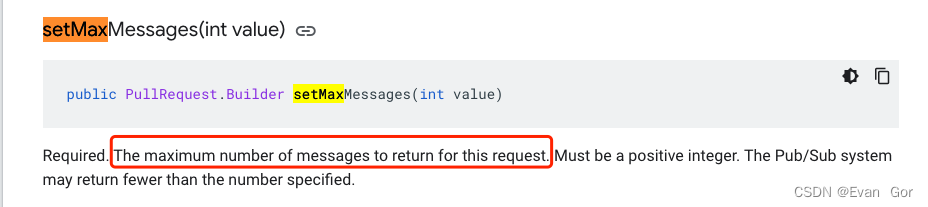
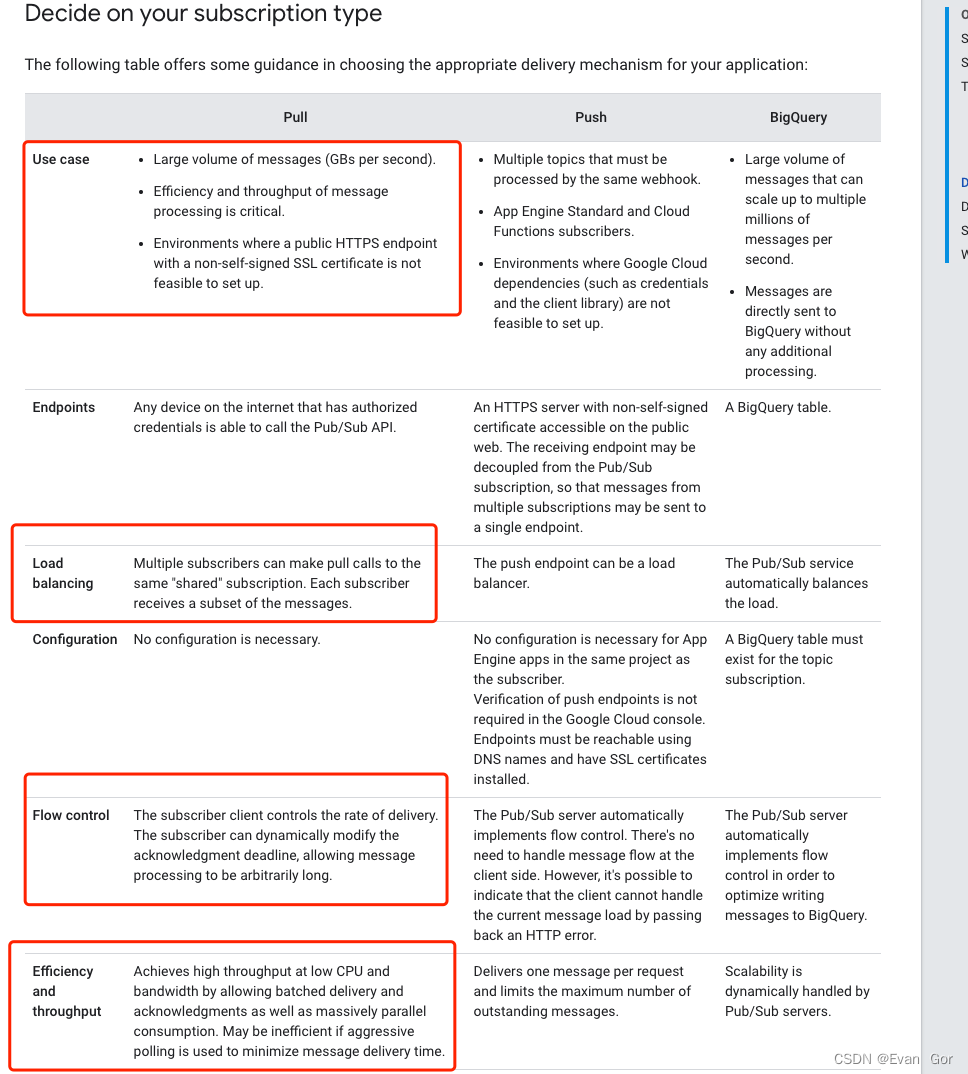
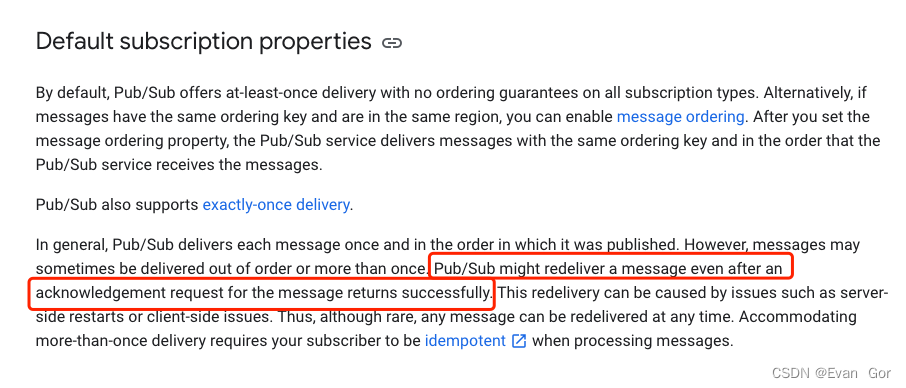
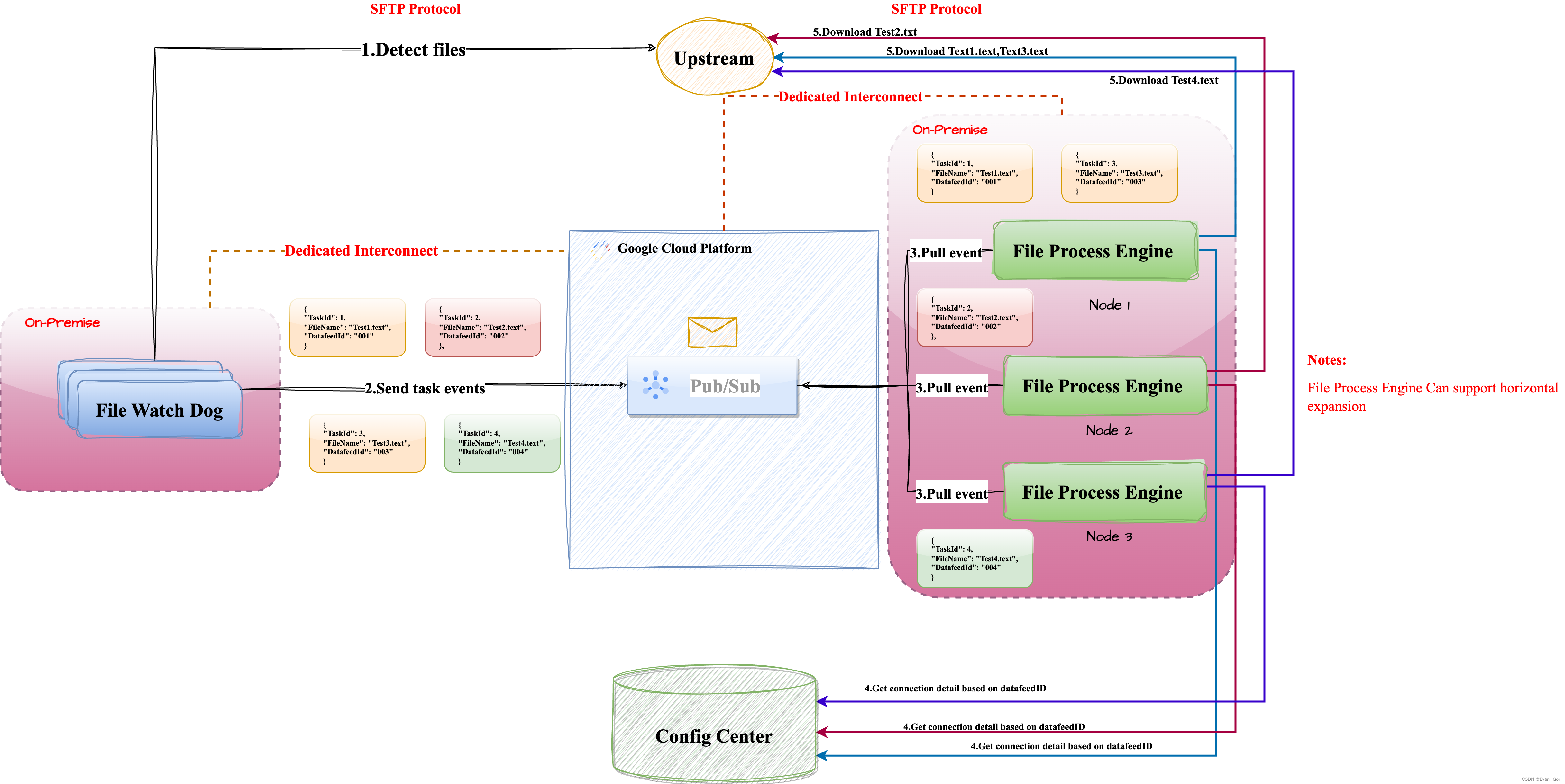
目前老梁团队负责的Global Data Integration Platform每天有大量文件需要从来自不同地区的上游下载文件并进行处置惩罚后再发送到不同下游。老梁的数据集成平台集群有6个服务器节点,老梁渴望所有呆板的资源都能利用上,提升大量文件并行处置惩罚本领,并且不同呆板节点的任务必须不能重复,否则大概造成文件下载或处置惩罚失败。
原有的服务是使用Quarz集群,通过定时调度去下载,但是Quartz调度框架固然自己支持负载均衡,但是其Cluster每个节点都不是均衡分配任务,假如某一节点具有竞争资源上风,有机会一直持有任务,导致其他节点空闲下来,服务器大概某资质源消耗过大而导致宕机,这并不是老梁想要的结果。后来也尝试使用生产者消费者模型,通过F5负载均衡+API关照+异步回调方式后,服务多节点并行处置惩罚本领有所增强,但由于使用Http方式进行通信导致服务之间存在直接依靠,当消费者服务进行重启或者停机,存在生产者API关照失败的大概,需要做额外的补偿处置惩罚。如下图所示: 生产者消费者模型:
办理思绪
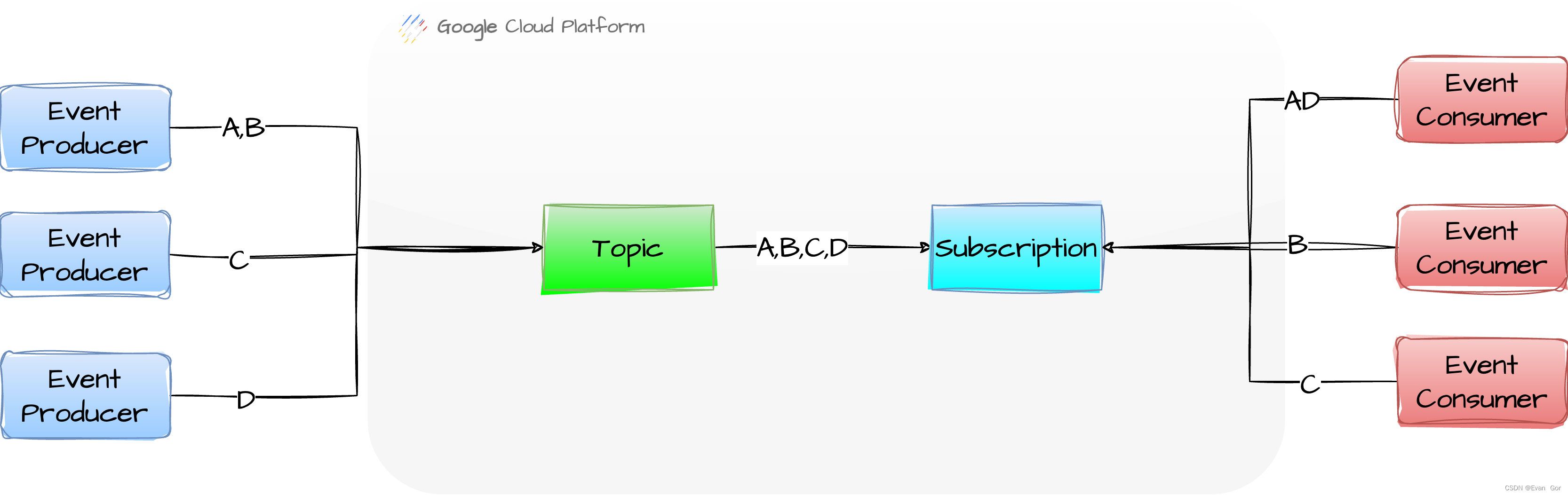
目前老梁公司已经完成了谷歌云和公司机房的网络搭建,并且公司的自有数据中央跟谷歌云可以直接通过谷歌的Dedicated Interconnect服务,也就是可以通过专线直接进行连接。固然老梁的数据集成平台还部署在自有数据中央,但相对于文件下载的时间和速度消耗,谷歌云上的服务通过专线进行通信所带来的性能消耗几乎可以忽略(大约几百毫秒),老梁公司的架构战略方向是优先使用云组件,减少On-Premise部署。末了老梁选择采用谷歌云Pub/Sub服务作为变乱消息服务,利用Pub/Sub高可用、使用简朴并天然支持多消息并行传输的特性,来对现有的数据集成平台进行改造。 Pub/Sub先容:
Pub/Sub 是一种筹划为高度可靠且可伸缩的异步消息传递服务。该服务以十多年来许多 Google 产品都在依靠的核心 Google 基础架构组件为基础而构建。其实可以理解成云上的Kafka。官网:https://cloud.google.com/pubsub/architecture?hl=zh-cn