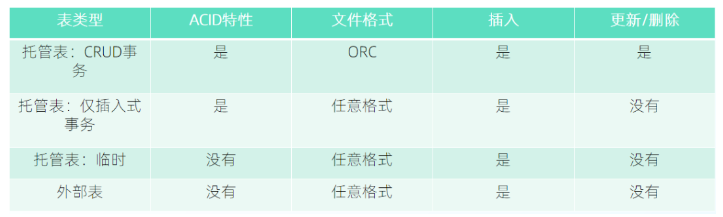
a、1-3 位:编码版本,当前是 001;
b、4 位:保留;
c、5-16 位:分桶 ID,由 0 开始。分桶 ID 是由 CLUSTERED BY 子句所指定的字段、以及分桶的数量决定的。该值和 bucket_N 中的 N 一致;
d、17-20 位:保留;
e、21-32 位:语句 ID;
举例来说,整型 536936448 的二进制格式为 00100000000000010000000000000000,即它是按版本 1 的格式编码的,分桶 ID 为 1。
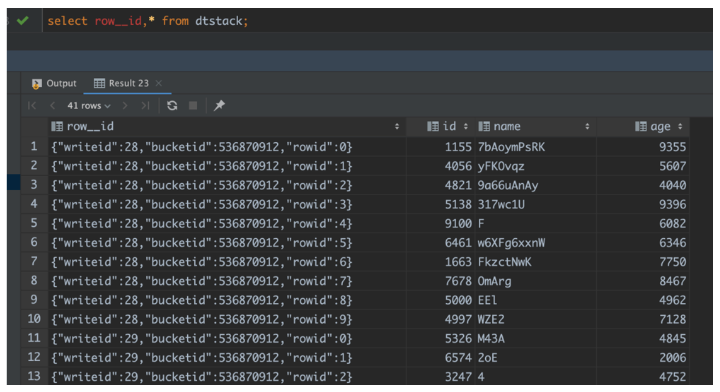
rowId 是一个自增的唯一 ID,在写事务和分桶的组合中唯一;
currentTransaction 当前的写事务 ID;
row 具体数据。对于 DELETE 语句,则为 null。
3、更新 Hive 事务表数据
UPDATE employee SET age = 21 WHERE id = 2;
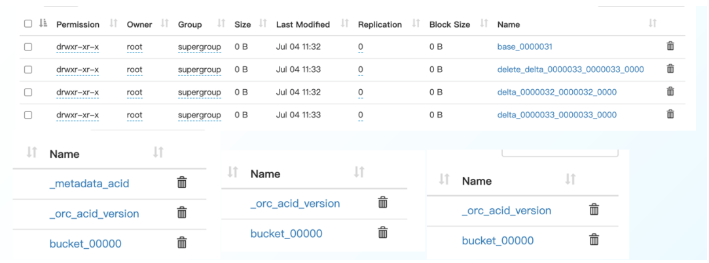
这条语句会先查询出所有符合条件的记录,获取它们的 row_id 信息,然后分别创建 delete 和 delta 目录:
/user/hive/warehouse/employee/delta_0000001_0000001_0000/bucket_00000
/user/hive/warehouse/employee/delete_delta_0000002_0000002_0000/bucket_00000 (update)
/user/hive/warehouse/employee/delta_0000002_0000002_0000/bucket_00000 (update)
delete_delta_0000002_0000002_0000/bucket_00000
包含了删除的记录:
{"operation":2,"originalTransaction":1,"bucket":536870912,"rowId":1,"currentTransaction":2,"row":null}
delta_0000002_0000002_0000/bucket_00000
包含更新后的数据:
{"operation":0,"originalTransaction":2,"bucket":536870912,"rowId":0,"currentTransaction":2,"row":{"id":2,"name":"Tom","salary":21}}
4、Row_ID 信息怎么查?
5、事务表压缩(Compact)
随着写操作的积累,表中的 delta 和 delete 文件会越来越多,事务表的读取过程中需要合并所有文件,数量一多势必会影响效率,此外小文件对 HDFS 这样的文件系统也不够友好,因此Hive 引入了压缩(Compaction)的概念,分为 Minor 和 Major 两类。
● Minor
Minor Compaction 会将所有的 delta 文件压缩为一个文件,delete 也压缩为一个。压缩后的结果文件名中会包含写事务 ID 范围,同时省略掉语句 ID。
压缩过程是在 Hive Metastore 中运行的,会根据一定阈值自动触发。我们也可以使用如下语句人工触发:
ALTER TABLE dtstack COMPACT 'MINOR'。
● Major
Major Compaction 会将所有的 delta 文件,delete 文件压缩到一个 base 文件。压缩后的结果文件名中会包含所有写事务 ID 的最大事务 ID。
压缩过程是在 Hive Metastore 中运行的,会根据一定阈值自动触发。我们也可以使用如下语句人工触发:
ALTER TABLE dtstack COMPACT 'MAJOR'。
6、文件内容详解