挖矿的目的是什么?通过挖矿,可以欺凌性保证块链中的数据按时间序次存储,保持比特币网络的中立性,且允许比特币网络上不同的计算机对体系状态达成一致。交易要得到确认,必须要被打包到一个符合非常严格的密码学规则的区块中,并通过比特币网络举行验证。这些规则可以防止对已有块的修改,因为一旦有改动,之后所有的块都将失效。挖矿的难度和中彩票相当,没人可以轻易地、一连地将新块加入到块链中。因此,没有集体和个人可以控制块链中包含什么样的内容大概更换掉块链中的部分内容以到达打消他们交易的目的。这就是一个到达共识的过程,网络中的节点通过共识机制来验证和记载新的交易,常见的共识机制包括工作量证实(PoW)和权益证实(PoS)。
为什么需要构造coinbase信息?coinbase交易的存在是网络共识算法的一部分,coinbase交易是每个新区块中的第一个交易,它确认了区块的创建和挖矿过程的乐成。在挖矿过程中,矿工需要找到一个特定的哈希值,就修改coinbase交易中的Nonce字段并重新计算区块哈希。
为什么是Merkle根?Merkle树(也称为二叉哈希树)是一种数据结构,从区块内所有交易的哈希值开始构建,将这些哈希值配对,然后计算每个配对的哈希值,形成第二层。这个过程递归地重复,直到生成单个哈希值,即Merkle根(Merkle Root)。Merkle树允许通过Merkle证实快速验证区块中单个交易的存在性,任何对树中数据的更改都会导致Merkle根的变革。

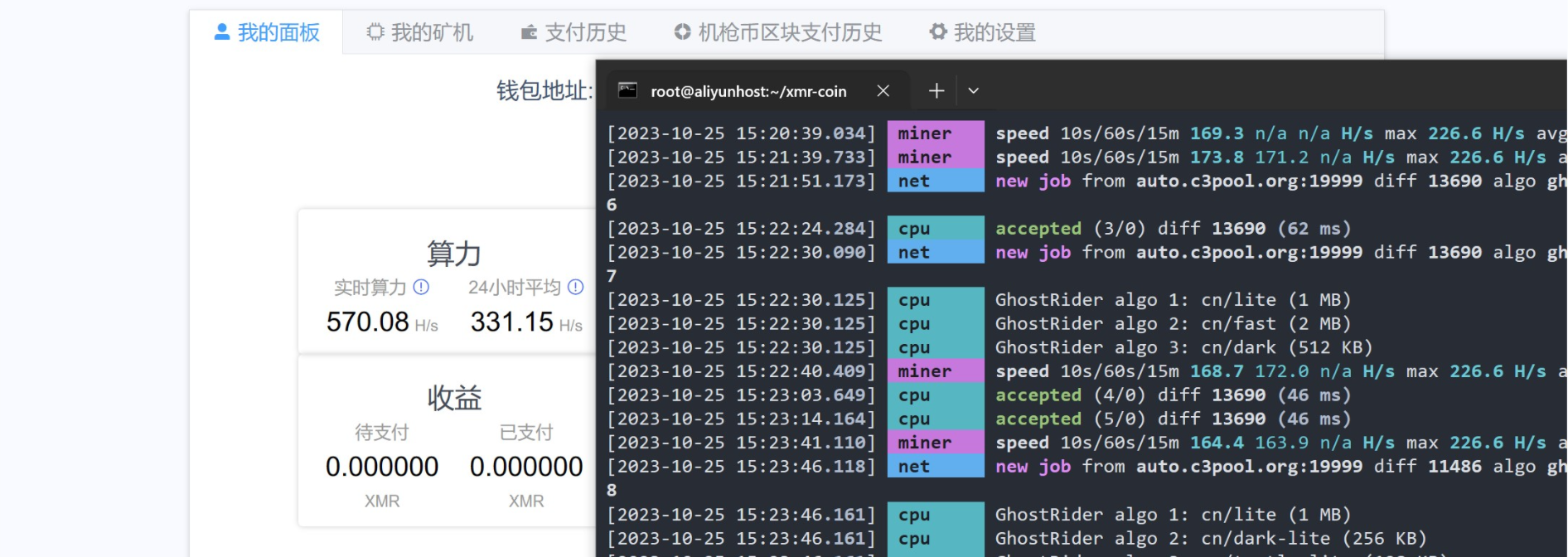
注意:本地挖矿需要比较好的网络情况,需要自己准备梯子。流量分析
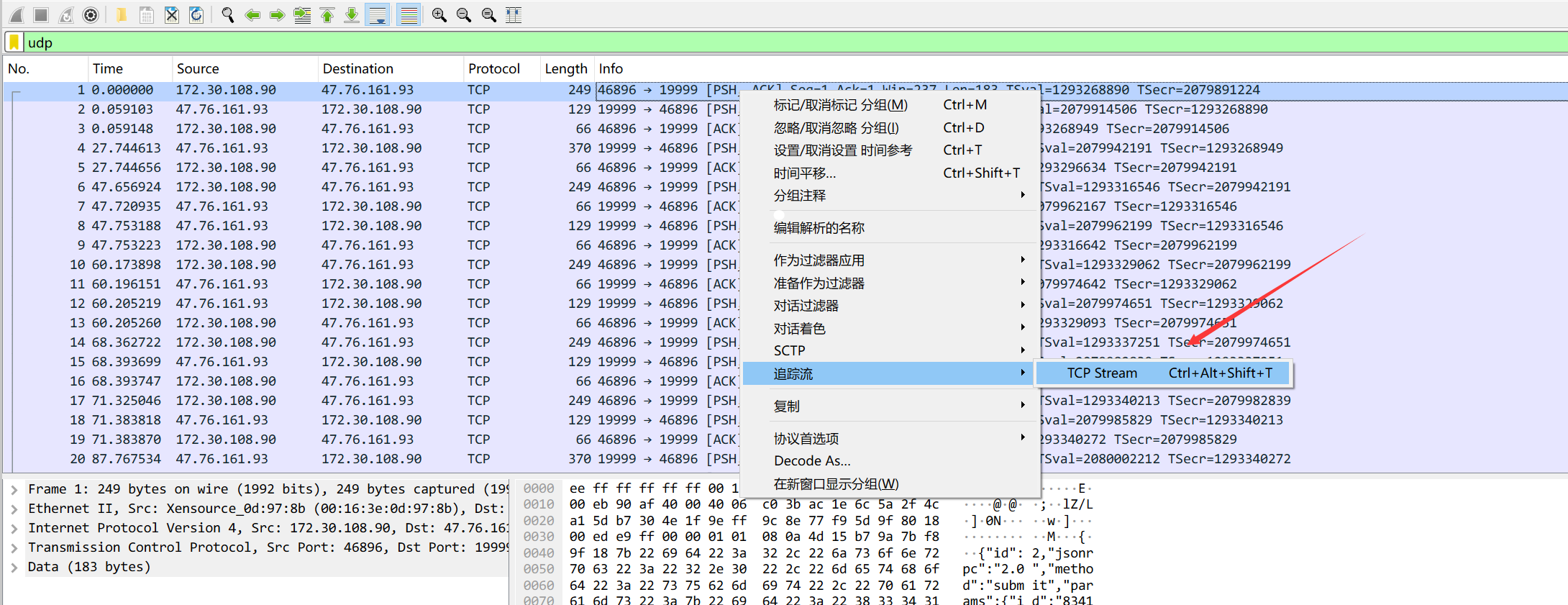
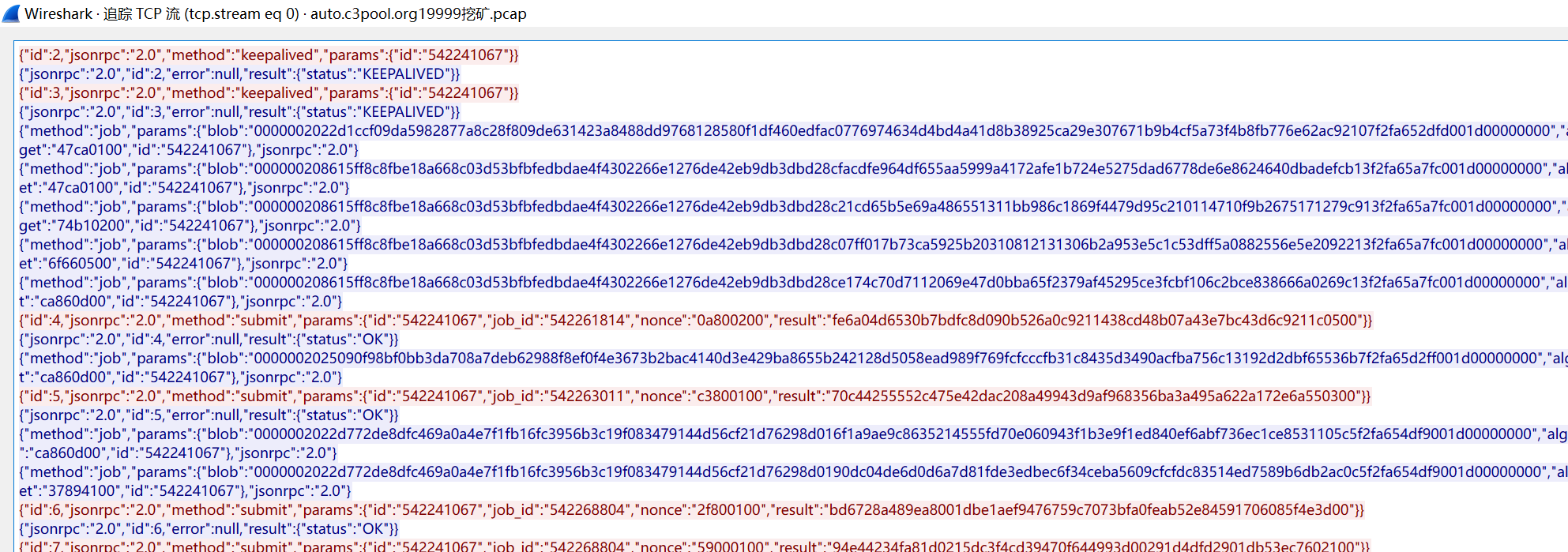
参考文章:若有错误,欢迎指正!o( ̄▽ ̄)ブ
https://en.bitcoin.it/wiki/Stratum_mining_protocol#Protocol
https://github.com/pangsitao/slush_stratum_protocol_zhCN/blob/master/main.md#Stratum协议
https://docs.google.com/document/d/17zHy1SUlhgtCMbypO8cHgpWH73V5iUQKk_0rWvMqSNs/edit?hl=en_US
https://zhuanlan.zhihu.com/p/571589377
https://www.freebuf.com/articles/network/195171.html
https://www.yuameshi.top/2021/05/termux-xmrig/
| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |