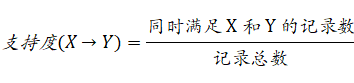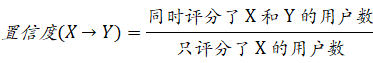支持度:
在 N 条记载中,X 和 Y 被同时满足的记载数有 n 个,那么支持度就是 n/N; 支持度计数就是 n;
在举行分析时,需要人为设置最小支持度为 m/N ,其中 m 就是最小支持度计数;
不满足最小支持度的元素组合就会被剔除;
在10个用户中,X 和 Y 同时被评分的用户数至少有 3 个,那么支持度就是 3/10,支持度计数就是 3;
进行分析时,设置最小支持度为 m/N,那最小支持度计数就是 m,不满足的产品组合就会被剔除;
复制代码
置信度:
在满足组合 X 的情况下,满足组合 Y 的概率;
也可以说是同时满足 X 和 Y 的记载数在只满足 X 的记载数的比率;
项集:
一个组合中包含几个元素,就叫做几项集。如:组合 X 为 {x1} 就叫做1项集;组合 Y 为 {Y1、Y2} 就叫做2项集; 频繁项集:
某个评分组合出现的频率大于或等于设置的支持度,那么这个评分组合就是频繁项集;
频繁项集的非空子集必须是频繁项集;
频繁项集中含有 i 个元素,就叫做频繁 i 项集。
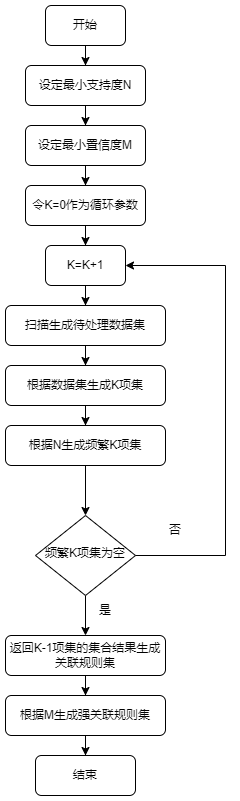
5、算法流程
6、主体代码
# -*- coding: utf-8 -*-
"""
@contact: 微信 1257309054
@file: apriori_recommend.py
@time: 2024/3/31 0:06
@author: LDC
使用Apriori关联规则实现一个频繁项集推荐算法
"""
import math
import time
def get_item_set(data):
'''
获取项的字典
:param data: 数据集
:return: 项的字典
'''
item_set = set()
for d in data:
item_set = item_set | set(d)
return item_set
def apriori(item_set, data, min_support=0.20):
'''
获取频繁项集
:param item_set: 项的字典
:param data: 数据集
:param min_support: 最小支持度,默认为0.20
:return: None
'''
# 初始化存储非频繁项集的列表
infrequent_list = []
# 初始化存储频繁项集的列表
frequent_list = []
# 初始化存储频繁项集的支持度的列表
frequent_support_list = []
# 遍历获取 n-项集
for n in range(1, len(item_set) + 1):
c = []
supports = []
if len(frequent_list) == 0:
# 计算 1-项集
for item in item_set:
items = {item}
support = calc_support(data, items)
# 如果支持度大于等于最小支持度就为频繁项集
if support >= min_support:
c.append(items)
supports.append(support)
else:
infrequent_list.append(items)
else:
# 计算 n-项集,n > 1
for last_items in frequent_list[-1]:
for item in item_set:
if item > list(last_items)[-1]:
items = last_items.copy()
items.add(item)
# 如果items的子集没有非频繁项集才计算支持度
if is_infrequent(infrequent_list, items) is False: