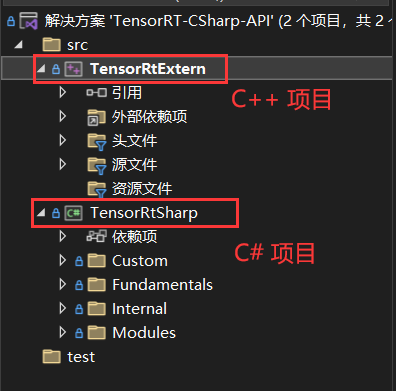
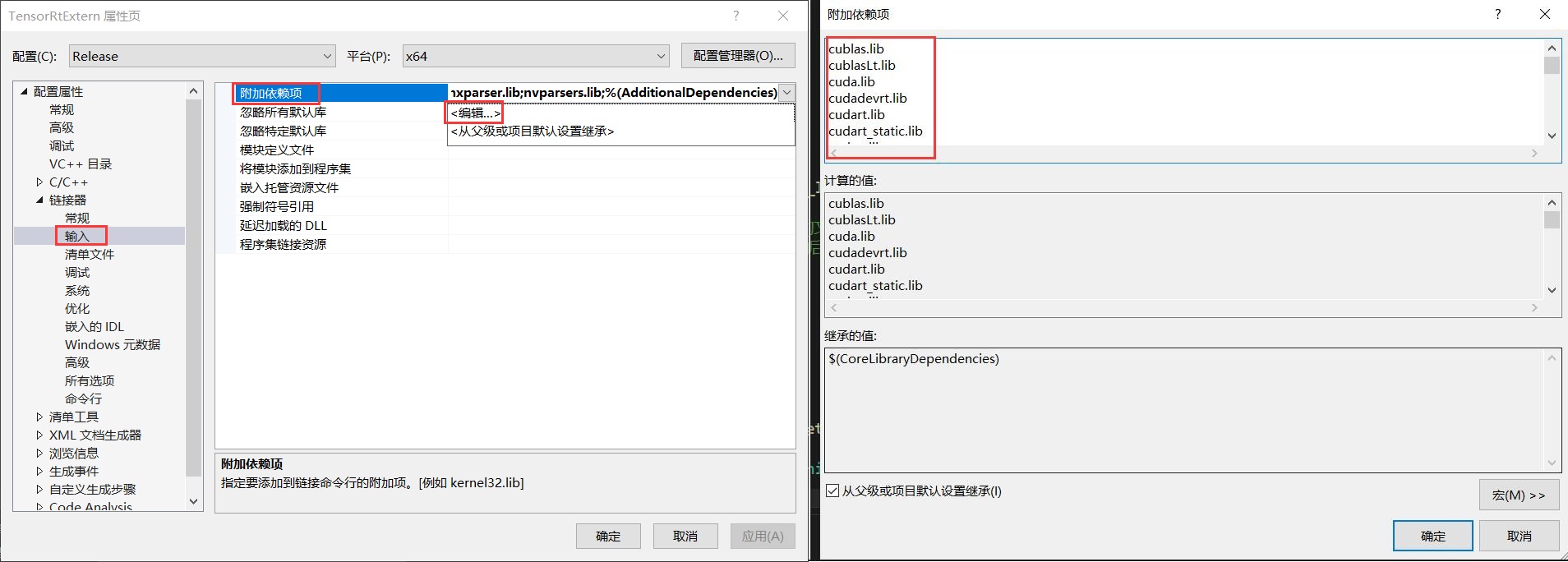
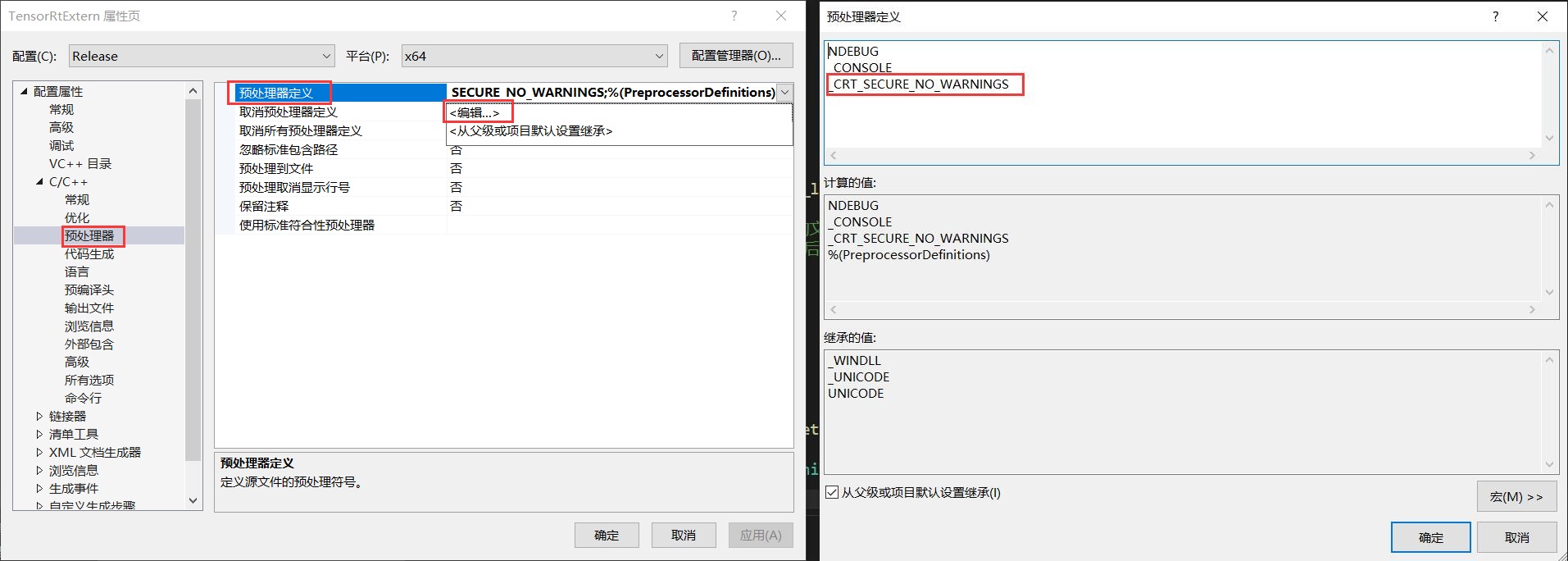
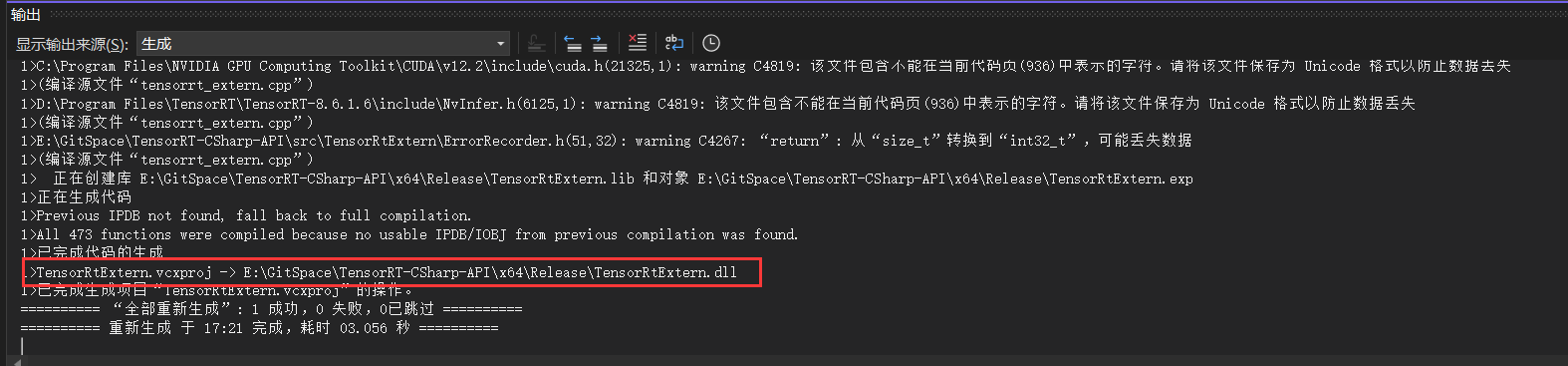
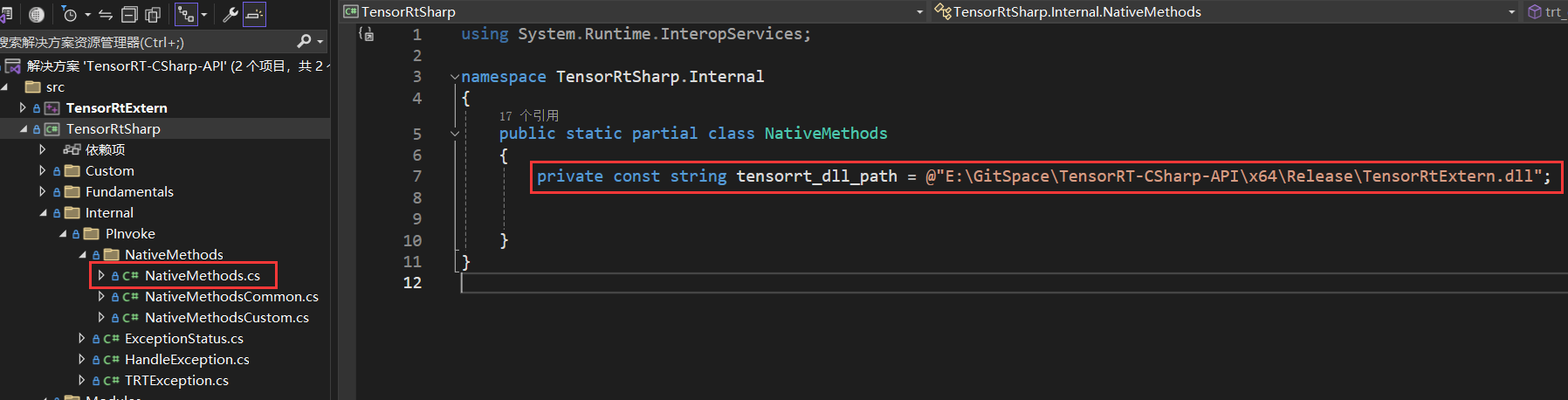
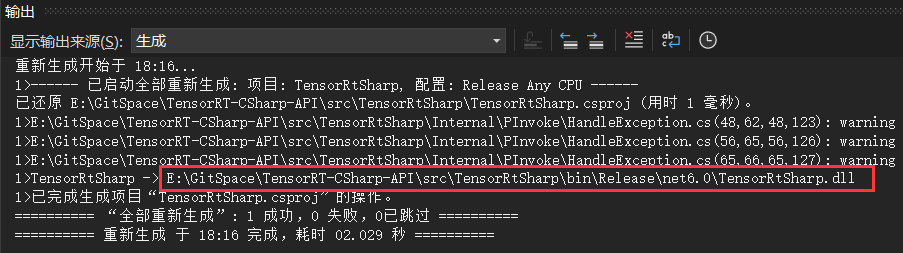
[03/31/2024-22:27:44] [I] [TRT] [MemUsageChange] TensorRT-managed allocation in engine deserialization: CPU +0, GPU +12, now: CPU 0, GPU 12 (MiB)
[03/31/2024-22:27:44] [I] [TRT] [MemUsageChange] TensorRT-managed allocation in IExecutionContext creation: CPU +0, GPU +4, now: CPU 0, GPU 16 (MiB)
[03/31/2024-22:27:44] [W] [TRT] CUDA lazy loading is not enabled. Enabling it can significantly reduce device memory usage and speed up TensorRT initialization. See "Lazy Loading" section of CUDA documentation https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#lazy-loading
[ INFO ] Input image data processing time: 6.6193 ms.
[ INFO ] Model inference time: 1.1434 ms.
[ INFO ] Classification Top 10 result :
[ INFO ] classid probability
[ INFO ] ------- -----------
[ INFO ] index: 386 score: 0.87328124
[ INFO ] index: 385 score: 0.082506955
[ INFO ] index: 101 score: 0.04416279
[ INFO ] index: 51 score: 3.5818E-05
[ INFO ] index: 48 score: 4.2115275E-06
[ INFO ] index: 354 score: 3.5188648E-06
[ INFO ] index: 474 score: 5.789438E-07
[ INFO ] index: 490 score: 5.655325E-07
[ INFO ] index: 343 score: 5.1091644E-07
[ INFO ] index: 340 score: 4.837259E-07
[ INFO ] Classification Top 10 result :
[ INFO ] classid probability
[ INFO ] ------- -----------
[ INFO ] index: 293 score: 0.89423335
[ INFO ] index: 276 score: 0.052870292
[ INFO ] index: 288 score: 0.021361532
[ INFO ] index: 290 score: 0.009259541
[ INFO ] index: 275 score: 0.0066174944
[ INFO ] index: 355 score: 0.0025512716
[ INFO ] index: 287 score: 0.0024535337
[ INFO ] index: 210 score: 0.00083151844
[ INFO ] index: 184 score: 0.0006893527
[ INFO ] index: 272 score: 0.00054959994
复制代码
通过上面输出可以看出,模子推理仅需1.1434ms,大大提拔了模子的推理速率。
5. 总结
在本项目中,我们开辟了TensorRT C# API 2.0版本,重新封装了推理接口。并联合分类模子部署流程向各人展示了TensorRT C# API 的使用方式,方便各人快速上手使用。
为了方便各位开辟者使用,此处开辟了配套的演示项目,重要是基于Yolov8开辟的目标检测、目标分割、人体关键点识别、图像分类以及旋转目标识别,由于时间原因,还未开辟配套的技能文档,此处先行提供给各人项目源码,各人可以根据自己需求使用: