ToB企服应用市场:ToB评测及商务社交产业平台
标题:
【JAVA日志】关于日志系统的架构讨论
[打印本页]
作者:
民工心事
时间:
2024-6-11 09:58
标题:
【JAVA日志】关于日志系统的架构讨论
目录
1.日志系统概述
2.环境搭建
3.应用如何推日志到MQ
4.logstash如何去MQ中取日志
5.如何兼顾分布式链路追踪
1.日志系统概述
关于日志系统,其要支撑的焦点本领无非是日志的存储以及检察,最好的检察方式固然是实现可视化。目前市面上有成熟的解决方案——ELK,即elastic search+logstash+kibana。前文中我们已经聊过了ELK这条线,本文主要就是基于ELK并在其中加一个MQ作为中间层来流量削峰、异步写日志。
这里起首要声明的是,虽然本文在日志系统中利用到了MQ,但MQ真的是须要的嘛?
这个要看系统的体量了。除非是超大型的分布式架构,服务上百个而且并发量较高,才会考虑用MQ来做一层缓存从而来降低IO压力。如果不是上述环境的话是没有须要上MQ来做一个中间层的。日志作为系统中掺入的"沙子",其量原来就不会很大,一次API调用平均能产生一条日志吗?其实是不见的是吧。所以就这点数据量上MQ这种吞吐量的中间层简直就是杀鸡用牛刀,过度设计,徒增了系统的复杂度了。MQ更多的时候是拿来做移步任务或者定时任务的,用来做业务上的流量削峰或者异步的去做些事情。比如异步的下订单、订单超时取消等。绝大多数时候我们的日志系统的架构,直接让存储去直面日志IO都是能轻轻松松顶得住的。所谓的让存储去直面日志的IO是什么意思?就是比如我走了ELK这条线,那么就直接讲日志往es内里丢就对了。ELK这么用前面已经有文章介绍过了。本文照旧聊一聊假设真的到了很极限的中间需要引入MQ的环境。
ELK的搭建这里就不赘述了,前面有文章详细聊过:
https://bugman.blog.csdn.net/article/details/135964825?spm=1001.2014.3001.5502
https://bugman.blog.csdn.net/article/details/136017853?spm=1001.2014.3001.5502
https://bugman.blog.csdn.net/article/details/136066171?spm=1001.2014.3001.5502
这里我们只需要关注几个点:
应用的日志如何推到mq中
logstash如何去取mq中存放的日志
2.环境搭建
ELK相干内容:
MQ我们选择rabbitMQ,作为一个开箱即食的MQ,rabbitMQ的下载安装网上文章车载斗量,此处就不赘述了。
3.应用如何推日志到MQ
写日志肯定是JAVA的日志框架来负责的,前面有文章已经详细的介绍了JAVA的日志框架:
【JAVA日志框架】JUL,JDK原生日志框架详解。_jul jdk-CSDN博客
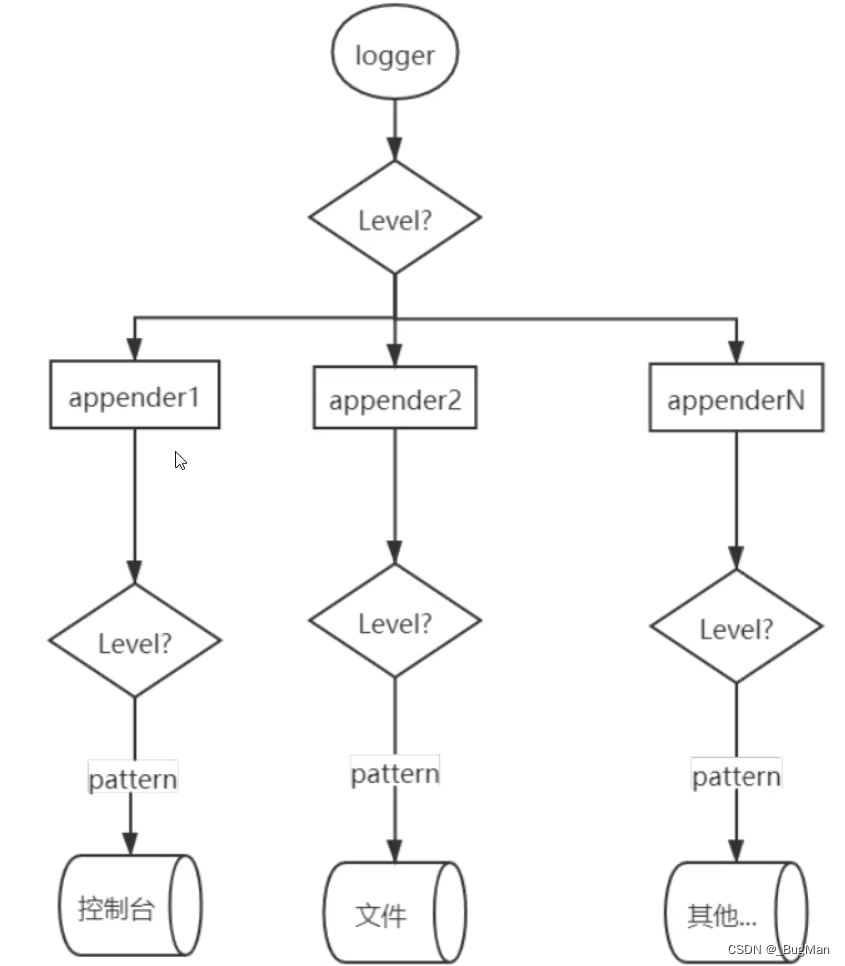
JAVA的日志框架总的来说架构都是大同小异的,都是由差别的appender(有的内里叫handler其实都是一个东西)来向差别的地方写日志:
既然要往rabbitMQ内里写日志,那固然就要一个rabbitMQ的appender了。这个appender在哪里?在rabbitMQ的JAVA API依赖中:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>
然后配置一下日志框架的配置文件即可,这里我们以spring boot默认的日志框架logback为例,在其配置文件中配置好rabbitMQ的appender即可:
<configuration>
<!-- 界说 RabbitMQ 连接 -->
<appender name="RABBIT" class="com.github.logback.amqp.AmqpAppender">
<host>localhost</host> <!-- RabbitMQ 主机地址 -->
<port>5672</port> <!-- RabbitMQ 端口 -->
<username>guest</username> <!-- RabbitMQ 用户名 -->
<password>guest</password> <!-- RabbitMQ 密码 -->
<exchange>logs</exchange> <!-- RabbitMQ 交换机 -->
<routingKey>logstash</routingKey> <!-- RabbitMQ 路由键 -->
<declareExchange>true</declareExchange> <!-- 是否声明交换机 -->
<exchangeType>fanout</exchangeType> <!-- 交换机类型 -->
<durable>true</durable> <!-- 是否持久化消息 -->
<applicationId>myApplication</applicationId> <!-- 应用程序标识 -->
<!-- 其他可选配置 -->
<!--<declareQueue>true</declareQueue>-->
<!--<queue>logQueue</queue>-->
<!--<declareBinding>true</declareBinding>-->
</appender>
<!-- 界说日志输特殊式 -->
<layout class="ch.qos.logback.classic.PatternLayout">
<
attern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</Pattern>
</layout>
<!-- 根日志输出到 RabbitMQ -->
<root level="INFO">
<appender-ref ref="RABBIT"/>
</root>
</configuration>
4.logstash如何去MQ中取日志
logstash的input可以明白为插件,既然是插件固然就有许多中类型,其中就包括rabbitMQ的(天然也有别的的),下面是logstash从MQ中取数据然后推给es的一份示例:
input {
rabbitmq {
host => "localhost" # RabbitMQ 主机地址
port => 5672 # RabbitMQ 端口
user => "guest" # RabbitMQ 用户名
password => "guest" # RabbitMQ 密码
queue => "logQueue" # RabbitMQ 队列名
durable => true # 是否持久化队列
ack => true # 是否需要手动确认消息
threads => 1 # 线程数
}
}
output {
stdout { codec => rubydebug } # 输出到控制台,可选
elasticsearch {
hosts => ["localhost:9200"] # Elasticsearch 主机地址
index => "logstash-%{+YYYY.MM.dd}" # Elasticsearch 索引名
}
}
5.如何兼顾分布式链路追踪
这里顺带讨论一个问题,就是在ELK体系中如何去实现分布式链路跟踪。分布式链路跟踪相干内容前面有文章详细讨论过:
https://bugman.blog.csdn.net/article/details/135258207?spm=1001.2014.3001.5502
https://bugman.blog.csdn.net/article/details/135258207?spm=1001.2014.3001.5502
其着实ELK中实现分布式链路追踪的方式很简单,思绪如下:
仍然在应用侧上链路追踪技术来同一日志格式,然后要进行查询追踪的时候直接利用Kibana的搜索和过滤功能来仅显示与特定跟踪ID或请求ID相干的日志消息,或者利用Kibana的图表功能,将日志数据与分布式追踪数据结合起来,创建可视化的图表和仪表板。你可以根据需要显示请求的整个路径、每个步骤的响应时间、错误率等指标。
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/)
Powered by Discuz! X3.4

 attern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</Pattern>
attern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</Pattern>