<description>Whether HiveServer2 Active/Passive High Availability be enabled when Hive Interactive sessions are enabled.This will also require hive.server2.support.dynamic.service.discovery to be enabled.</description>
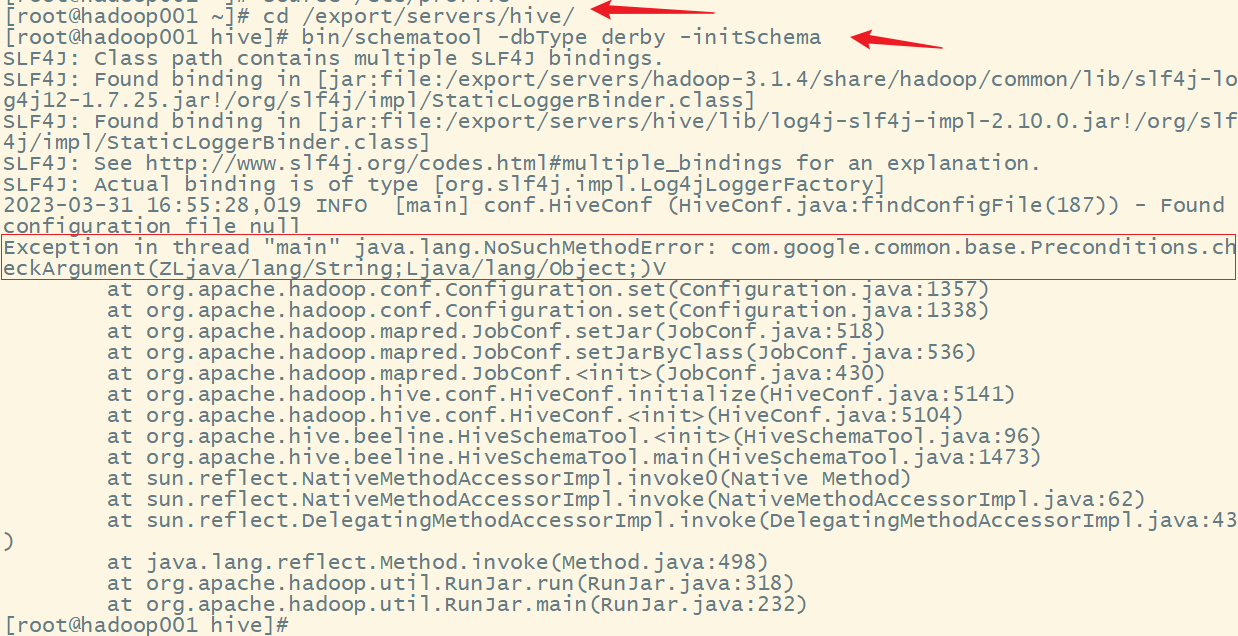
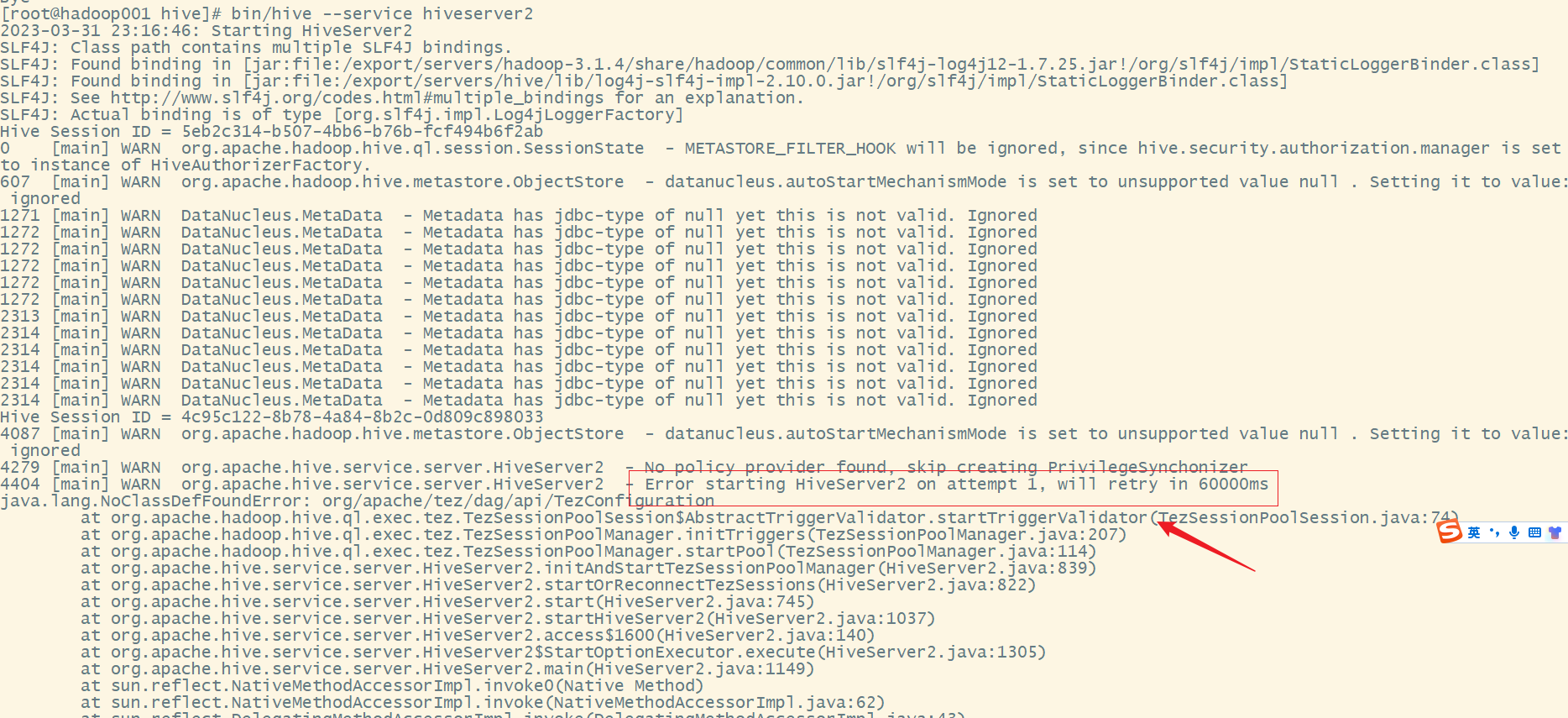
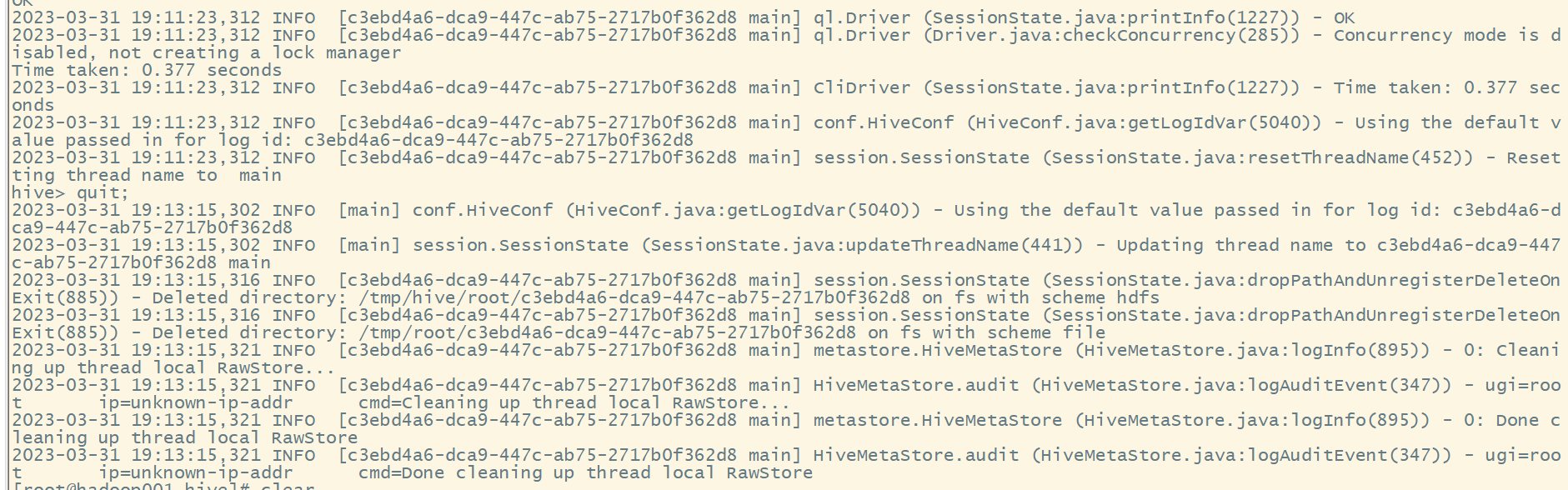
Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.StatsTask
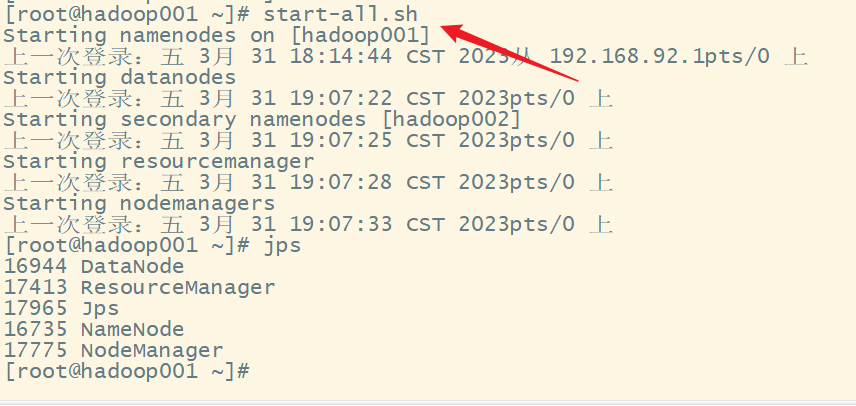
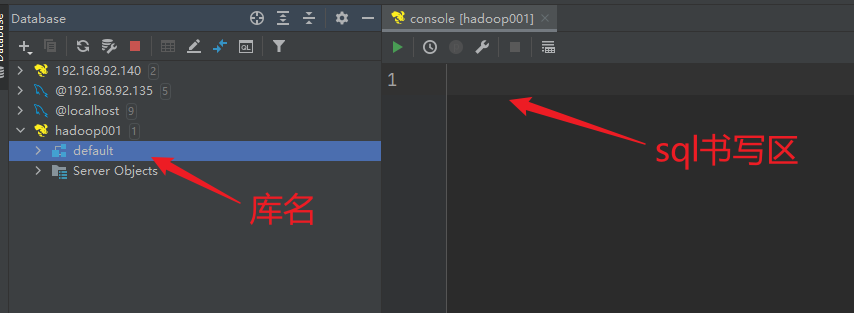
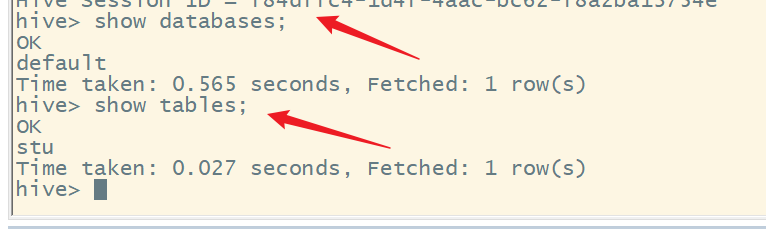
执行以下下令没有题目:
show databases;
show tables;
select * from 表名;
复制代码
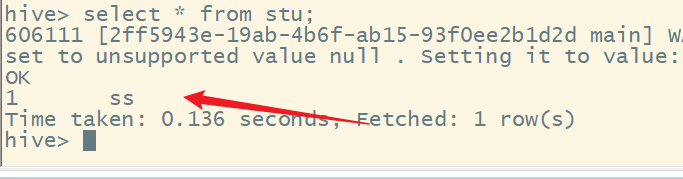
