ToB企服应用市场:ToB评测及商务社交产业平台
标题:
Linux进程地点空间
[打印本页]
作者:
汕尾海湾
时间:
2024-6-11 11:06
标题:
Linux进程地点空间
目录
一.程序地点空间
1. 如何编址
二.进程地点空间
1.mm_struct
2.父子两个进程修改同一变量的原理
3.什么是进程地点空间
3.为什么会存在虚拟进程地点空间?
缘故起因1:
缘故起因2
缘故起因3
Linux进程地点空间是学习Linux的过程中,我们遇见的第一个难点,也是重中之重的重点。虽然它很难,但是,等我们真正懂得了这样计划的原理,我们不禁会感叹:这真的是太妙了。接下来,就让我么开启这一段学习之旅吧!
一.程序地点空间
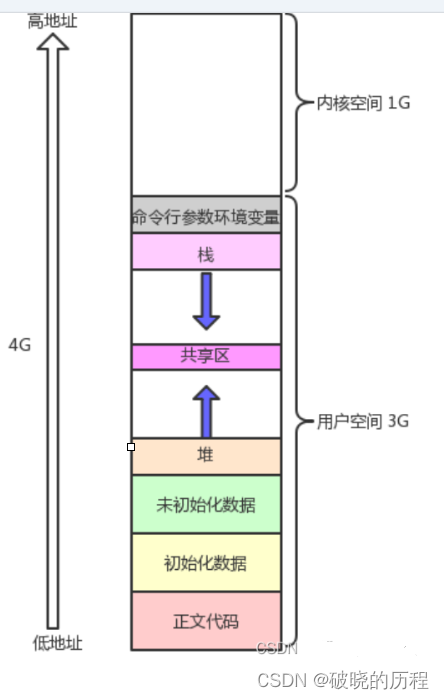
大家在系统学习C/C++时,有没有见过这张图:
这就是闻名的内存地点模型。越往上地点越高。
这些地区为什么按照这种顺序排列呢?这种排列顺序对吗?
接下来,我们验证一下:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int g_unval; // 未初始化全局变量
int g_val = 100; // 已初始化全局变量
int main()
{
printf("code addr代码段地址: %p\n", main);
printf("init data addr初始化全局变量地址: %p\n", &g_val);
printf("uninit data addr未初始化全局变量地址: %p\n", &g_unval);
char *heap = (char *)malloc(sizeof(char)); // 堆区开辟空间
printf("heap addr/堆区地址: %p\n", heap);
printf("stack addr栈区地址: %p\n", &heap);
return 0;
}
复制代码
以是
:
根据结果,我们发现
stack>heap>uninit data>init data>code;
以是,我们的结果和这张图是相互对应的。
但是,堆区和栈区的增长的方向是怎样呢?这个好办;方向是比对出来的,我们只需要多申请几次堆空间和栈空间,然后比较地点大小变化。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int g_unval; // 未初始化全局变量
int g_val = 100; // 已初始化全局变量
int main()
{
printf("code addr代码段地址: %p\n", main);
printf("init data addr初始化全局变量地址: %p\n", &g_val);
printf("uninit data addr未初始化全局变量地址: %p\n", &g_unval);
char *heap1 = (char *)malloc(sizeof(char)); // 堆区开辟空间
char *heap2 = (char *)malloc(sizeof(char)); // 堆区开辟空间
char *heap3 = (char *)malloc(sizeof(char)); // 堆区开辟空间
char *heap4 = (char *)malloc(sizeof(char)); // 堆区开辟空间
printf("heap addr/堆区地址: %p\n", heap1);
printf("heap addr/堆区地址: %p\n", heap2);
printf("heap addr/堆区地址: %p\n", heap3);
printf("heap addr/堆区地址: %p\n", heap4);
printf("stack addr栈区地址: %p\n", &heap1);
printf("stack addr栈区地址: %p\n", &heap2);
printf("stack addr栈区地址: %p\n", &heap3);
printf("stack addr栈区地址: %p\n", &heap4);
return 0;
}
复制代码
由此,我们得出了堆区是往上增长的,栈区是往下增长的,堆栈相应 。
我以为:我们有须要再试一下情况变量和下令行参数。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int g_unval; // 未初始化全局变量
int g_val = 100; // 已初始化全局变量
int main(int argc,char *argv[],char *env[])
{
printf("code addr代码段地址: %p\n", main);
printf("init data addr初始化全局变量地址: %p\n", &g_val);
printf("uninit data addr未初始化全局变量地址: %p\n", &g_unval);
char *heap1 = (char *)malloc(sizeof(char)); // 堆区开辟空间
printf("heap addr/堆区地址: %p\n", heap1);
printf("stack addr栈区地址: %p\n", &heap1);
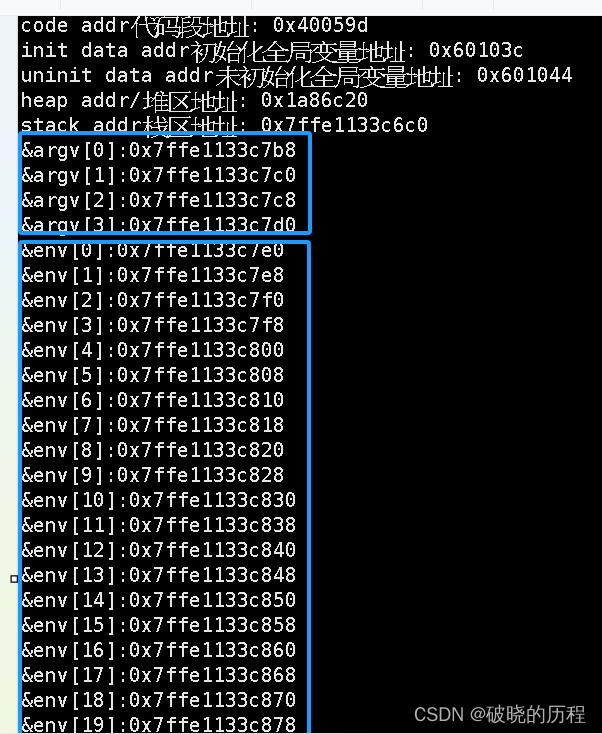
for(int i=0;i<argc;i++)
{
printf("&argv[%d]:%p\n",i,argv+i);
}
for(int i=0;env[i];i++)
{
printf("&env[%d]:%p\n",i,env+i);
}
return 0;
}
复制代码
我们看到:情况变量的地点和下令行参数的地点都要比堆区和栈区的地点大;情况变量的地点比下令行选项的地点大。这恰恰说明了:先下令行选项表,再创建情况变量表。
这里,我还想和大家告竣几个共识:
地点空间描述的基本空间大小为字节。
在32位情况下,一共需要2^32个地点。
2^32*1字节=4GB的空间大小。
每个字节都有唯一的地点。
1. 如何编址
地点的最大意义就是不重复,具有唯一性即可。以是就要对整个程序地点空间举行编址。利用unsigned int即可。
为了明白如何编址,我们讲一个小故事:
有一个上小学的女孩,非常爱干净。她有一个男同桌,很不爱干净,而且平时喜欢靠近她,抢她的位置,同桌嘛。有一天女孩着实受不了了,大吼道:"在桌子中心画一条线,你越过这一条线,我就打你"。但是,由于男孩很胖,总是一不小心就越界了,不出不测的被女孩带来几顿。有一次,男孩说:"你别打我了,我真不是故意的,我太胖了"。无奈之下,女孩说:"这样吧,我挪5厘米,你挪5厘米,建立一个10厘米的缓冲地带,你可以占缓冲区,但不能越过缓冲区,要不然我还打你,而且打的更狠"。
小孩子的世界总是这么灵活,这么有趣。但在他们的世界里没有代码给我们带来的快乐,而我们有!!哈哈哈哈哈
如今的我们体会到了敲代码的乐趣,任何东西想用代码来搞一搞。在我们这批未来互联网的精英们看来,两个小孩子的画清边界的行为,也可以用一个结构体实现:
我们假设桌子常1米,那么两个小孩子最后商定的方法为:
struct boundary
{
int boy_start;//男孩起始位置
int boy_end;//男孩终止位置
int buffer_start;//缓冲地带起始位置
int buffer_end;//缓冲地带终止位置
int girl_start;//女孩起始位置
int girl_end;//女孩终止位置
};
复制代码
struct boundary bd{0,45,46,55,56,100};
复制代码
分别好位置,我们就可以准确的说明一个在桌面上的物体准确具体 ,好比我们可以说:在35处,有一个橡皮。
我们是不是也可以用这种来标定整个程序地点空间呢?把整个4GB的空间比作一个桌面。需要用到2^32个地点,int在32位情况下正好是32个比特位,可以体现的最大数据就是2^32。如此我们就可以具体列出一个数据所在的地点。
我们来看看内核中是怎样计划的:
确实跟我们说的描述方式一模一样。
二.进程地点空间
我们在C/C++中的取地点操作,取的是内存中的地点?
其实,不是的!!
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int num = 0;
int wer = 100;
int main()
{
pid_t fd = fork();
if (fd < 0)
{
printf("fork fail!\n");
}
else if (fd == 0)
{
while (2)
{
printf("我是子进程,wer:%d,&wer:%p\n", wer, &wer);
num++;
if (num == 10)
{
printf("wer数据已被修改,修改是由子进程完成的\n");
wer=300;
}
sleep(1);
}
}
else
{
while (1)
{
printf("我是父进程,wer:%d,&wer:%p\n", wer, &wer);
sleep(3);
}
}
return 1;
}
复制代码
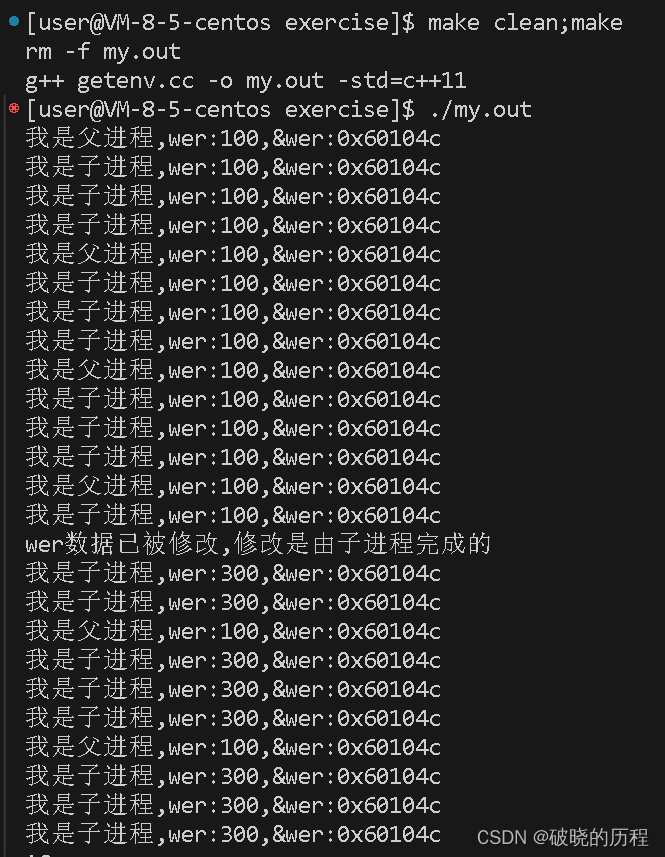
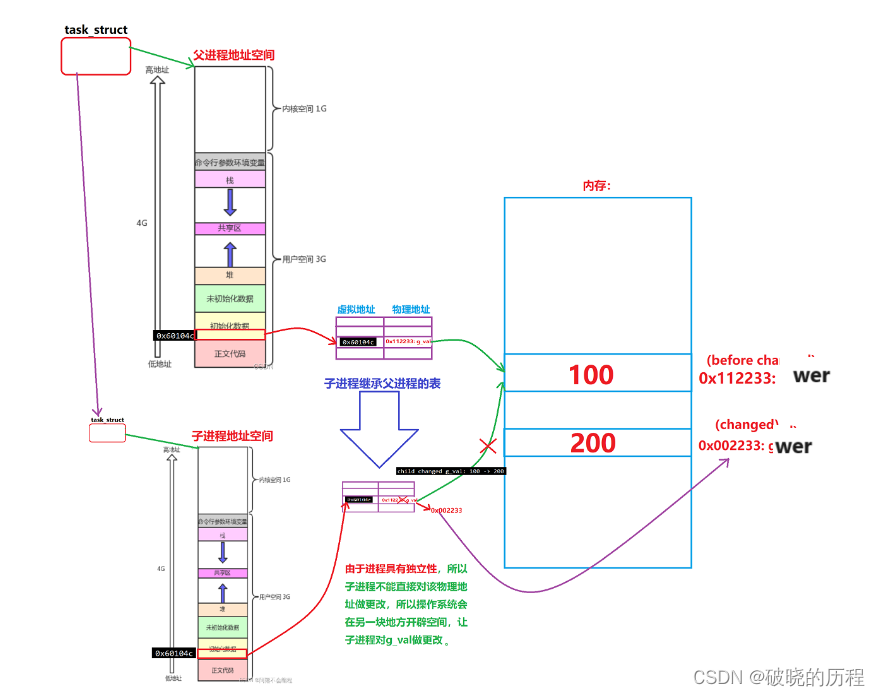
我们来看:数据被子进程修改之后,竟然出现了从一个地点中读取的数据不一样的情况。
,这是什么鬼!!如果读取的是内存中的地点,肯定不会出现这样的情况,以是,我们有来由怀疑:读取的根本不是内存中的地点。
但是由此我们就可以知道,
程序地点空间并 不是 内存,它的正确叫法为 进程地点空间
!
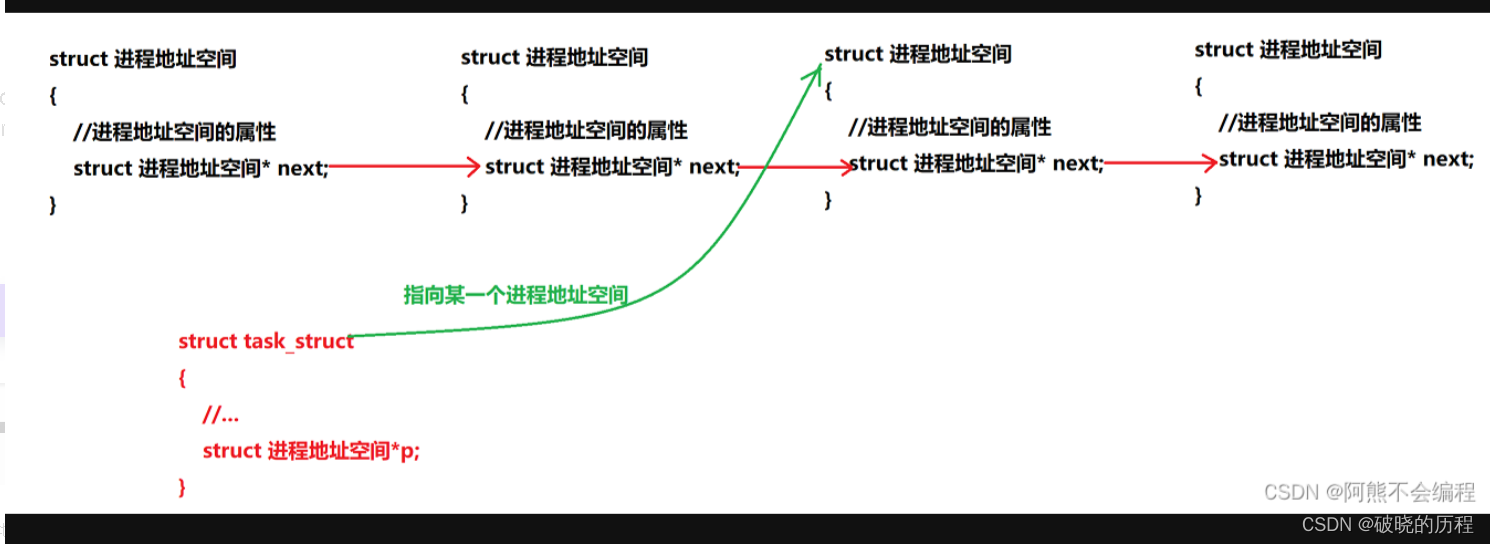
我们读取的地点是虚拟地点(也叫做逻辑地点)。虚拟地点空间就是操作系统内核中的一个名为mm_struct结构体。
1.mm_struct
每一个进程都只有1个内存描写符mm_struct。在每一个进程的task_struct结构中,有1个指向mm_struct的变量,这个变量经常是mm_struct。
mm_struct是对进程的地点空间(虚拟内存)的描写。1个进程的虚拟空间中大概有多个虚拟区间,对这些虚拟空间的构造方式有两种,当虚拟区较少时采取单链表,由mmap指针指向这个链表,当虚拟区间多时采取红黑树举行管理,由mm_rb指向这棵树。由于程序中用到的地点经常具有局部性,因此,最近1次用到的虚拟区间极大概下1次还要用到,因此把最近用到的虚拟区间结构放到高速缓存,这个虚拟区间就由mmap_cache指向。
指针pgt指向该进程的页目录(每一个进程都有本身的页目录),当调理程序调理1个程序运行时,就将这个地点转换成物理地点,并写入控制寄存器。
由于进程的虚拟空间及下属的虚拟区间有大概在差别的上下文中遭到访问,而这些访问又必须互斥,以是在该结构中设置了用于P,V操作的信号量mmap_sem。另外,page_table_lock也是为雷同的目的而设置。
虽然每一个进程只有1个虚拟空间,但是这个虚拟空间可以被别的进程来同享。如:子进程同享父进程的地点空间,而mm_user和mm_count就对其计数。
另外,还描写了代码段、数据段、堆栈段、参数段及情况段的起始和结束地点。
struct mm_struct
{
struct vm_area_struct *mmap; //指向虚拟区间(VMA)链表
struct rb_root mm_rb; //指向red_black树
struct vm_area_struct *mmap_cache; //找到最近的虚拟区间
unsigned long(*get_unmapped_area)(struct file *filp,unsigned long addr,unsigned long len,unsigned long pgoof,unsigned long flags);
void (*unmap_area)(struct mm_struct *mm,unsigned long addr);
unsigned long mmap_base;
unsigned long task_size; //具有该结构体的进程的虚拟地址空间的大小
unsigned long cached_hole_size;
unsigned long free_area_cache;
pgd_t *pgd; //指向页全局目录
atomic_t mm_users; //用户空间中有多少用户
atomic_t mm_count; //对"struct mm_struct"有多少援用
int map_count; //虚拟区间的个数
struct rw_semaphore mmap_sem;
spinlock_t page_table_lock; //保护任务页表和mm->rss
struct list_head mmlist; //所有活动mm的链表
mm_counter_t _file_rss;
mm_counter_t _anon_rss;
unsigned long hiwter_rss;
unsigned long hiwater_vm;
unsigned long total_vm,locked_vm,shared_vm,exec_vm;
usingned long stack_vm,reserved_vm,def_flags,nr_ptes;
unsingned long start_code,end_code,start_data,end_data; //代码段的开始start_code ,结束end_code,数据段的开始start_data,结束end_data
unsigned long start_brk,brk,start_stack; //start_brk和brk记录有关堆的信息,start_brk是用户虚拟地址空间初始化,brk是当前堆的结束地址,start_stack是栈的起始地址
unsigned long arg_start,arg_end,env_start,env_end; //参数段的开始arg_start,结束arg_end,环境段的开始env_start,结束env_end
unsigned long saved_auxv[AT_VECTOR_SIZE];
struct linux_binfmt *binfmt;
cpumask_t cpu_vm_mask;
mm_counter_t context;
unsigned int faultstamp;
unsigned int token_priority;
unsigned int last_interval;
unsigned long flags;
struct core_state *core_state;
}
复制代码
那,什么缘故起因会造成我们看到的这种情况呢?虚拟地点空间和真正的内存之间是什么关系呢?
2.父子两个进程修改同一变量的原理
写时拷贝技术
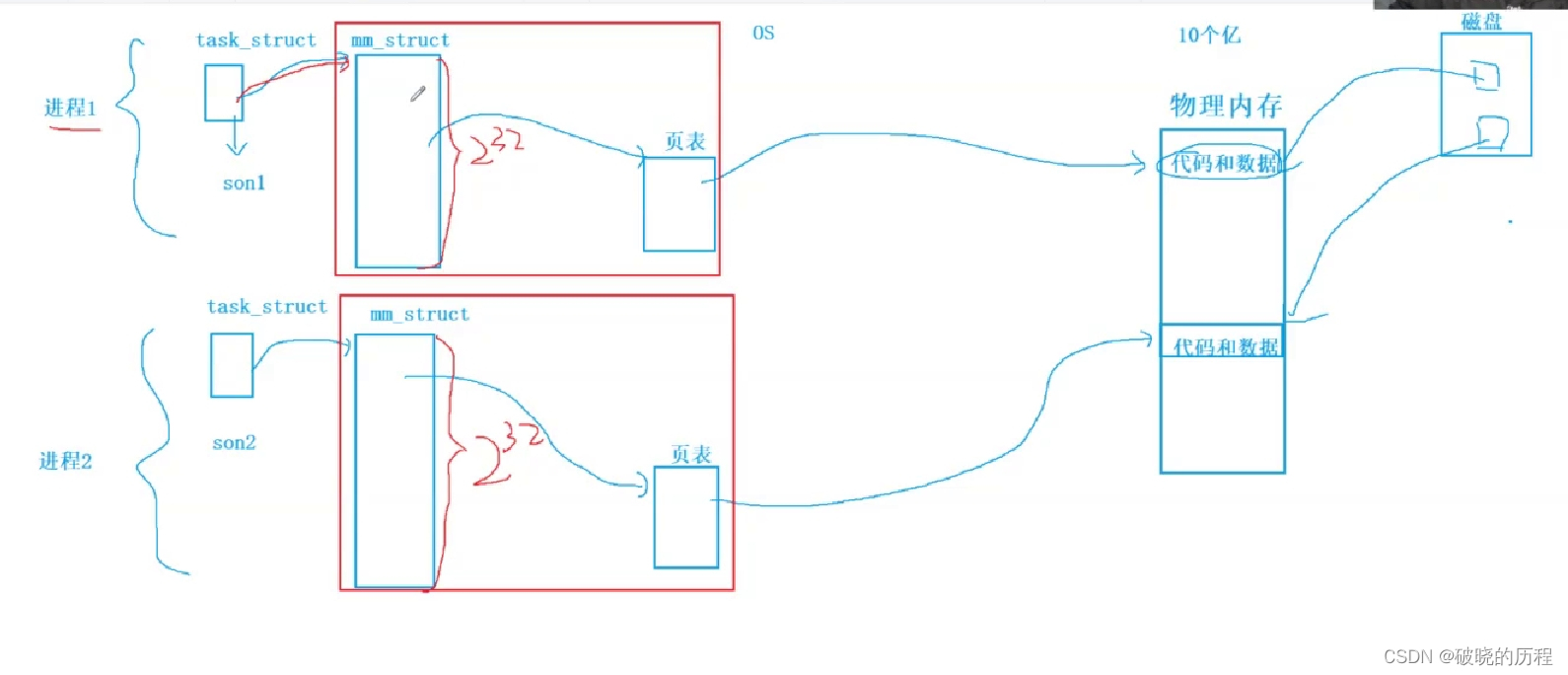
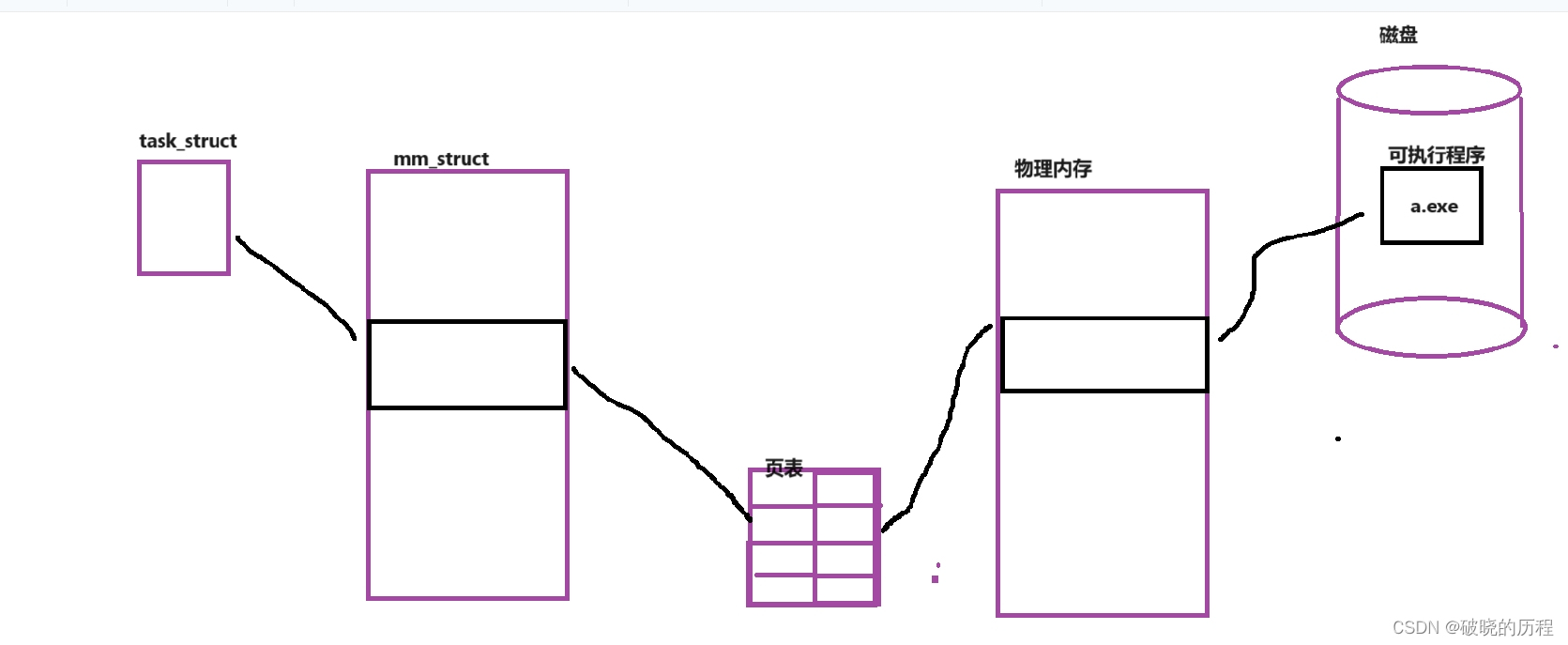
我们在取地点操作中得到的地点都是虚拟地点,虚拟地点通过一张表格和内存之间建立映射关系,进而通过虚拟地点找到真正的内存中的地点,得到代码和数据。
有一进程在调用fork函数创建子进程时,操作系统会将父进程的PCB,mm_struct结构体,包括页表复制一份给子进程,以是父子进程中相同的虚拟地点通过页表映射会找到同一块内存空间,读取到相同的数据。如果此中一个进程想要对数据举行修改,我们知道进程之间必须确保独立性,一个进程修改的数据极有大概会影响到另一个进程。这时,操作系统会为要修改数据的进程开辟一段空间,然后将原来的数据拷贝一份放入新开辟的空间中,然后改变页表的映射关系(虚拟地点相同,但内存地点差别),之后对数据举行修改。这就造成了一个虚拟地点访问到两个差别的物理地点,进而得到两份差别的数据。
此中,这种父子进程先共享一份内存数据,然后等到父或子进程要对共享数据举行修改时,操作系统为了保证进程之间的独立性,才为其分配各种的内存空间,这种方式叫做写时拷贝。
写实拷贝有哪些意义呢?
写时拷贝技术现实上是一种耽搁战术,是为了提高效率而产生的技术,这怎么提高效率呢?现实上就是在需要开辟空间时,假装开了空间,现实上用的照旧原来的空间,淘汰开辟空间的时间,等到真正要利用新空间的时候才去真正开辟空间。
举一个例子明白写时拷贝技术:我们小时候经常会碰到这种情况:家内里有哥哥姐姐的,大人们经常会让我们穿哥哥姐姐穿剩的衣服,这样看起来我们就有了新衣服,但现实上我们穿的照旧哥哥姐姐的旧衣服,等到我们真的长大了,才会给我们买属于本身的新衣服,这样节省了给我们买衣服的时间和财力。从而节省了许多资源(提高效率)。等我们真的需要时才不得不买新衣服(耽搁战术)。
3.什么是进程地点空间
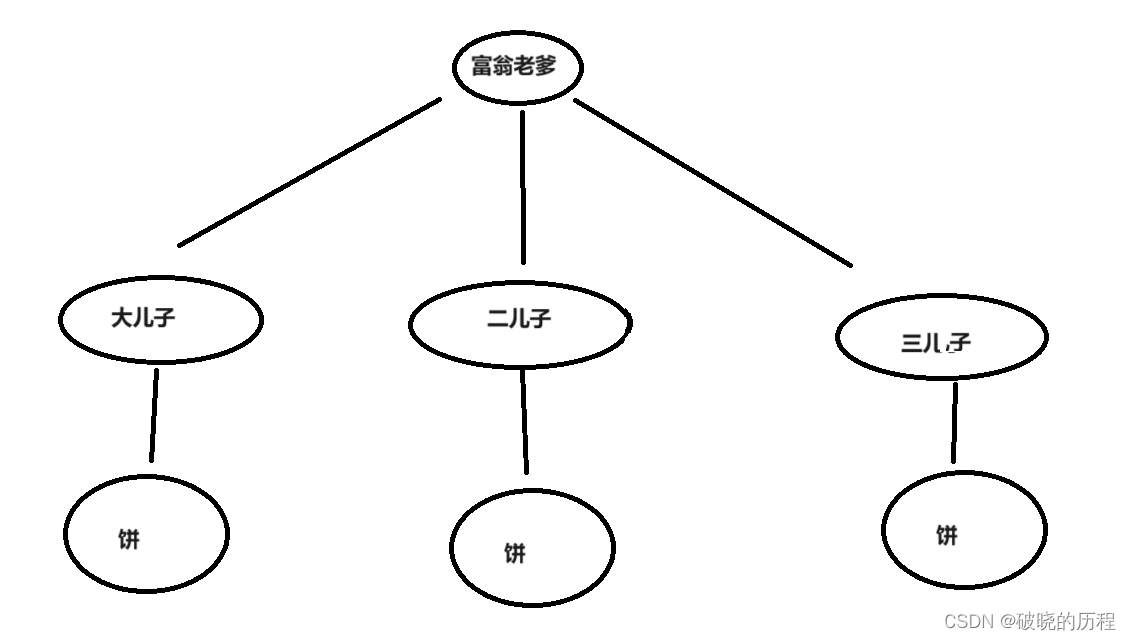
我们先讲一个小故事:
美国有一个富豪,资产高达十亿美金。这个大富豪有三个私生子,他们相互不知道彼此的存在,都认为本身是富豪唯一的儿子,大儿子负责打理本身的农场,富翁对大儿子说:"你好好干,将来让你继承我的资产"。二儿子负责一家金融公司,是这家公司的CEO,富翁语重心长的对他说:"儿子,你最努力,加油相信你,我的资产将来都是你的"。三儿子还在学校读书,学习很努力,就像我一样,
,富翁也蜜意的对三儿子说:"我已经决定把我的资产将来都交给你了"。儿子们听到富翁老爹给本身画的大饼,都很高兴,无论是工作照旧学习,都很努力。富翁心里知道:他们不大概一下子给他要许多的钱的。
在这个故事中,每个儿子都收到了本身的富翁老爹给本身画的一张大饼。
但这些饼说到底是一个虚幻的,是一个愿景。
要想画一个好的饼,需要具备哪些条件
被画饼的人要有记忆能力,要记住别人给他画的什么饼。
画饼的人也要有记忆能力,记住给哪些人画过哪些饼,对号入座。
真正的物理地点就像真正的嘉奖,而虚拟地点空间(mm_struct)就是那一张张大饼,如果有需要,可以向富翁老爹举行申请,其实就相当于
虚拟地点空间向操作系统申请物理地点空间
。
那这些饼操作系统必须有用的构造起来:
3.为什么会存在虚拟进程地点空间?
缘故起因:
如果让进程直接访问物理内存,大概回越界非法访问不属于该进程的代码和数据,非常不安全。
虚拟地点空间的存在,可以更方便的举行进程和进程代码和数据的解耦,更好的保证了 进程的独立性特征。
让进程以同一的视角来对待进程所对应的代码和数据等各个地区,方便编译器也以同一的视角举行代码的编译。
下面,我们逐条来表明。
缘故起因1:
如果让进程直接访问物理内存,大概会越界非法访问不属于该进程本身的代码和数据,非常不安全。
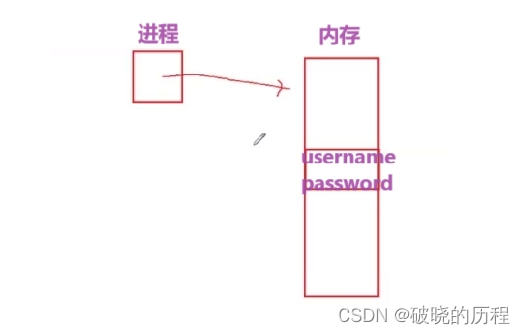
如图所示:如果让一个进程直接访问内存,如果内存中存放着与登录有关的数据(username,password等等),此时如果有一个恶意进程通过扫描内存拿到了和登录有关的数据,那就回造成数据泄露的伤害情况。
但是,这仅仅可以证明直接访问物理内存的这种方式不可,并不代表采用虚拟内存的方式就可以!!接下来,我们看看通过虚拟内存映射是如何办理这个题目的:
我们不要仅仅认为:页表的作用只有映射。我们来讲个故事来说明一下:
小时候。我们会受到压岁钱。每到过年,我们都会很开心,拿着本身的压岁钱,总喜欢去小卖部逛逛,小卖部老板看着我们小,就乱来我们费钱,买些无用的东西。对此,经常会得到棍棒奉养。有一次妈妈对我说:"你的压岁钱我帮你拿着,等到你要费钱时,给我说,我以为你可以买,就给你钱;以为你不应该买,就不给你钱"。
妈妈就相当于一个页表,以是页表不仅仅是映射作用,还要对访问内存空间的行为举行审查,对内存空间举行保护!!这一套规则是所有的进程都必须遵守的。
以是,通过虚拟内存映射这种方式,只会访问到正当地点,不需要担心内存中的数据被写坏,可以很好的保护内存中的代码和数据!!
缘故起因2
虚拟内存空间的存在,可以更好的举行进程和进程代码和数据的解耦,更好的保证了内存独立性
之以是会出现父子进程修改同一数据,会从同一地点处,读出差别数据,是由于有了虚拟内存映射策略,可以做到既节省了内存空间,又使父子进程数据互相独立,保证了独立性。
缘故起因3
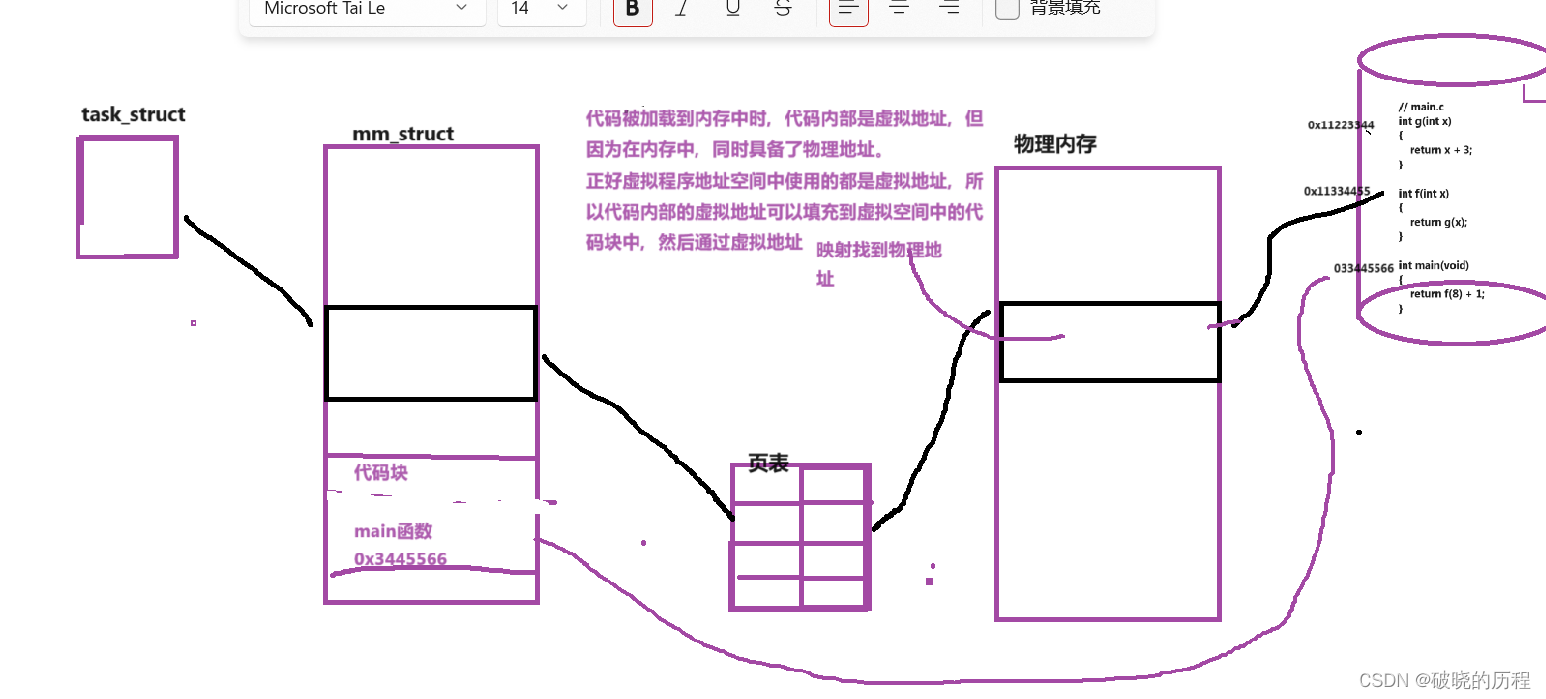
让进程以同一的视角来对待进程所对应的代码和数据等各个地区。方便编译器也以同一的视角来举行代码编译。
问大家:代码在没有被加载到内存之前,代码内部有地点吗?是什么地点?
其实,在未加载内存之前时,代码内部是有地点的,是虚拟地点。
大家在学习C语言时,看过代码的汇编语言?
// main.c
int g(int x)
{
return x + 3;
}
int f(int x)
{
return g(x);
}
int main(void)
{
return f(8) + 1;
}
复制代码
1 g:
2 pushl %ebp
3 movl %esp, %ebp
4 movl 8(%ebp), %eax
5 addl $3, %eax
6 popl %ebp
7 ret
8 f:
9 pushl %ebp
10 movl %esp, %ebp
11 pushl 8(%ebp)
12 call g
13 addl $4, %esp
14 leave
15 ret
16 main:
17 pushl %ebp
18 movl %esp, %ebp
19 pushl $8
20 call f
21 addl $4, %esp
22 addl $1, %eax
23 leave
24 ret
复制代码
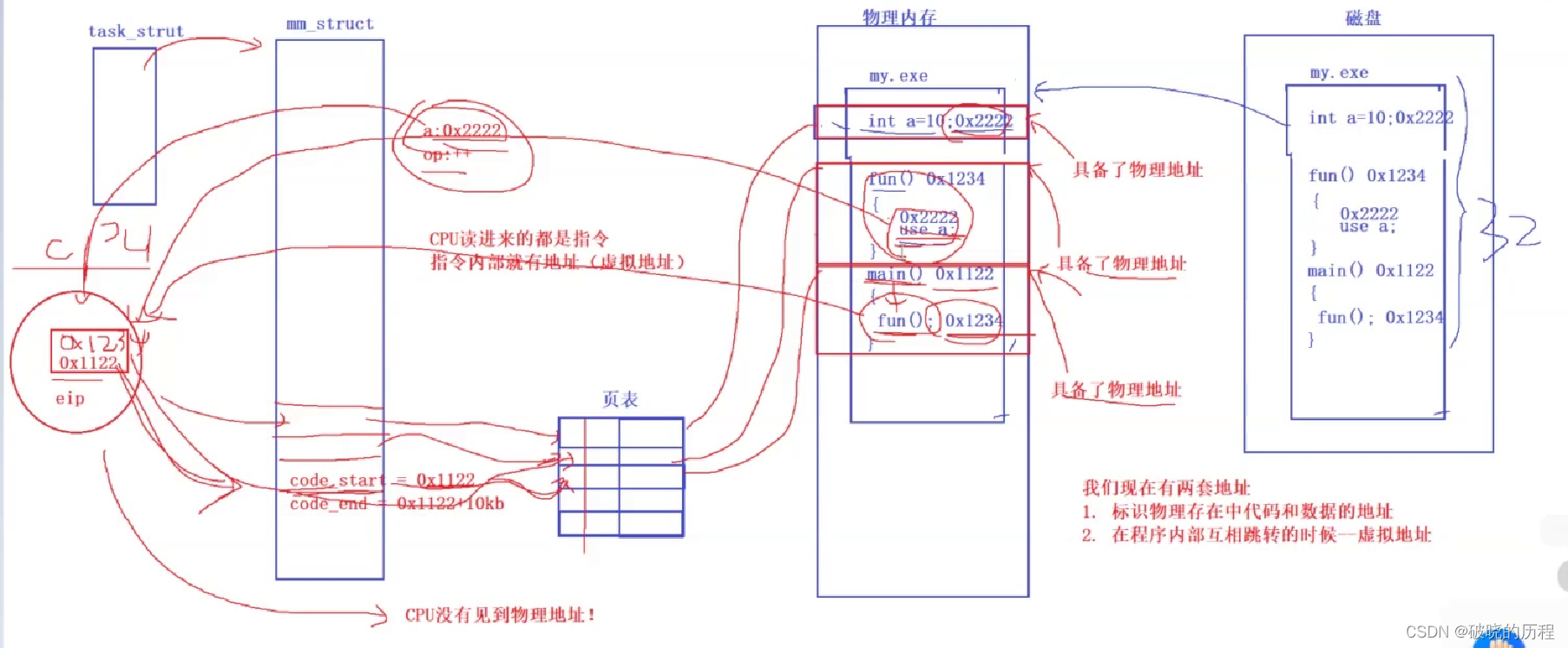
以是,CPU在运行进程时,看到的满是虚拟地点,物理地点的毛都没瞥见。
编译器编译代码和虚拟进程地点空间利用虚拟地点的规则是一样的。方便利用。
因作者水平有限,难免会有错误,请各位指正!!!
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/)
Powered by Discuz! X3.4