怎么个舍弃法呢?我们先得看一下访问雷同数据的事件在不包管串行执行(也就是执行完一个再执行另一个)的环境下大概会出现哪些题目: 脏写(Dirty Write): 假如一个事件修改了另一个未提交事件修改过的数据,那就意味着发生了脏写,示意图如下:
Session ASession B1BEGIN;2BEGIN;3UPDATE hero SET name = ‘赵云’ WHERE number = 1;4UPDATE hero SET name = ‘法正’ WHERE number = 1;5COMMIT;6ROLLBACK; 如上表,Session A和Session B各开启了一个事件,Session B中的事件先将number列为1的记录的name列更新为'赵云',然后Session A中的事件接着又把这条number列为1的记录的name列更新为法正。假如之后Session B中的事件举行了回滚,那么Session A中的更新也将不复存在,这种现象就称之为脏写。这时Session A中的事件就很懵逼,我明显把数据更新了,末了也提交事件了,怎么到末了说自己啥也没干呢? 脏读(Dirty Read) :假如一个事件读到了另一个未提交事件修改过的数据,那就意味着发生了脏读,示意图如下:
Session ASession B1BEGIN;2BEGIN;3UPDATE hero SET name = ‘赵云’ WHERE number = 1;4SELECT * FROM hero WHERE number = 1;(此时读到的name列的值为‘赵云’,味的发生了脏读)5COMMIT;6ROLLBACK; 如上表,Session A和Session B各开启了一个事件,Session B中的事件先将number列为1的记录的name列更新为'赵云',然后Session A中的事件再去查询这条number为1的记录,假如读到列name的值为'赵云',而Session B中的事件稍后举行了回滚,那么Session A中的事件相当于读到了一个不存在的数据,这种现象就称之为脏读。 不可重复读(Non-Repeatable Read): 假如一个事件只能读到另一个已经提交的事件修改过的数据,而且其他事件每对该数据举行一次修改并提交后,该事件都能查询得到最新值,那就意味着发生了不可重复读,示意图如下:
Session ASession B1BEGIN;2SELECT * FROM hero WHERE number = 1;(此时读到的name列的值为‘张角’)3UPDATE hero SET name = ‘赵云’ WHERE number = 1;4SELECT * FROM hero WHERE number = 1;(此时读到的name列的值为‘赵云’,意味的发生了不可重复读)5UPDATE hero SET name = ‘法正’ WHERE number = 1;6SELECT * FROM hero WHERE number = 1;(此时读到的name列的值为‘法正’,意味的发生了不可重复读) 如上表,我们在Session B中提交了几个隐式事件(意味着语句竣事事件就提交了),这些事件都修改了number列为1的记录的列name的值,每次事件提交之后,假如Session A中的事件都可以查看到最新的值,这种现象也被称之为不可重复读。 幻读(Phantom): 假如一个事件先根据某些条件查询出一些记录,之后另一个事件又向表中插入了符合这些条件的记录,原先的事件再次按照该条件查询时,能把另一个事件插入的记录也读出来,那就意味着发生了幻读,示意图如下:
Session ASession B1BEGIN;2SELECT * FROM hero WHERE number = 1;(此时读到的name列的值为‘张角’)3INSERT INTO hero VALUES(1,‘许诸’,‘魏国’);4SELECT * FROM hero WHERE number = 1;(此时读到的name列的值为‘张角’、‘许诸’,意味的发生了幻读) 如上表,Session A中的事件先根据条件number > 0这个条件查询表hero,得到了name列值为'张角'的记录;之后Session B中提交了一个隐式事件,该事件向表hero中插入了一条新记录;之后Session A中的事件再根据雷同的条件number > 0查询表hero,得到的效果集中包含Session B中的事件新插入的那条记录,这种现象也被称之为幻读。 Q1: 假如Session B中是删除了一些符合number > 0的记录而不是插入新记录,那Session A中之后再根据number > 0的条件读取的记录变少了,这种现象算不算幻读呢? W1: 明确说一下,这种现象不属于幻读,幻读强调的是一个事件按照某个雷同条件多次读取记录时,后读取时读到了之前没有读到的记录。 小提士:
那对于先前已经读到的记录,之后又读取不到这种环境,算啥呢?其实这相当于对每一条记录都发生了不可重复读的现象。幻读只是重点强调了读取到了之前读取没有获取到的记录。
2.2 SQL标准中的四种隔离级别
小提示:
实际上insert undo只在事件回滚时起作用,当事件提交后,该类型的undo日记就没用了,它占用的Undo Log Segment也会被体系采取(也就是该undo日记占用的Undo页面链表要么被重用,要么被释放)。虽然真正的insert undo日记占用的存储空间被释放了,但是roll_pointer的值并不会被清除,roll_pointer属性占用7个字节,第一个比特位就标记着它指向的undo日记的类型,假如该比特位的值为1时,就代表着它指向的undo日记类型为insert undo。所以我们之后在画图时都会把insert undo给去掉,各人留意一下就好了。
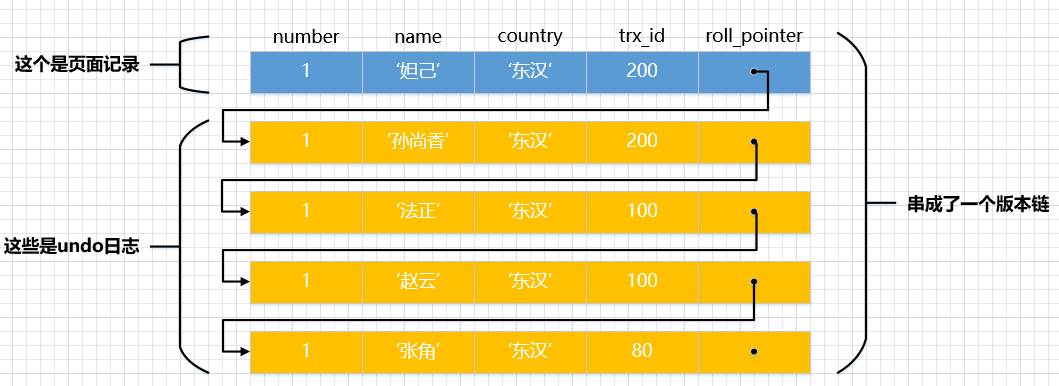
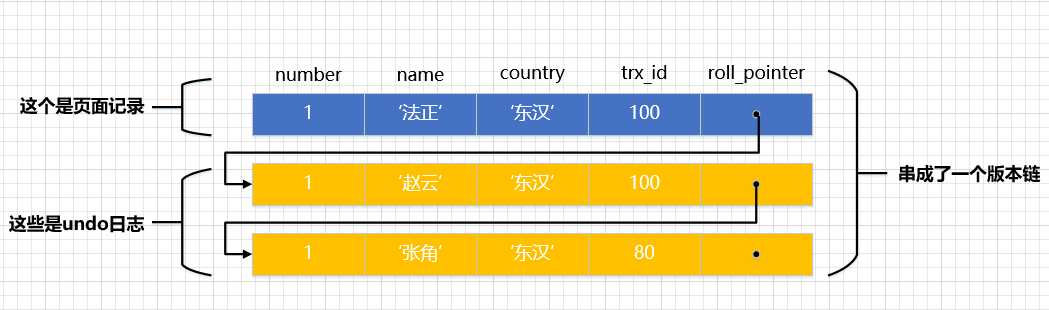
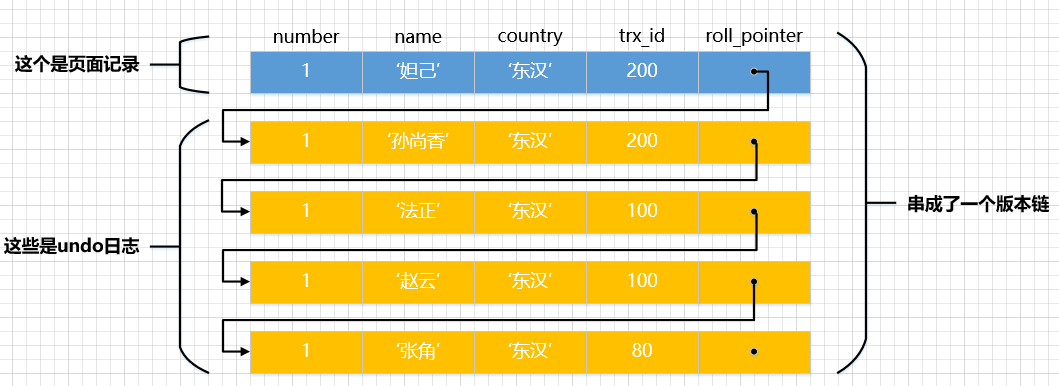
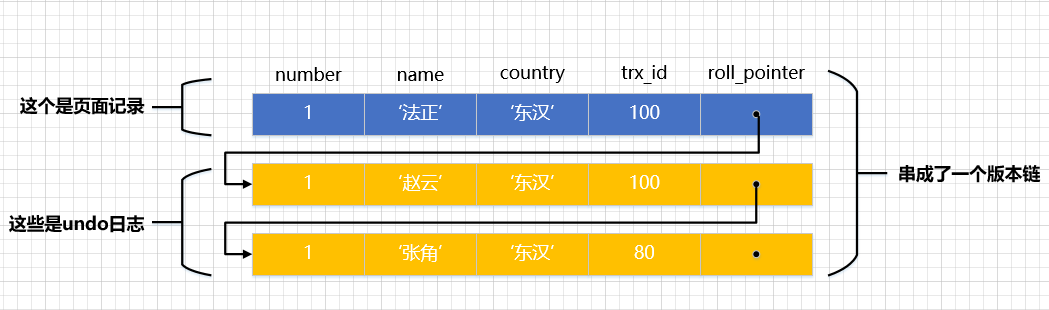
假设之后两个事件id分别为100、200的事件对这条记录举行UPDATE操作,操作流程如下:
trx 100trx 2001BEGIN;2BEGIN;3UPDATE hero SET name = ‘赵云’ WHERE number = 1;4UPDATE hero SET name = ‘法正’ WHERE number = 1;5COMMIT;6UPDATE hero SET name = ‘孙尚香’ WHERE number = 1;7UPDATE hero SET name = ‘妲己’ WHERE number = 1;8COMMIT; 小提示:
能不能在两个事件中交织更新同一条记录呢?哈哈,这不就是一个事件修改了另一个未提交事件修改过的数据,沦为了脏写了么?InnoDB利用锁来包管不会有脏写环境的发生,也就是在第一个事件更新了某条记录后,就会给这条记录加锁,另一个事件再次更新时就需要等待第一个事件提交了,把锁释放之后才可以继续更新。关于锁的更多细节我们后续的文章中再举行学习~
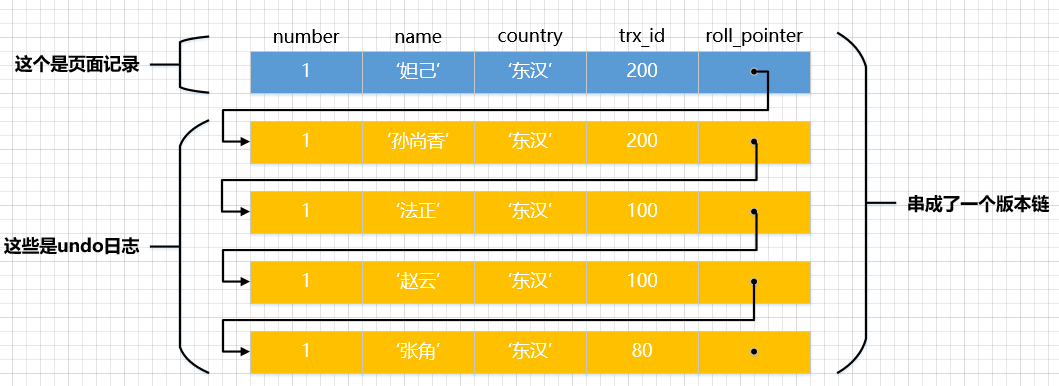
每次对记录举行更新,都会记录一条undo日记,每条undo日记也都有一个roll_pointer属性(INSERT操尴尬刁难应的undo日记没有该属性,因为该记录并没有更早的版本),可以将这些undo日记都连起来,串成一个链表,所以如今的环境就像下图一样:
至此今天的学习就到此竣事了,愿您成为坚如盘石的自己~~~
You can’t connect the dots looking forward; you can only connect them looking backwards. So you have to trust that the dots will somehow connect in your future.You have to trust in something - your gut, destiny, life, karma, whatever. This approach has never let me down, and it has made all the difference in my life
假如我的内容对你有帮助,请 点赞、批评、收藏,创作不易,各人的支持就是我坚持下去的动力! 本文章参考:小孩子《MySQL是怎样运行的》