总结而言,判别模子和天生模子是两种差别的机器学习方法。判别模子通过观测值预测标签,而天生模子通过学习数据分布来天生新的观测值。
天生模子估计 p ( x ) p(x) p(x),即天生观测值 x x x 的概率。也就是说,天生模子旨在对观测值 x x x 进行建模,从所学分布中进行采样可以天生新的观测值。
2.2 条件天生模子
也可以构建天生模子来建模条件概率 p ( x ∣ y ) p(x|y) p(x∣y),即观察到具有特定标签 y y y 的观测值 x x x 的概率。例如,假如数据集包罗差别范例的水果,可以训练天生模子仅仅天生苹果图像。
需要注意的,即使我们能够构建一个完善的判别模子识别莫奈的画作,但它仍旧无法创作一幅具备莫奈风格的画作,它只是被训练用于输出关于现有图像的类别概率。相反,天生模子被训练用于从该模子中进行采样,以天生具有高概率属于原始训练数据集的图像。
2.3 天生模子的发展
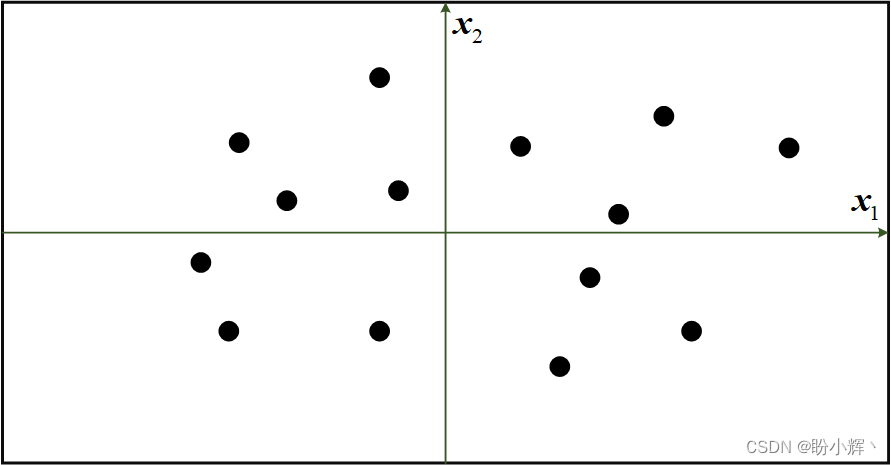
起首,我们将利用一个简单示例展示天生模子。在二维空间中,利用 P d a t a P_{data} Pdata 规则天生如下图所示点集,我们的目标是得到二维空间中新的点 x = ( x 1 , x 2 ) x=(x_1,x_2) x=(x1,x2),使其看起来像是由相同规则天生的。
我们可以根据已有数据点的知识选择一个位置,构建模子 p m o d e l p_{model} pmodel,用于估计该点可能出现的位置。此时, p m o d e l p_{model} pmodel 是 p d a t a p_{data} pdata 的一个估计。 p m o d e l p_{model} pmodel 可能如下图中的矩形框所示,点只可能出现在框内,而框外的地区则可能没有任何点。
为了天生一个新的观测值,可以在框内随机选择一个点,或者说从分布 p m o d e l p_{model} pmodel 中进行采样。这就可以视为一个简单的天生模子,我们利用训练数据(黑色点)构建了一个模子(橙色地区),可以从中进行采样,天生看起来属于训练集的点。
3.2 天生模子框架
我们可以通过以下框架来表达我们构建天生模子的目标:
准备一组观测数据 X X X
假设这些观测数据是根据某一分布 p d a t a p_{data} pdata 天生的
目标是构建天生模子 p m o d e l p_{model} pmodel,以近似 p d a t a p_{data} pdata,假如实现了此目标,就可以从 p m o d e l p_{model} pmodel 中进行采样,天生看起来像是从 p d a t a p_{data} pdata 中抽取的观测数据
因此, p m o d e l p_{model} pmodel 需要包罗以下属性:
准确性:假如 p m o d e l p_{model} pmodel 天生的观测样本准确性较高,则观测样本应该看起来像是从 p d a t a p_{data} pdata 中抽取的;假如 p m o d e l p_{model} pmodel 天生的观测样本准确性较低,则观测样本不应该看起来像是从 p d a t a p_{data} pdata 中抽取的
天生性:能够简单地从 p m o d e l p_{model} pmodel 中进行采样天生新的观测样本
表现性:能够理解 p m o d e l p_{model} pmodel 如何表现数据中差别的高级特征
接下来,我们利用简单数据天生分布 p d a t a p_{data} pdata,并利用上述框架进行处理,如下图所示,数据天生规则设定命据样本在蓝色地区匀称分布,且数据样本不能出现在黄色地区。
我们利用的模子 p m o d e l p_{model} pmodel (灰色地区)是对真实数据天生分布 p d a t a p_{data} pdata 的简化模子。数据样本 A、B 和 C 是模子 p m o d e l p_{model} pmodel 模仿 p d a t a p_{data} pdata 天生的数据:
点 A 是由模子天生的观测样本,但看起来并不像是由 p d a t a p_{data} pdata 天生的,因为它位于黄色地区中
点 B 无法由模子天生,因为它位于灰色地区之外,因此,可以说 B 为模子无法在整个可能性范围内的天生观测样本
点 C 是一个合理的数据样本点,因为它既可以由模子 p m o d e l p_{model} pmodel 天生,也可以由真实分布 p d a t a p_{data} pdata 天生
尽管模子 p m o d e l p_{model} pmodel 存在缺陷,但该模子易于进行抽样,因为它是一个灰色框内的匀称分布,我们可以简单地从该框中随机选择一个点来进行抽样。
别的,天生模子 p m o d e l p_{model} pmodel 是对底层复杂分布的简单表现,但其也捕捉了一些底层高级特征。真实分布被分别为多个蓝色地区和黄色地区,这相称于本例的高级特征,固然模子 p m o d e l p_{model} pmodel 也捕捉到这一高级特征,但其将其近似为单个蓝色地区。
上述示例演示了天生模子的基本概念,固然天生模子是一个丰富多彩的领域,且题目的定义与处理也多种多样,但处理天生模子题目时基本遵照上述基本框架。
4. 表现学习
对于人类而言,很明显可以利用圆柱体的高度和半径这两个特征唯一的表现这些圆柱体。也就是说,我们可以将每个圆柱体的图像转换为两维潜空间中的一个点,即使训练集中的图像是以高维像素空间表现的。这也意味着我们可以通过将适当的映射函数 f 应用于潜空间中的新点来天生不在训练集中的圆柱体图像。
对于机器而言,利用较简单的潜空间来描述原始数据集并非易事,机器起首需要确定高度和半径是最得当描述该数据集的两个潜空间维度,然后学习能够将该空间中的点映射到灰度圆柱体图像的映射函数 f f f。机器学习(尤其是深度学习)能够训练机器在没有人类引导的情况下学习这些高度复杂的映射函数。
天生模子与概率分布的统计建模密切相关,因此,需要了解一些核心统计概念,用于表明每个天生模子的理论配景。为了充分理解要解决的任务,需要创建对基本概率理论的扎实理解,以理解差别范例的天生模子。 样本空间
样本空间 (sample space) 是观测样本 x \textbf x x 可以获取的所有值的完整集合。例如,在上述数据分布示例中,样本空间图像中的横纵坐标 ( x , y ) (x, y) (x,y) 组成。例如, x = ( 40 , 10 ) \textbf x=(40,10) x=(40,10) 是样本空间中属于真实数据天生分布的一个点。 概率密度函数
概率密度函数( probability density function,或简称密度函数)是一种将样本空间中的点 x \textbf x x 映射到 0 到 1 之间的数值的函数 p ( x ) p(\textbf x) p(x)。密度函数在样本空间中所有点上的积分必须等于 1,以确保其是一个明白定义的概率分布。
在上述数据分布示例中,天生模子的密度函数在灰色框之外为 0,在灰色框内为常数,因此密度函数在整个样本空间上的积分等于 1。
固然只有一个真实的密度函数 p d a t a ( x ) p_{data}(\textbf x) pdata(x) 能够真正天生可观测数据集,但有无穷多个密度函数 p m o d e l ( x ) p_{model}(\textbf x) pmodel(x) 可以用来估计 p d a t a ( x ) p_{data}(\textbf x) pdata(x)。为了能够找出合适的 p m o d e l ( x ) p_{model}(\textbf x) pmodel(x),可以利用参数化建模 (parametric modeling) 技能。 参数化建模
参数化建模 (parametric modeling) 是一种用来寻找合适 p m o d e l ( x ) p_{model}(\textbf x) pmodel(x) 的方法。参数模子 p θ ( x ) p_θ(\textbf x) pθ(x) 是一系列密度函数,可以通过有限数量的参数 θ θ θ 来描述。
假如我们将匀称分布假设为模子簇,那么在上述数据分布示例中,我们可以绘制的所有可能框的集合就是参数化模子的一个例子。在这种情况下,我们需要四个参数:方框的左下角 ( θ 1 , θ 2 ) (θ_1, θ_2) (θ1,θ2) 和右上角 ( θ 3 , θ 4 ) (θ_3, θ_4) (θ3,θ4) 的坐标。
因此,该参数模子中的每个密度函数 p θ ( x ) p_θ(\textbf x) pθ(x) (即每个方框)可以由四个数字 θ = ( θ 1 , θ 2 , θ 3 , θ 4 ) θ=(θ_1, θ_2, θ_3, θ_4) θ=(θ1,θ2,θ3,θ4) 唯一的表现。 似然函数
给定某个观测样本 x \textbf x x,参数集 θ θ θ 的似然函数 L ( θ ∣ x ) L(θ|\textbf x) L(θ∣x) 是一个量度 θ θ θ 在给定观测点 x \textbf x x 处的合理性的函数,其定义如下:
L ( θ ∣ x ) = p θ ( x ) \mathscr{L}(θ|\textbf x) = p_θ(\textbf x) L(θ∣x)=pθ(x)
也就是说,给定某个观测样本 x \textbf x x, θ θ θ 的似然性表现用参数 θ θ θ 表现点 x \textbf x x 上的密度函数值,假如我们有一个完整的独立观测数据集 X \textbf X X,则可以写成:
L ( θ ∣ X ) = Π x ∈ X p θ ( x ) \mathscr L(θ|\textbf X) = \underset {\textbf x \in \textbf X} {\Pi}p_θ(\textbf x) L(θ∣X)=x∈XΠpθ(x)
由于计算 0 到 1 之间大量项的乘积可能非常困难,因此通常利用对数似然度ℓ取代:
ℓ ( θ ∣ x ) = ∑ x ∈ X l o g p θ ( x ) \ell (θ|\textbf x) = \sum_{\textbf x\in \textbf X} log p_θ(\textbf x) ℓ(θ∣x)=x∈X∑logpθ(x)
在上述数据分布示例中,只覆盖图像左半部分的灰色框的似然性为 0,因为我们观察到的数据点位于图像右半部分,因此该框不可能天生数据集。图像中的灰色框的似然性为正数,因为在该模子下所有数据点的密度函数都是正数。
似然函数的此种定义方式是具有统计意义的,但我们也可以直观地理解这个定义。我们可以简单的将参数集 θ θ θ 的似然函数定义为:在由参数集 θ θ θ 定义的模子中,观测到数据的概率。
需要注意的是,似然函数是参数的函数,而不是数据的函数。不应将其表明为给定参数集正确的概率,换句话说,它不是参数空间上的概率分布(即在参数方面不会求和/积分为1)。
直观而言,参数化建模应该专注于找到最优的参数 θ ^ \hat θ θ^,以最大化数据集 X \textbf X X 观测值的似然性。 最大似然估计
最大似然估计 (maximum likelihood estimation) 是一种估计密度函数 p θ ( x ) p_θ(\textbf x) pθ(x) 的参数集 θ ^ \hat θ θ^ 的方法,该参数集能够最合理的表明观测数据集 X \textbf X X,更正式的定义如下:
θ ^ = a r g m a x θ L ( θ ∣ X ) \hat θ = \underset {θ} {argmax}\mathscr L(θ|\textbf X) θ^=θargmaxL(θ∣X)
θ ^ \hat θ θ^ 也被称为最大似然估计 (maximum likelihood estimate, MLE)。在上述数据分布示例中,MLE 是包罗训练集中所有点的最小矩形。
神经网络通常需要最小化损失函数,等价的,我们可以找到使负对数似然最小化的参数集:
θ ^ = a r g m i n θ − L ( θ ∣ X ) = a r g m i n θ − l o g p θ ( x ) \hat θ = \underset {θ} {argmin} -\mathscr L(θ|\textbf X) = \underset {θ} {argmin} -log p_θ(\textbf x) θ^=θargmin−L(θ∣X)=θargmin−logpθ(x)
天生模子可以视为最大似然估计的一种形式,此中参数 θ θ θ 是模子中包罗的神经网络的权重。我们试图找到这些参数的值,以最大化观察到的数据的似然性(或等价地,最小化负对数似然)。
然而,在高维题目中,直接计算 p θ ( x ) p_θ(\textbf x) pθ(x) 通常是不可能的,因为它过于复杂的,差别范例的天生模子采用差别的方法来解决这一题目。
6. 天生模子分类
尽管所有范例的天生模子终极都旨在解决同一任务,但它们在对密度函数 p θ ( x ) p_θ(\textbf x) pθ(x) 进行建模时采取了差别的方法。广义上说,有以下三种方法:
显式地对密度函数进行建模,但通过肯定方式对模子进行约束,使密度函数可计算
显式地对密度函数的可计算近似进行建模
通过直接天生数据的随机过程来隐式地对密度函数进行建模
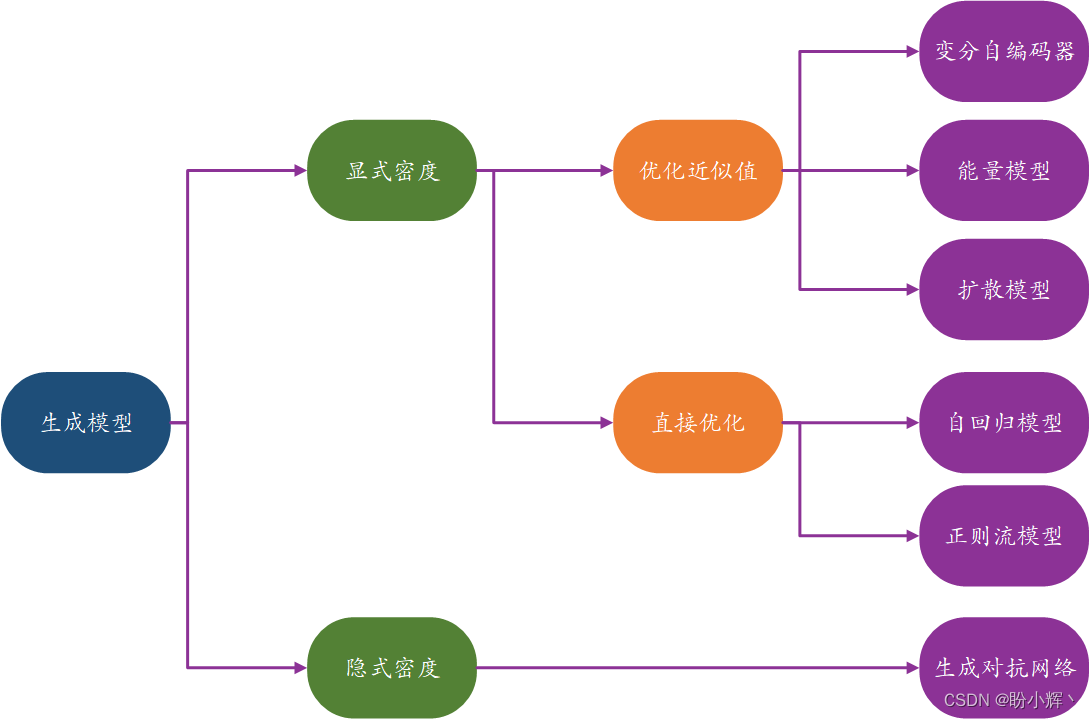
天生模子分类方式如下所示,这些模子簇并不是互斥的,有很多模子混淆利用了两种及以上的差别方法。
我们可以起首将模子分为显式建模概率密度函数 p ( x ) p(\textbf x) p(x) 的模子和隐式建模概率密度函数的模子。
隐式密度模子并不直接估计概率密度,而专注于直接天生数据的随机过程。天生对抗网络 (Generative Adversarial Networks, GAN) 是典型的隐式天生模子。显式密度模子可以进一步分为直接优化密度函数(可计算密度模子)和优化其近似值的模子。
可计算密度模子通过对模子架构进行约束,使得密度函数具有易于计算的形式。例如,自回归模子对输入特征进行排序,以便可以按序天生输出,比如逐字天生或逐像素天生。正则流模子将一系列可计算的可逆函数应用于简单分布,以天生更复杂的分布。
近似密度模子包括变分自编码器,引入潜变量并优化团结密度函数的近似值。能量模子也利用近似方法,但是其通过马尔可夫链采样而非变分方法。扩散模子通过训练模子渐渐去噪给定图像来近似密度函数。
小结