当然,引入本地缓存也会有相应的问题,比方说:
本地缓存的实时性怎么保证?
方案一,可以引入消息队列。在数据更新时,发布数据更新的消息;而进>程中有相应的消费者消费该消息,从而更新本地缓存。
方案二,设置较短的过期时间,请求时从 DB 重新拉取。
方案三,手动过期。
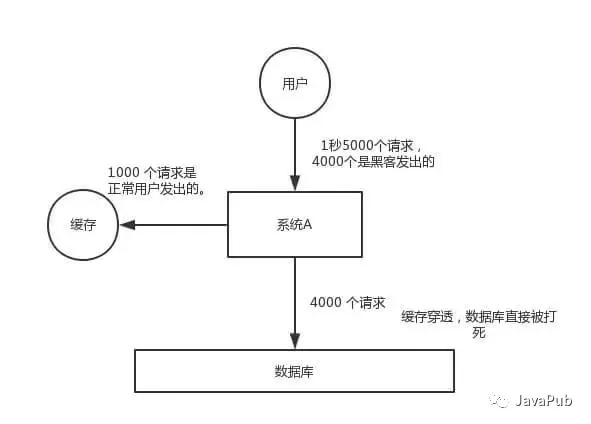
重要指的是,更新 DB 数据之前,先删除 Cache 的数据。在低并发量下没什么问题,但是在高并发下,就会存在问题。在(删除 Cache 的数据, 和更新 DB 数据)时间之间,恰好有一个请求,我们如果利用被动读,因为此时 DB 数据还是老的,又会将老的数据写入到 Cache 中。
Docker Compose 是一个用来界说和运行复杂应用的Docker工具。一个利用Docker容器的应用,通常由多个容器构成。利用Docker Compose不再需要利用shell脚本来启动容器。Compose 通过一个设置文件来管理多个Docker容器。简单理解:Docker Compose 是docker的管理工具。Docker Compose 在继续下一个容器之前不会等待容器准备就绪。为了控制我们的执行顺序,我们可以利用“取决于”条件,depends_on 。这是在 docker-compose.yml 文件中利用的示例
命令发起在本地安装做一个实操,记忆会更深刻。
也可以克隆基于docker的俩万(springboot+vue)项目练手,提供视频+完善文档。地址:https://gitee.com/rodert/liawan-vue
这是一道涉猎很广泛的标题,理解性阅读。Linux中的PID、IPC、网络等资源是全局的,而Linux的NameSpace机制是一种资源隔离方案,在该机制下这些资源就不再是全局的了,而是属于某个特定的NameSpace,各个NameSpace下的资源互不干扰。
强烈发起大家实操,才能更好的理解docker。低谷蓄力
ElasticSearch 的选主是 ZenDiscovery 模块负责,源码分析将首发在。 https://gitee.com/rodert/JavaPub

shard = hash(document_id) % (num_of_primary_shards)
4. 具体描述一下 Elasticsearch 搜刮的过程?
- Lucene 索引是由多个段构成,段本身是一个功能齐全的倒排索引。
- 段是不可变的,允许 Lucene 将新的文档增量地添加到索引中,而不消从头重修索引。
- 对于每一个搜刮请求而言,索引中的全部段都会被搜刮,并且每个段会斲丧CPU 的时钟周、文件句柄和内存。这意味着段的数目越多,搜刮性能会越低。
- 为了解决这个问题,Elasticsearch 会合并小段到一个较大的段,提交新的合并段到磁盘,并删除那些旧的小段。
es作为一个分布式的存储和检索体系,每个文档根据 _id 字段做路由分发被转发到对应的shard上。搜刮执行阶段过程分俩个部分,我们称之为 Query Then Fetch。


原因:大多数操作体系会将内存利用到文件体系缓存,会将应用程序未用到的内存交换出去。会导致jvm的堆内存交换到磁盘上。交换会导致性能问题。会导致内存垃圾回收延伸。会导致集群节点相应时间变慢,或者从集群停止开。
https://www.elastic.co/cn/blog/how-to-design-your-elasticsearch-data-storage-architecture-for-scale#raid566. Elasticsearch 中的节点(比如共 20 个),其中的 10 个选了一个 master,别的 10 个选了另一个 master,怎么办?
这道标题较难,相信大家看到许多类似这种回答Elasticsearch 提供的首个近似聚合是cardinality 度量。它提供一个字段的基数,即该字段的distinct或者unique值的数目。它是基于HLL算法的。HLL 会先对我们的输入作哈希运算,然后根据哈希运算的结果中的 bits 做概率估算从而得到基数。其特点是:可设置的精度,用来控制内存的利用(更准确 = 更多内存);小的数据集精度黑白常高的;我们可以通过设置参数,来设置去重需要的固定内存利用量。无论数千还是数十亿的唯一值,内存利用量只与你设置的准确度相干。
首先要了解什么是同等性,在分布式体系中,我们一般通过CPA理论分析。分布式体系不可能同时满足同等性(C:Consistency)、可用性(A:Availability)和分区容忍性(P:Partition Tolerance),最多只能同时满足其中两项。

如果你没有许多实战经验,可以基于 word2vec 做一些练习,我的博客提供了 word2vec Java版的一些Demo。基于 word2vec 和 Elasticsearch 实现个性化搜刮,它有以下优点:
自动装箱 ----- 基本类型的值 → 包装类的实例
自动拆箱 ----- 基本类型的值 ← 包装类的实例

| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |