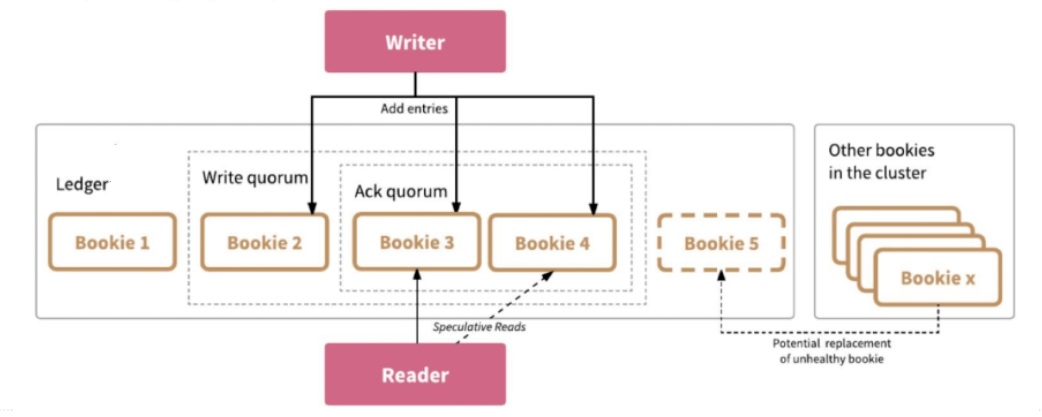
| 字段 | Java 类型 | 说明 |
| Ledger number | long | Ledger ID |
| Entry number | long | Entry ID |
| Last confirmed (LC) | long | 末了提交的 Entry ID |
| Data | byte[] | entry 的数据 |
| Authentication code | byte[] | 消息认证码,包罗 entry 中的所有其他字段 |
| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |