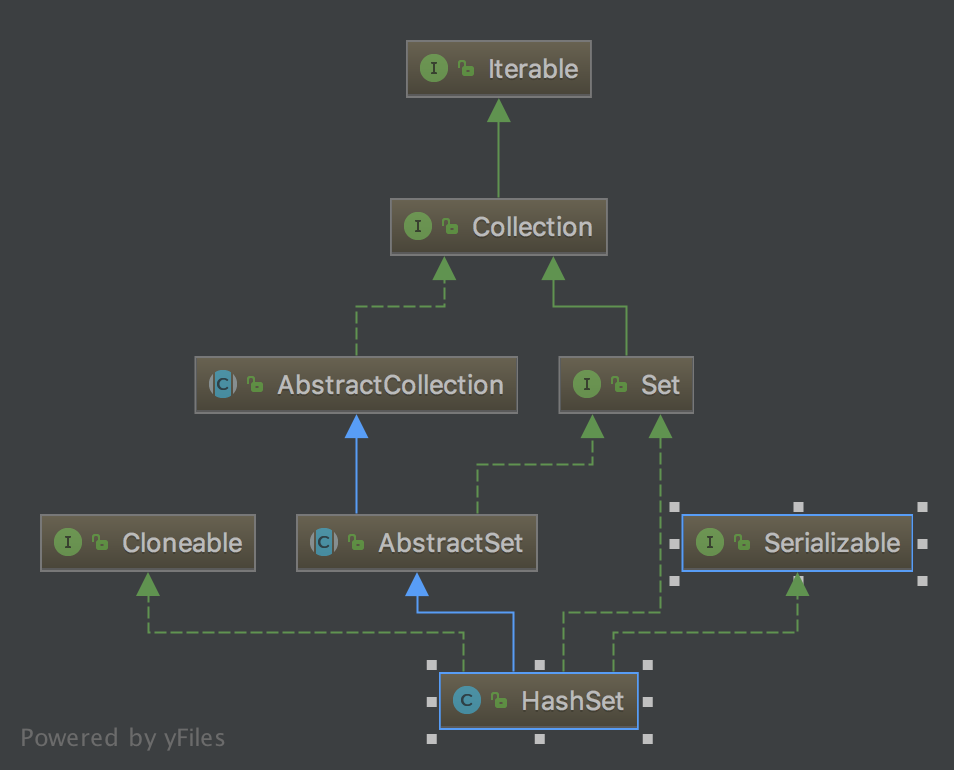
- HashSet 实现了 Set 接口
- HashSet 底层实际上是由 HashMap 实现的
- 可以存放 null,但是只能有一个 null
- HashSet 不保证元素是有序的(即不保证存放元素的顺序和取出元素的顺序一致),取决于 hash 后,再确定索引的结果
HashSet 底层机制说明
- 不能有重复的元素
HashSet 底层是 HashMap,HashMap 底层是 数组 + 链表 + 红黑树模拟数组+链表的结构
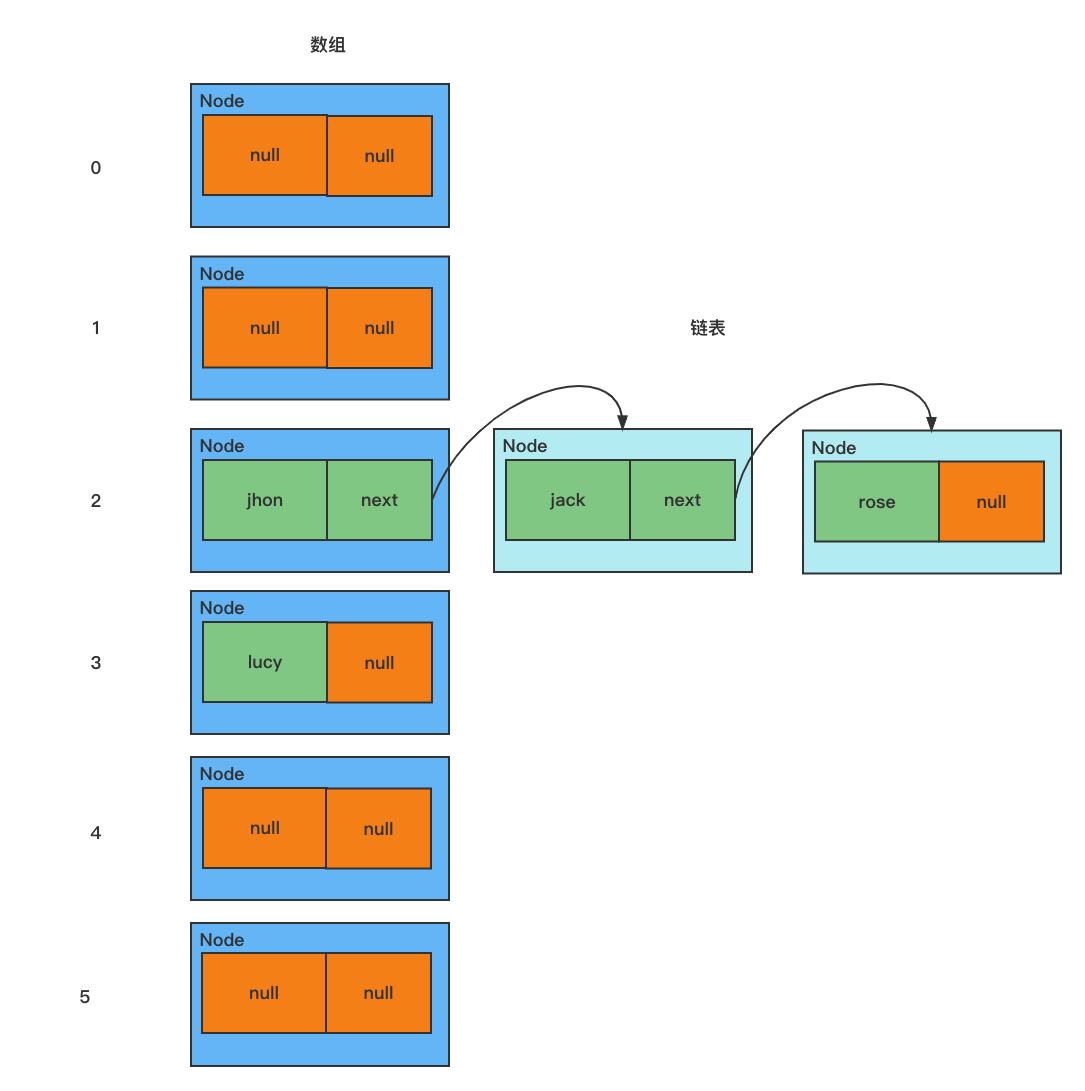
- HashSet 底层是 HashMap
- 当添加一个元素时,会先得到 待添加元素的 hash 值,然后将其转换成一个 索引值
- 查询存储数据表(Node 数组) table,看当前 待添加元素 所对应的 索引值 的位置是否已经存放了 其它元素
- 如果当前 索引值 所对应的的位置不存在 其它元素,就将当前 待添加元素 放到这个 索引值 所对应的的位置
HashSet 扩容机制
- 如果当前 索引值 所对应的位置存在 其它元素,就调用 待添加元素.equals(已存在元素) 比较,结果为 true,则放弃添加;结果为 false,则将 待添加元素 放到 已存在元素 的后面(已存在元素.next = 待添加元素)
- HashSet 的底层是 HashMap,第一次添加元素时,table 数组扩容到 cap = 16,threshold(临界值) = cap * loadFactor(加载因子 0.75) = 12
- 如果 table 数组使用到了临界值 12,就会扩容到 cap * 2 = 32,新的临界值就是 32 * 0.75 = 24,以此类推
- 在 Java8 中,如果一条链表上的元素个数 到达 TREEIFY_THRESHOLD(默认是 8),并且 table 的大小 >= MIN_TREEIFY_CAPACITY(默认是 64),就会进行 树化(红黑树)
HashSet 添加元素源码
- 判断是否扩容是根据 ++size > threshold,即是否扩容,是根据 HashMap 所存的元素个数(size)是否超过临界值,而不是根据 table.length() 是否超过临界值
| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |