
| 语法 / 语义 / 特性 | SPARQL | Cypher | Gremlin | PGQL | G-CORE | |
| 图模式匹配查询 | 语法 | CGP | CGP | CGP(无可选)1 | CGP | CGP |
| 语义 | 子图同态、包 2 | 无重复边、包 2 | 子图同态、包 2 | 子图同构 3、包 2 | 子图同态、包 2 | |
| 导航式查询 | 语法 | RPQ 超集 (增加反向边和属性集上的否定) | RPQ 子集 (* 只能作用在单边) | RPQ 超集 (增加通过表达式比力属性值) | RPQ 超集 (增加比力路径上的极点和边) | RPQ 超集 (增加复杂路径表达式) |
| 语义 | 恣意路径、集合 4 | 无重复边 5、包 2 | 恣意路径 6、包 2 | 最短路径 7、包 8 | 最短路径 9、包 2 | |
| 分析型查询 | 聚合函数 | 聚合函数 | 聚合函数、PageRank、PeerPressure 聚类 | 聚合函数 | 聚合函数 | |
| 查询可组合性 | 否 | 是 | 是 | 否 | 是 | |
| 数据更新语言 DML | CRUD10 | CRUD | 无 | 无 | CR | |
| 数据定义语言 DDL | 无 | 有 | 无 | 无 | 无 | |
| 实现系统 | Jena、RDF4J、gStore、Virtuoso 等 | Neo4j、AgensGraph 等 | TinkerTop 等 | Oracle PGX | 无 |



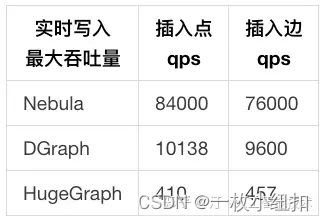
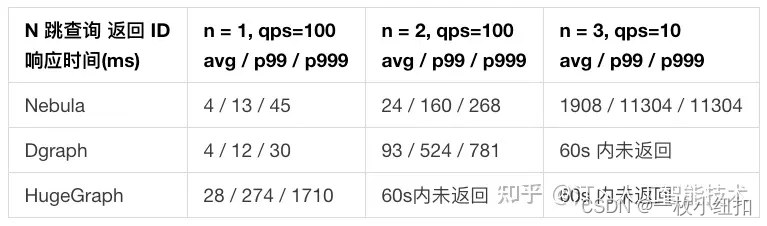
| 图形数据大小 | 平台 | 数据导入 | 一跳查询 | 两查询 | 共享好友查询 |
| 1000 万条边 | Neo4j | 26 秒 | 6.618 秒 | 6.644 秒 | 6.661 秒 |
| HugeGraph | 89 秒 | 16 毫秒 | 22 毫秒 | 72 毫秒 | |
| NebulaGraph | 32.63 秒 | 1.482 毫秒 | 3.095 毫秒 | 0.994 毫秒 | |
| 1 亿条边 | Neo4j | 1 分 21 秒 | 42.921 秒 | 43.332 秒 | 44.072 秒 |
| HugeGraph | 10 分 | 19 毫秒 | 20 毫秒 | 5 秒 | |
| NebulaGraph | 3 分 52 秒 | 1.971 毫秒 | 4.34 毫秒 | 4.147 毫秒 | |
| 10 亿条边 | Neo4j | 8 分 34 秒 | 165.397 秒 | 176.272 秒 | 168.256 秒 |
| HugeGraph | 65 分 | 19 毫秒 | 651 毫秒 | 3.8 秒 | |
| NebulaGraph | 29 分 35 秒 | 2.035 秒 | 22.48 毫秒 | 1.761 毫秒 | |
| 80 亿条边缘 | Neo4j | 1 小时 23 分钟 | 314.34 秒 | 393.18 秒 | 608.27 秒 |
| HugeGraph | 16 小时 | 68 毫秒 | 24 秒 | 541 毫秒 | |
| NebulaGraph | ~30 分钟 | 小于 1s | 小于 5 秒 | 小于 1s |



| 范例 | 名称 | 许可证 | 数据模子 / 存储方案 | 查询语言 | 是否活跃 |
| 基于关系 | 3store | 开源 | RDF 图 / 三元组表 | SPARQL | 否 |
| DLDB | 研究原型 | RDF 图 / 程度表 | SPARQL | 早期系统, 程度表存储方案的代表性系统 | |
| Jena | 开源 | RDF 图 / 属性表 | SPARQL | 主流的语义 Web 工具库、RDF 数据库和 OWL 推理工具 | |
| SW-Store | 研究原型 | RDF 图 / 垂直分别 | SPARQL | 科研原型系统, 垂直分别存储方案的代表性系统 | |
| IBM DB2 | 贸易 | RDF 图 / DB2RDF | SPARQL/ SQL | 支持 RDF 的主流贸易数据库 | |
| Oracle 18c | 贸易 | RDF 图 / 关系存储 | SPARQL/ PGQL | 支持 RDF 的主流贸易数据库 | |
| RDF 三元组库 | RDF4J | 开源 | RDF 图 / SAIL API | SPARQL | 是 |
| RDF-3X | 开源 | RDF 图 / 六重索引 | SPARQL | 科研原型系统, 六重索引存储方案的代表性系统 | |
| gStore | 开源研究原型 | RDF 图 / VS * 树 | SPARQL | 科研原型系统, 原生图存储, 利用了基于位串图存储技术 | |
| Virtuoso | 贸易 / 开源 | RDF 图 / 多模子肴杂 | SPARQL/ SQL | 语义 Web 项目常用的 RDF 数据库, 基于成熟的 SQL 引擎 | |
| AllegroGraph | 贸易 | RDF 图 / 三元组索引 | SPARQL | 对语义推理功能具有较为完善的支持 | |
| GraphDB | 贸易 | RDF 图 / 三元组索引 | SPARQL | 支持语义 Web 标准的主流产物, 支持 SAIL 层推理功能 | |
| BlazeGraph | 贸易 | RDF 图 / 三元组索引 | SPARQL/ Gremlin | 基于 RDF 三元组库的图数据库, 实现了 SPARQL 和 Gremlin | |
| StarDog | 贸易 | RDF 图 / 三元组索引 | SPARQL | 对 OWL2 推理机制具有良好的支持 | |
| 原生图数据库 | Neo4j | 贸易 / 开源 | 属性图 / 原生图存储 | Cypher | 是 |
| JanusGraph | 开源 | 属性图分布式存储 | Gremlin | 分布式图数据库, 存储后端与查询引擎分离, 实现了 Gremlin | |
| OrientDB | 贸易 | 属性图 / 原生图存储 | SQL/ Gremlin | 支持多模子的原生图数据管理系统, 对数据模式的灵活支持 | |
| Cayley | 开源 | RDF 图 / 外部存储 | Gremlin/ GraphQL | 轻量级开源图数据库, 易于扩展对新语言和存储后端的支持 | |
| 分布式系统与框架 | Sempala | 开源研究原型 | RDF 图 / 分布式存储 | SPARQL | 否 |
| TriAD | 开源研究原型 | RDF 图 / 分布式存储六重索引 | SPARQL | 基于 MPI 框架的异步通信协议 | |
| H2RDF+ | 开源研究原型 | RDF 图 / 分布式存储六重索引 | SPARQL | 基于 HBase 构建六重索引 | |
| S2RDF | 开源研究原型 | RDF 图 / 分布式存储垂直分别 | SPARQL | 基于 Spark 框架创建大量索引 | |
| Stylus | 开源研究原型 | RDF 图 / 分布式存储属性表优化 | SPARQL | 基于分布式内存键值库的 RDF 三元组库 | |
| Apache Rya | 开源 | RDF 图 / 分布式存储三元组索引 | SPARQL | 基于列存储 Accumulo 的 RDF 三元组库 | |
| Cypher for Apache Spark | 开源 | 属性图 / 分布式存储 DataFrame | Cypher | 基于 Spark 框架的 Cypher 引擎 |
| 特性 | JanusGraph | Neo4j | Dgraph | NebulaGraph |
| 初次发布 | 2017 年 | 2007 年 | 2016 年 | 2019 年 |
| 开发语言 | Java | Java | Go | C++ |
| 开源 | 是 | 是 | 是 | 是 |
| 属性图模子 | 完整的属性图模子 | 完整的属性图模子 | 类 RDF 存储 | 完整的属性图模子 |
| 架构 | 分布式 | 单机 | 分布式 | 分布式 |
| 存储后端 | Hbase、Cassandra、 BerkeleyDB | 自定义文件格式 | 键值数据库 BadgerDB | 键值数据库 RocksDB |
| 高可用性 | 支 持 | 不支持 | 支持 | 支持 |
| 高可靠性 | 支 持 | 不支持 | 支持 | 支持 |
| 一致性协议 | Paxos 等 | 无 | RAFT | RAFT |
| 跨数据中心复制 | 支 持 | 不支持 | 支持 | 不支持 |
| 事件 | ACID 或 BASE | 完全的 ACID | 0mid 修改版 | 不支持 |
| 分区策略 | 随机分区,支持显式指定分区策略 | 不支持分区 | 主动分区 | 静态分区 |
| 大数据平台集成 | Spark、Hadoop、Giraph | Spark | 不支持 | Spark、Flink |
| 查询语言 | Gremlin | Cypher | GraphQL | nGQL |
| 全文检索 | ElasticSearch、Solr、Lucene | 内置 | 内置 | ElasticSearch |
| 多个图 | 支持创建恣意多图 | 一个实例只能有一个图 | 一个集群只能有一个图 | 支持创建恣意多图 |
| 属性图模式 | 多种束缚方法 | 可选模式束缚 | 无模式 | 逼迫模式束缚 |
| 客户端协议 | HTTP、WebSockets | HTTP、BOLT | HTTP、gRPC 等 | HTTP |
| 客户端语言 | Java、Python、C#、Go、Ruby 等 | Java、Python、Go 等 | Java、Go、Python、等 | Python、Java 等 |
| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |