是工程工作的放大器和矫正器。依据这个思路,我们创业建立了一个叫做灭火图的产品,来帮助公司建立这种全局 SLI 的治理。当然,灭火图除了建立上面讲到的这个能力,还可以串联 metrics、logs、traces、events 等各类可观测性数据,作为一个数据的全局入口,可以有用提拔故障发现和定位的效率。如果您有兴趣,接待联系我们交换,联系我们的邮箱即可:contact-us@flashcat.cloud ,或者到下面的网址提交一个申请,我同事会联系您约时间交换:
| 欢迎光临 IT评测·应用市场-qidao123.com技术社区 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |