Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。1)Kafka的特性
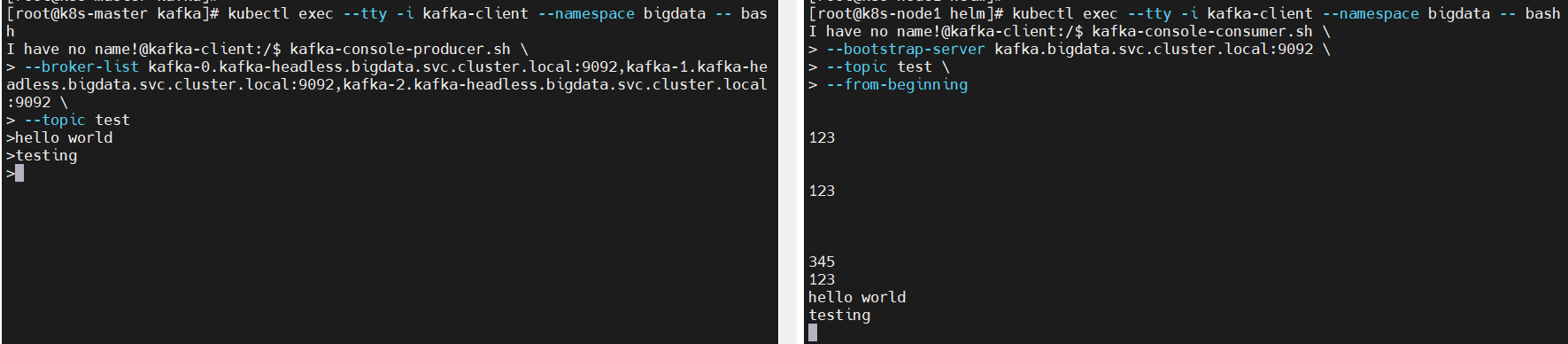
Kafka中发布订阅的对象是topic。我们可以为每类数据创建一个topic,把向topic发布消息的客户端称作producer,从topic订阅消息的客户端称作consumer。Producers和consumers可以同时从多个topic读写数据。一个kafka集群由一个或多个broker服务器组成,它负责持久化和备份具体的kafka消息。
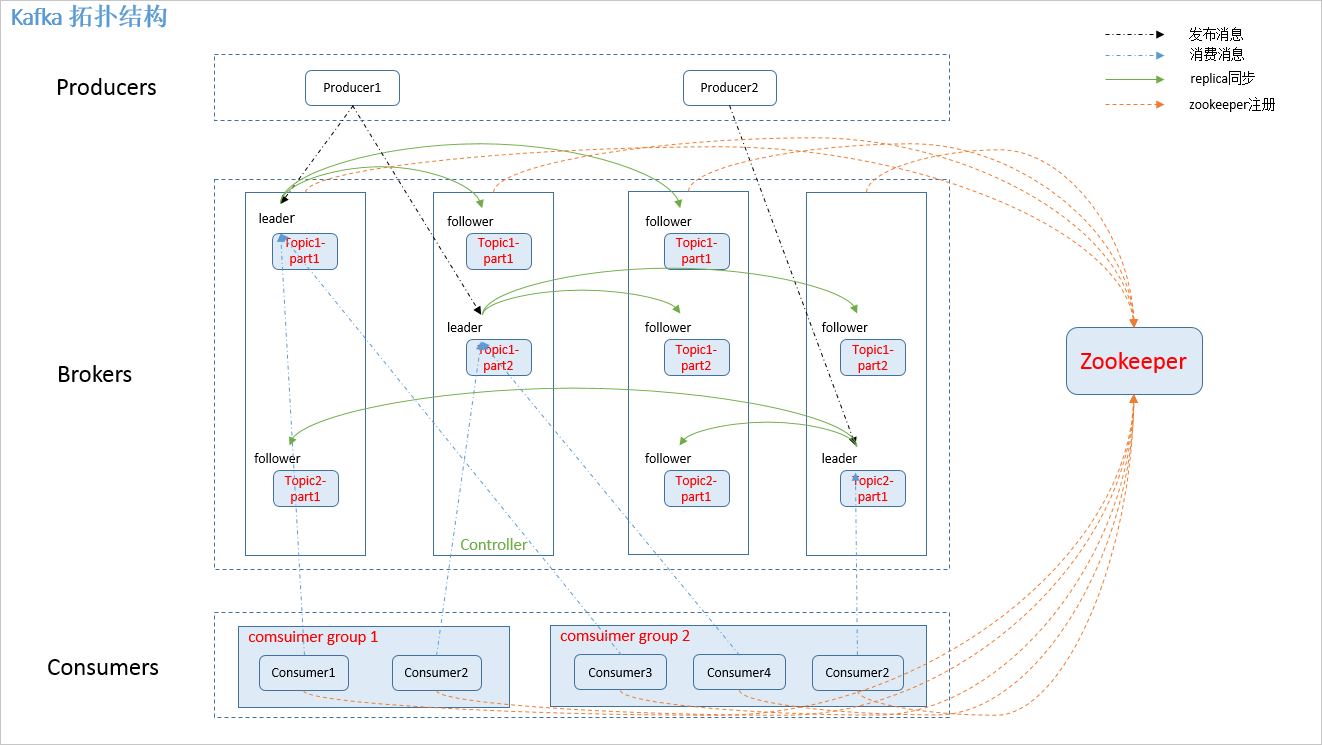
zookeeper 是 kafka 不可分割的一部分。接下来就来讲讲zookeeper在kafka中作用。1)记录和维护broker状态
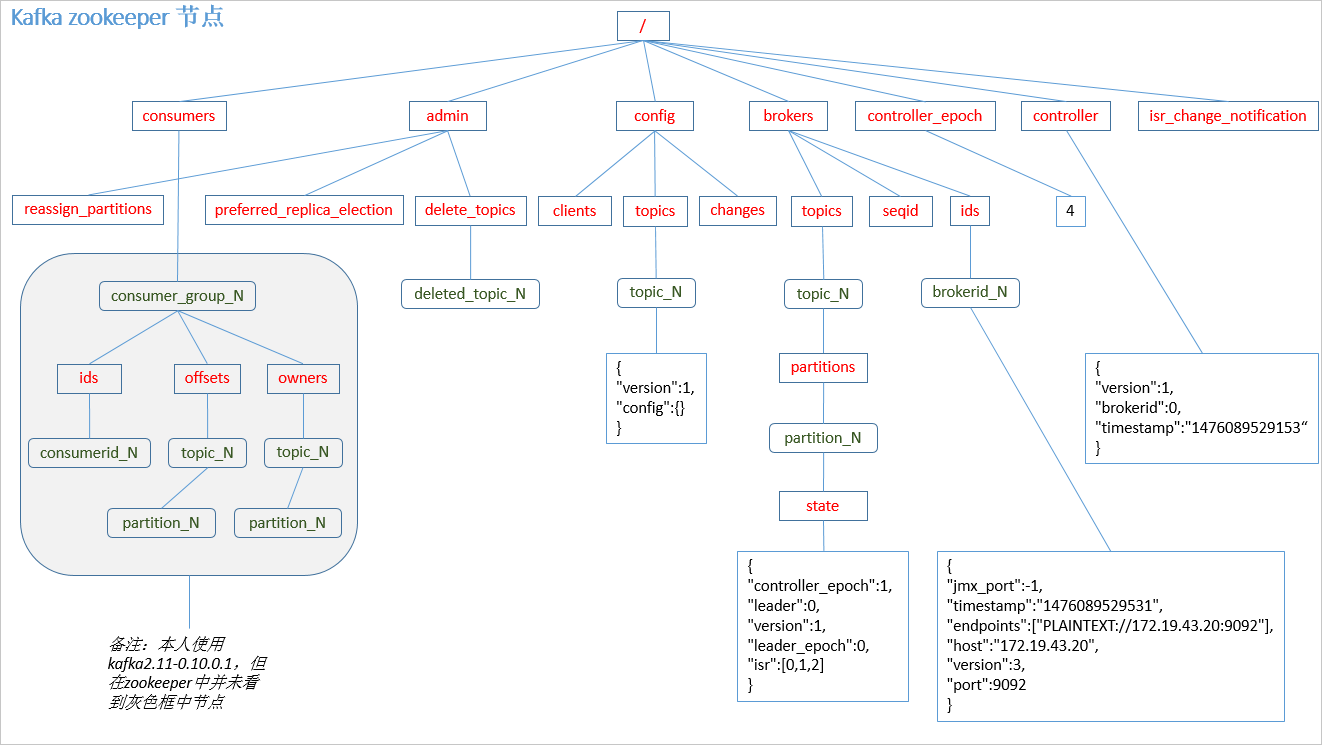
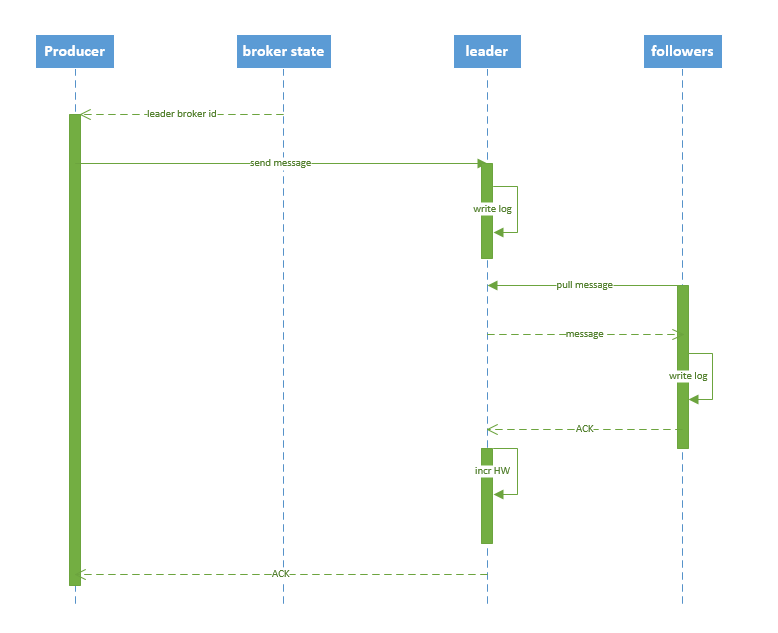
所谓控制器就是一个Borker,在一个kafka集群中,有多个broker节点,但是它们之间需要选举出一个leader,其他的broker充当follower角色。集群中第一个启动的broker会通过在zookeeper中创建临时节点/controller来让自己成为控制器,其他broker启动时也会在zookeeper中创建临时节点,但是发现节点已经存在,所以它们会收到一个异常,意识到控制器已经存在,那么就会在zookeeper中创建watch对象,便于它们收到控制器变更的通知。
在kafka的集群中,会存在着多个主题topic,在每一个topic中,又被划分为多个partition,为了防止数据不丢失,每一个partition又有多个副本,在整个集群中,总共有三种副本角色:
默认的,如果follower与leader之间超过10s内没有发送请求,或者说没有收到请求数据,此时该follower就会被认为“不同步副本”。而持续请求的副本就是“同步副本”,当leader发生故障时,只有“同步副本”才可以被选举为leader。其中的请求超时时间可以通过参数replica.lag.time.max.ms参数来配置。
我们希望每个分区的leader可以分布到不同的broker中,尽可能的达到负载均衡,所以会有一个优先leader,如果我们设置参数auto.leader.rebalance.enable为true,那么它会检查优先leader是否是真正的leader,如果不是,则会触发选举,让优先leader成为leader。3)消费组(consumer group)选举机制
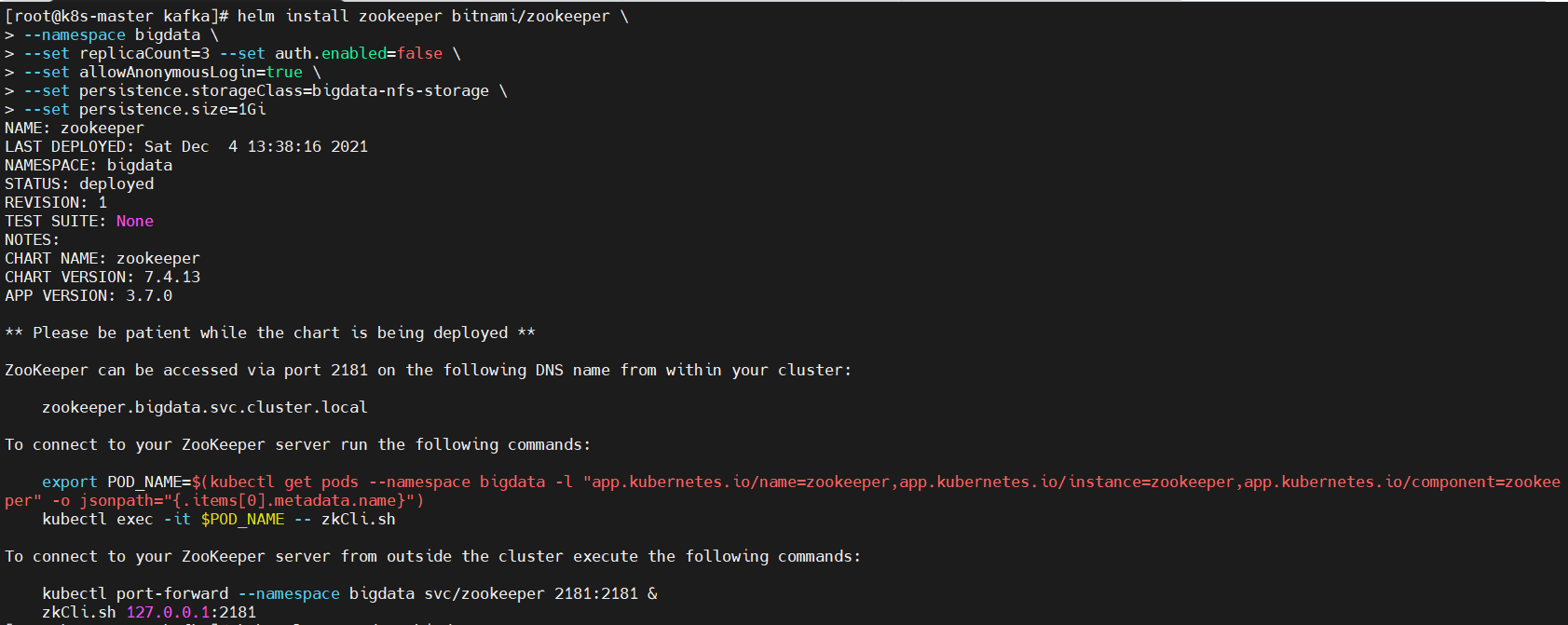
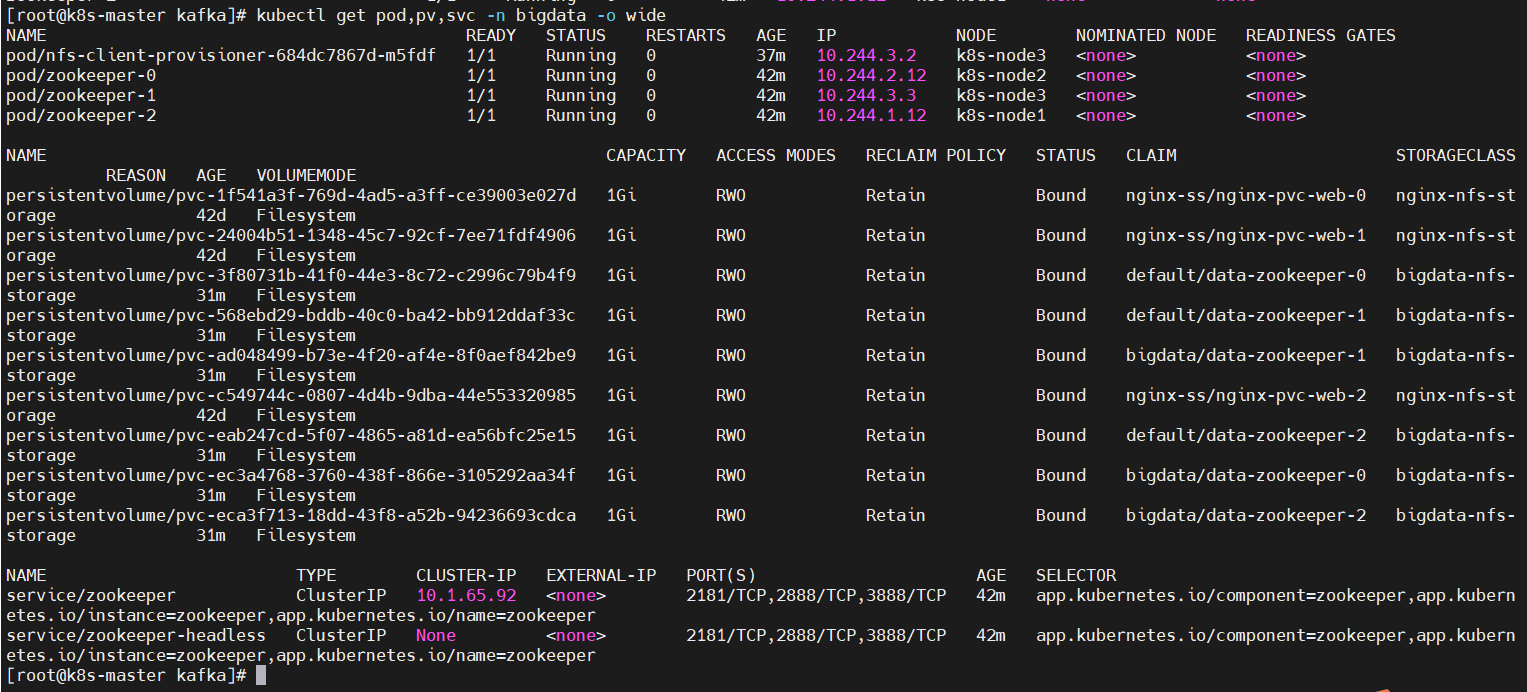
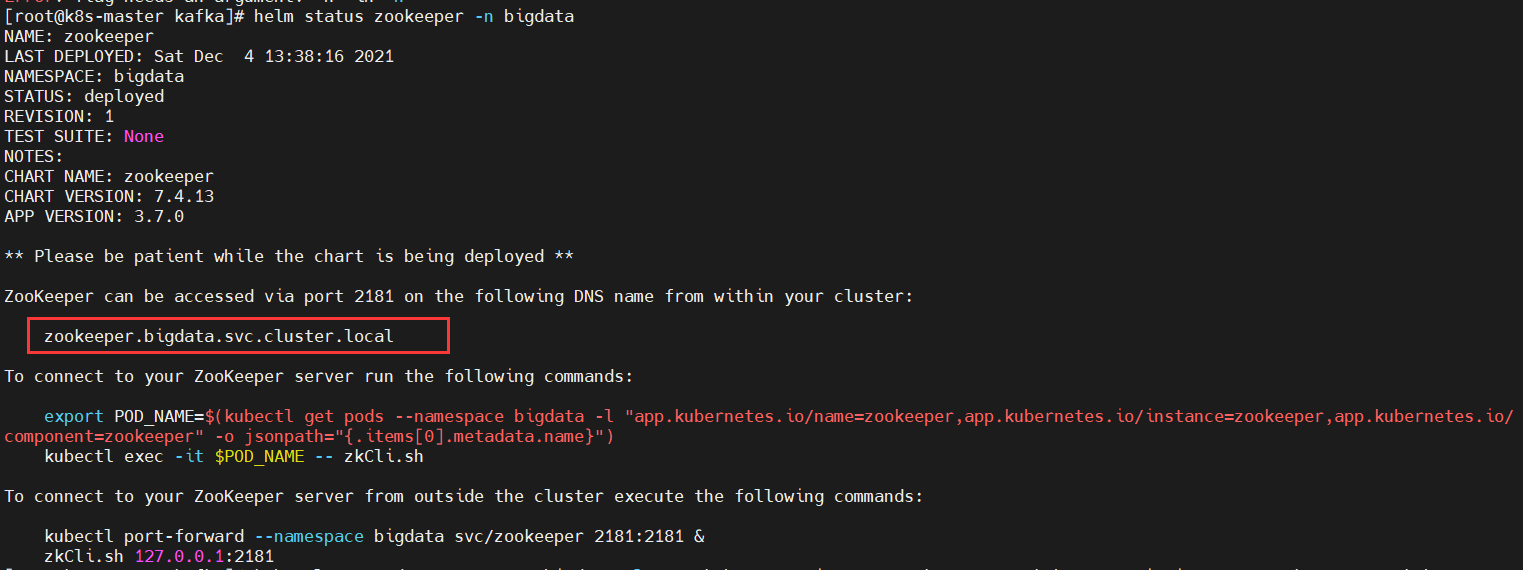
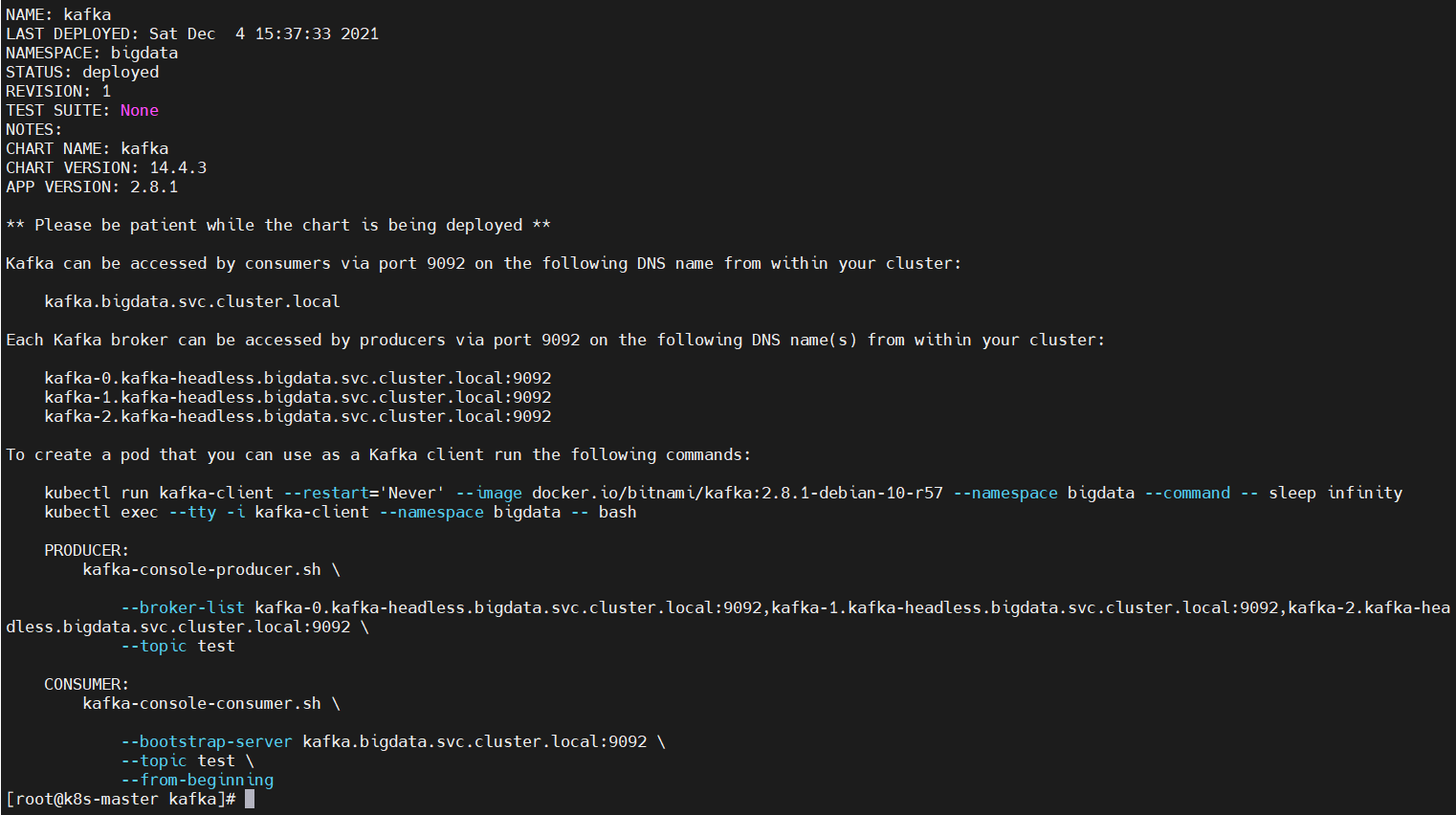
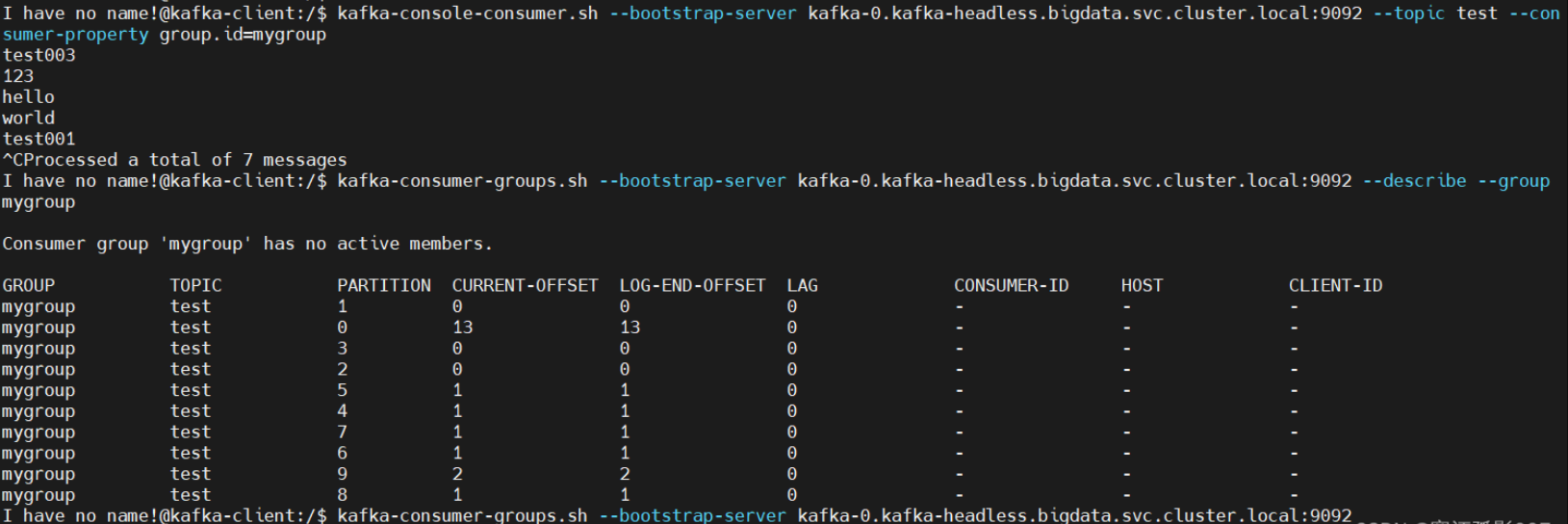
组协调器会为消费组(consumer group)内的所有消费者选举出一个leader,这个选举的算法也很简单,第一个加入consumer group的consumer即为leader,如果某一时刻leader消费者退出了消费组,那么会重新 随机 选举一个新的leader。六、kubernetes(k8s) helm3安装zookeeper、kafka
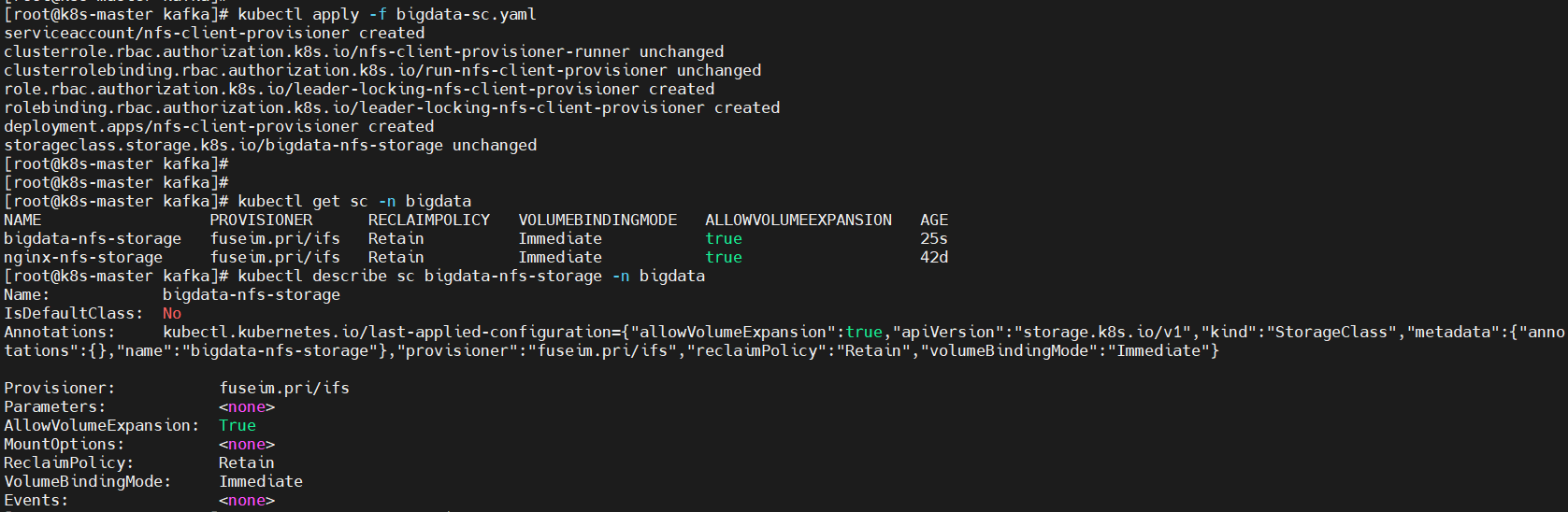


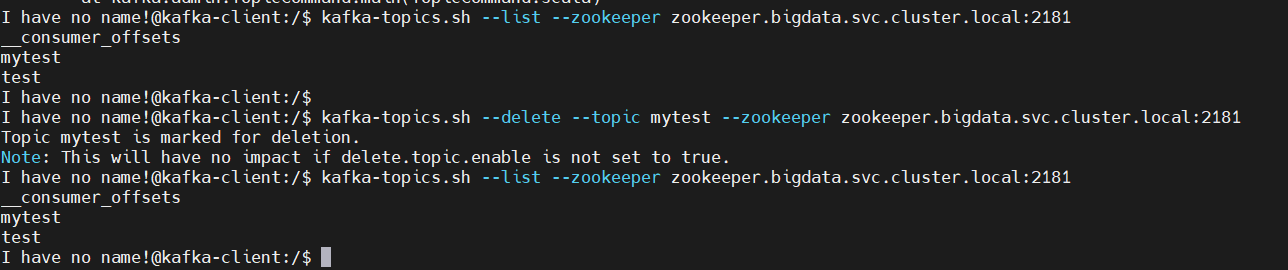
Note: This will have no impact if delete.topic.enable is not set to true.## 默认情况下,删除是标记删除,没有实际删除这个Topic;如果运行删除Topic,两种方式:
kafka默认的只保存7天的数据,时间一到就删除数据,当遇到磁盘过小,存放的数据量过大,可以设置缩短这个时间。



| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |