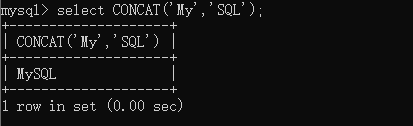
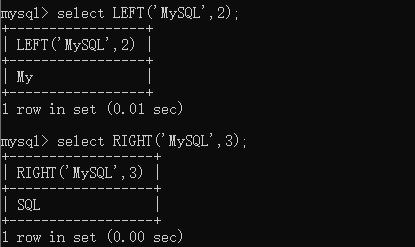
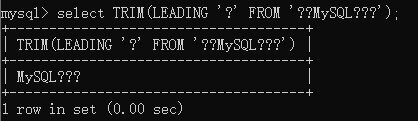
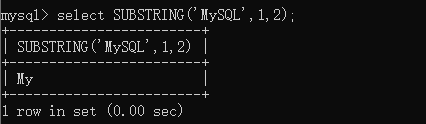
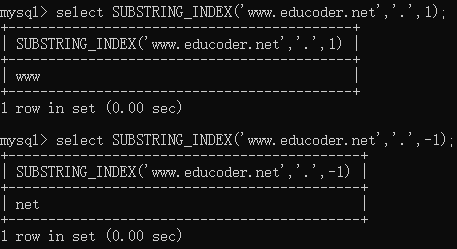
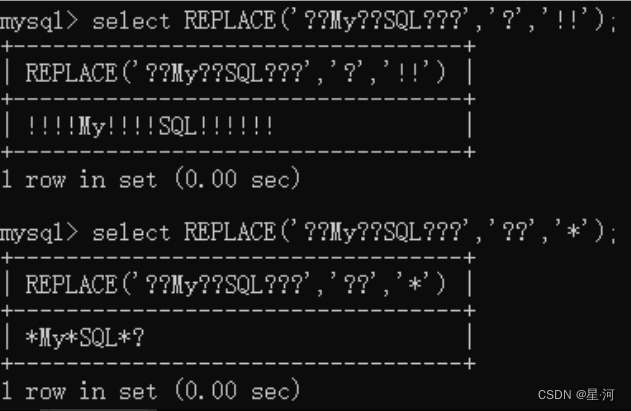
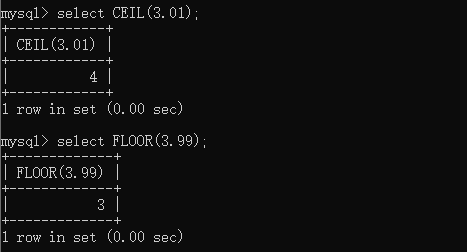
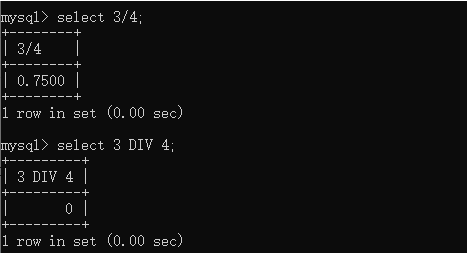
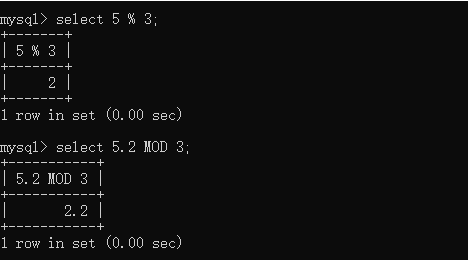
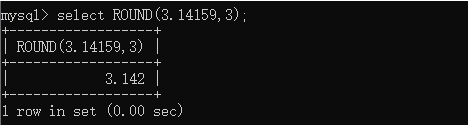
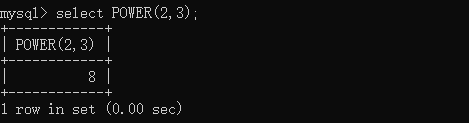
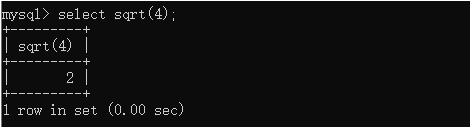
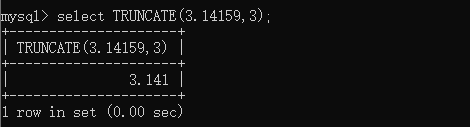
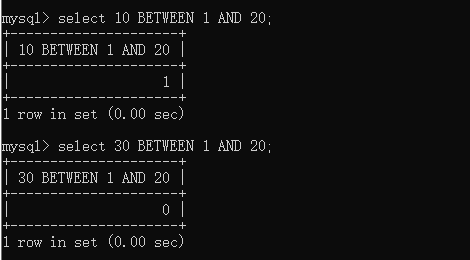
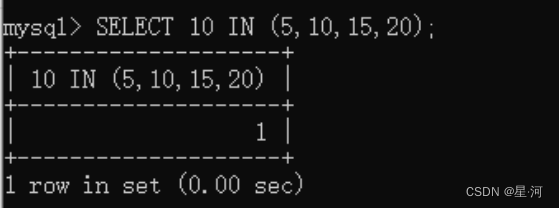
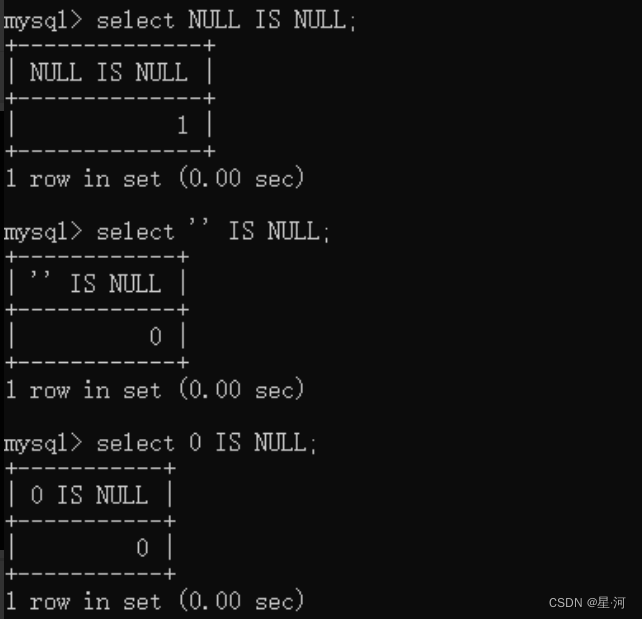
CREATE TABLE t_tmp
(
id int PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(32)
)
在数据库MyDb中创建表t_user,表结构如下:
字段名称数据类型备注idINT用户ID,主键,自动增长usernamevarchar(32)用户名,非空,唯一sexvarchar(4)性别,默认“男” CREATE DATABASE MyDb; use MyDb; create table t_user (id int PRIMARY KEY AUTO_INCREMENT, username VARCHAR(32) NOT NULL UNIQUE, sex varchar(4) DEFAULT '男' )DEFAULT CHARSET =utf8;
CREATE table mytable(
id INT NOT NULL,
username VARCHAR(16) NOT NULL,
INDEX [indexName] (username)
);
2. 建表后创建平凡索引
create INDEX 索引名称 on 表名(字段名); #或者 ALTER TABLE 表名 ADD INDEX 索引名称 (字段名);
创建名为idx_age的平凡索引:
create index idx_age on student(age);
唯一索引:
索引列中的值必须是唯一的,但允许为空值
CREATE UNIQUE INDEX 索引名称 ON 表名(字段名); #或者 ALTER TABLE 表名 ADD UNIQUE (字段名);
创建名为uniq_classes的唯一索引:
CREATE UNIQUE INDEX uniq_classes ON student(classes);
主键索引:
主键索引一般在建表时创建,会设为 int 而且是 AUTO_INCREMENT自增类型的,例如一般表的id字段。
CREATE TABLE mytable ( id int(11) NOT NULL AUTO_INCREMENT, PRIMARY KEY (id) );
创建名为pk_student的主键索引:
create table student(
stu_id int not null ,
name varchar(25) not null,
age int not null,
sex char(2) not null,
classes int not null,
grade int not null,
primary key (stu_id)
);
提示:
1. OR 可以和 AND 一起使用。但是 AND 的优先级要高于 OR 的优先级。
2. 关键字IN,它能实现与OR相同的功能,虽然两种写法功能一样,但是更保举使用 IN 关键字。因为它不但逻辑清晰,执行的速度也会快于 OR 关键字。更紧张的是,使用 IN 关键字,以后可以执行更加复杂的嵌套语句。
显示 jdtj 数据表中街道个数最多的10个的所有字段
select * from jdtj
order by jdgs desc
limit 10;
显示 jdtj 数据表中街道个数最少的10个的所有字段
select * from jdtj
order by jdgs asc
limit 10;
按街道个数从高到底,街道个数相同的按省份升序排序显示 jdtj 数据表中街道个数大于35的所有字段
select * from jdtj
where jdgs>35
order by jdgs desc,sf asc;
八.数据查询(二)
第1关:多表查询
在毗连查询中引用两个表的公共字段时,必须在字段前添加表名作为前缀,否则系统会提示堕落。
二表查询:
select * from 数据表1,数据表2 where 毗连条件
或
from 数据表1 join 数据表2 on 毗连条件
三表查询:
from 数据表1 ,数据表2 ,数据表3 where 毗连条件1 and 毗连条件2
根据读者(reader)和借阅(borrow)数据表,查询王颖珊的借阅记录,包括条形码txm、借阅日期jyrq、还书日期hsrq
select txm , jyrq , hsrq
from borrow , reader
where reader.dzzh = borrow.dzzh and xm='王颖珊';
根据图书(book)和借阅(borrow)数据表,查询李白全集被借阅的情况:包括读者证号dzzh、借阅日期jyrq、还书日期hsrq
select dzzh , jyrq , hsrq
from borrow , book
where borrow.txm = book.txm and book.sm='李白全集';
根据读者(reader)、图书(book)和借阅(borrow)数据表查询没有被归还的借阅信息:包括读者证号dzzh、姓名xm、电话dhhm、条形码txm、书名sm、借阅日期jyrq
提示:通过isnull(表达式)可以判断表达式是否NULL值
select reader.dzzh , xm , dhhm , book.txm , sm , borrow.jyrq
from reader,book,borrow
where reader.dzzh=borrow.dzzh and book.txm = borrow.txm and isnull(hsrq);
第2关:多表查询及统计分组
注意:order by <表达式1>,<表达式2> 表示首先按第一个表达式的值排序,第一个表达式的值相同的再按第二个表达式的值排序
第一题: 统计每本书借阅的次数,显示书名和借阅次数(借阅次数定名为jycs),按借阅次数降序排列,借阅次数相同的按书名降序排列 (提示:borrow数据表的一条数据对应一次借阅)
select sm,count(*)jycs
from borrow left join book on book.txm=borrow.txm
group by sm
order by count(*) desc,sm desc;
select sm,count(*)jycs
from borrow left join book on book.txm=borrow.txm
group by sm having(count(*)>=2)
order by count(*) desc,sm desc;
第三题 统计每个出书社的图书的借阅次数,显示出书社的名称和借阅次数,按借阅次数降序排列,借阅次数相同的按出书社降序排列
select cbs,count(*)jycs
from borrow left join book on book.txm=borrow.txm
group by cbs
order by count(*) desc,cbs desc;
第四题: 统计每位读者借阅的次数,显示姓名和借阅次数,按借阅次数降序排列,借阅次数相同的按姓名降序排列
select xm,count(*)jycs
from borrow left join reader on borrow.dzzh=reader.dzzh
group by xm
order by count(*) desc,xm desc;
第五题: 统计研究生读者借阅的次数,显示姓名和借阅次数,按借阅次数降序排列,借阅次数相同的按姓名降序排列
select xm,count(*)jycs
from borrow left join reader on borrow.dzzh=reader.dzzh
where sf='研究生'
group by xm
order by count(*) desc,xm desc;
查询与李白全集同一个出书社的图书的书名(不包括李白全集)
select sm
from book
where cbs = (
select cbs
from book
where sm ='李白全集'
) and sm !='李白全集';
查询高于图书的平均售价(sj)的图书的书名和售价
select sm, sj
from book
where sj > (
select avg(sj)
from book);
查询售价最高的图书的条形码、书名和售价
select txm, sm, sj
from book
where sj = (
select max(sj)
from book);
查询售价最低的图书的条形码、书名和售价
select txm, sm, sj
from book
where sj = (
select min(sj)
from book);
第4关:多表子查询
查询曾经借过图书的读者的读者证号和姓名
select distinct reader.dzzh,xm
from reader,borrow
where reader.dzzh = borrow.dzzh
order by reader.dzzh asc;
查询曾经没有被借阅的图书的条形码和书名
select book.txm, sm
from book left join borrow on book.txm = borrow.txm
where jyrq is null;
查询与孙思旺借过相同图书的读者的读者证号和姓名,按读者证号升序排列
select distinct reader.dzzh, xm
from reader,borrow
where reader.dzzh = borrow.dzzh and txm in(
select borrow.txm
from reader,borrow,book
where reader.dzzh = borrow.dzzh and borrow.txm = book.txm and xm = '孙思旺'
) and xm !='孙思旺'
order by reader.dzzh asc;
查询借阅过李白全集的读者所借过的其他图书的书名 按书名升序排列
select distinct sm
from borrow,book
where borrow.txm = book.txm and dzzh in(
select dzzh
from borrow,book
where borrow.txm = book.txm and sm ='李白全集'
)and sm !='李白全集'
order by sm asc;
查询数据表tb_student,tb_class中学生姓名(studentName)和对应的班级名称(className)
select tb_student.name as studentName , tb_class.name as className
from tb_student join tb_class on tb_class.id = tb_student.class_id ;
select s1.name as studentName,score,s2.name as className
from tb_student as s1 ,tb_class as s2
where s1.class_id=s2.id and s1.score>90 order by score desc;
十. MySQL数据库 - 子查询
第1关:带比力运算符的子查询
子查询
嵌套在查询内部,且必须始终出现在圆括号内
分为四类:
标量子查询:返回单一值的标量,最简朴的情势;
列子查询:返回的结果集是 N 行一列;
行子查询:返回的结果集是一行 N 列;
表子查询:返回的结果集是 N 行 N 列。
eg: SELECT * FROM t1 WHERE col1=(SELECT col2 FROM t2);
select [聚合函数] 字段名 from 表名 [where 查询条件] [group by 字段名] [order by 字段名 排序方向]
查询表中至少有两门课程在90分以上的学生信息 select sno,count(*) from tb_grade where score>=90 group by sno having count(*)>=2;
查询表中平均成绩大于90分且语文课在95分以上的学生信息 select sno,avg(score) from tb_grade where sno in ( select sno from tb_grade where score>=95 and pno='语文') group by sno having avg(score)>=90;
十二. MySQL数据库 - 数据库和表的基本操纵(一)
第1关:检察表结构与修改表名
检察数据表基本结构 describe表名;
检察数据表详细结构 show create table表名;
修改表名 alter table旧表名 rename新表名;
把数据表tb_emp改名为jd_emp;
ALTER TABLE tb_emp RENAME jd_emp;
检察该数据库下数据表的列表;
SHOW TABLES;
检察数据表jd_emp的基本结构。
DESCRIBE jd_emp;
第2关:修改字段名与字段数据类型
修改字段名
alter table表名 change旧字段名 新字段名 新数据类型;
提示: 假如不需要修改字段的数据类型,可以把新字段的数据类型设置为和原来一样,不要空着它
修改字段数据类型
alter table表名 modify字段名 数据类型;
把数据表tb_emp的字段Id改名为prod_id,数据类型稳定
alter tabletb_emp change Id prod_id int(11);
把数据表tb_emp字段Name的数据类型改为varchar(30)
alter table tb_emp modifyName varchar(30);
第3关:添加与删除字段
添加字段
ALTER TABLE 表名 ADD 新字段名 数据类型 [束缚条件] [FIRST|AFTER] 已存在字段名;
在表的最后一列添加字段
不做[FIRST|AFTER]的位置阐明,在添加字段时MySQL会默认把新字段加入到表的最后一列。
eg: 字段prod_country添加到表Mall_products的最后一列
alter table Mall_productsadd prod_countryvarchar(30);
在表的第一列添加字段
做FIRST的位置阐明
eg: 字段prod_country添加到表Mall_products的第一列
alter table Mall_products add prod_country varchar(30) frist;
在表的指定列后添加字段
做AFTER的位置阐明,注明添加在哪个字段后面
eg:prod_country添加到表Mall_products的 prod_name字段的后面。
alter table Mall_products add prod_country varchar(30) after prod_name;
删除字段
alter table表名 drop字段名;
eg: 字段prod_price从表Mall_products中删除
alter table Mall_productsdrop prod_price;
在数据表tb_emp的Name字段后添加字段Country,数据格式为varchar(20)
alter table tb_emp add Country varchar(20) after Name;
删除数据表tb_emp中的字段Salary
alter table tb_emp drop Salary;
第4关:修改字段的排列位置
修改字段的排列位置
ALTER TABLE 表名 MODIFY 字段1 数据类型 FIRST|AFTER 字段2;
字段1指要修改位置的字段,FIRST与AFTER 字段2为可选参数
修改字段为表的第一个字段
做FIRST的位置阐明
eg: 把字段prod_price调整到表Mall_products的第一列
alter table Mall_products modify prod_price float first;
修改字段到表的指定列之后
做AFTER 字段2的位置阐明
eg: 字段prod_price调整到字段prod_country的后面
alter table Mall_productsmodify prod_price float after prod_country;
将数据表tb_emp的Name字段移至第一列,数据格式稳定
alter table tb_emp modify Name varchar(25) first;
将DeptId字段移至Salary字段的后边,数据格式稳定
alter table tb_emp modify DeptId INT(11) after Salary;
第5关:删除表的外键束缚
删除表的外键束缚
ALTER TABLE 表名 DROP FOREIGN KEY 外键束缚名;
删除数据表tb_emp的外键束缚emp_dept
alter table tb_emp drop foreign key emp_dept;
十三. MySQL数据库 - 数据库和表的基本操纵(二)
第1关:插入数据
为表的所有字段插入数据
INSERT INTO 表名 (字段名) VALUES (内容);
insert into MyUser(name,age) values('zhnagsan',18);
为表的指定字段插入数据
insert into MyUser(name) values('lisi'),('fawaikuangtu'),('zhangsan');
为空数据表tb_emp同时添加3条数据内容
insert into tb_emp (Id,Name,Deptid,Salary) values (1,'Nancy',301,2300.00),(2,'Tod',303,5600.00),(3,'Carly',301,3200.00);
第2关:更新数据
更新表中指定的内容
UPDATE 表名 SET 字段名1 = 内容1, 字段名2 = 内容2, 字段名3 = 内容3 WHERE 过滤条件;
eg: 表Mall_products2 中 Span 换成 Pakistan,地区代码换为 92 。 UPDATE Mall_products2 SET country_name = "akistan", country_id = 92 WHERE id = 2;
select * from table where xxx="xxx" limit 100,100; select * from table where xxx="xxx" limit 1000,100; select * from table where xxx="xxx" limit 10000,100; select * from table where xxx="xxx" limit 100000,100; select * from table where xxx="xxx" limit 1000000,100;
优化
直接定位到偏移量所在记录,先查询到偏移量位置,再进行分页: select * from table where xxx="xxx" and id>=( select id from table where xxx="xxx"limit 100000,1) limit 100;
select c.c_id 课程id, c_name 课程名, max(s_score) 最高分, min(s_score) '最低分', round(avg(s_score),2) '平均分', round((count(s_score>=60 or null)/count(s_score))*100,2) '及格率' from Score s,Course c where s.c_id=c.c_id group by s.c_id;





 akistan", country_id = 92
akistan", country_id = 92