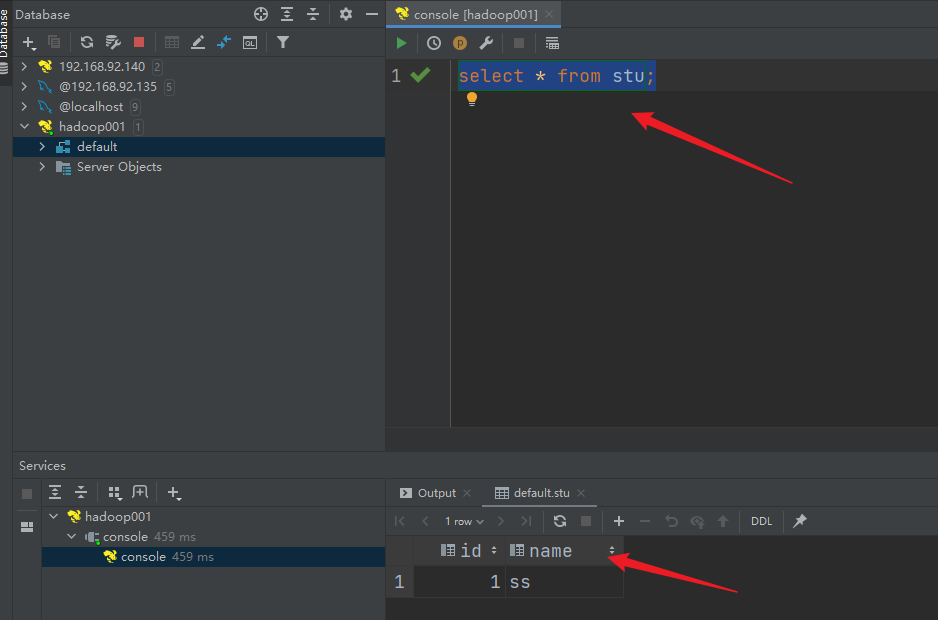
插入第一条数据没有题目,但是插入第二条数据出现题目:
Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.StatsTask
复制代码
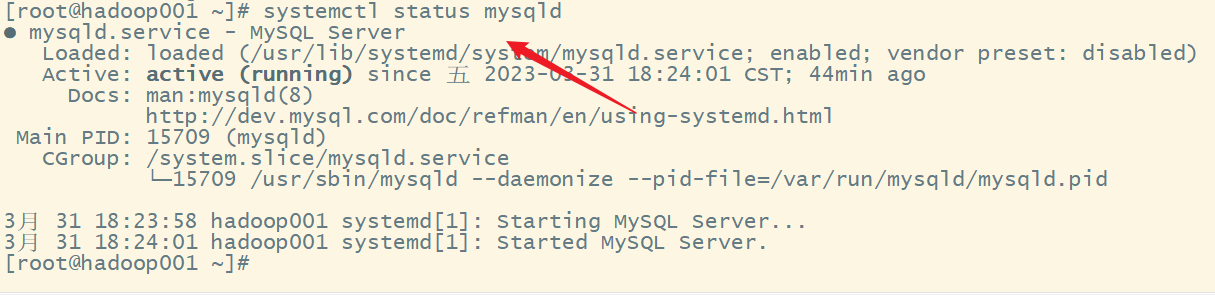
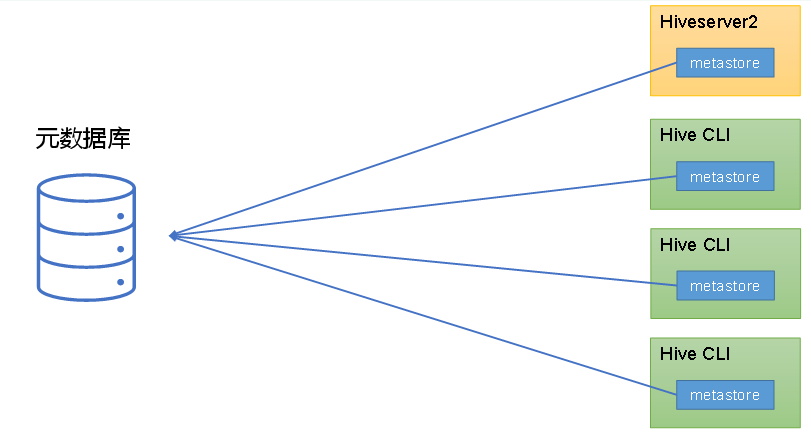
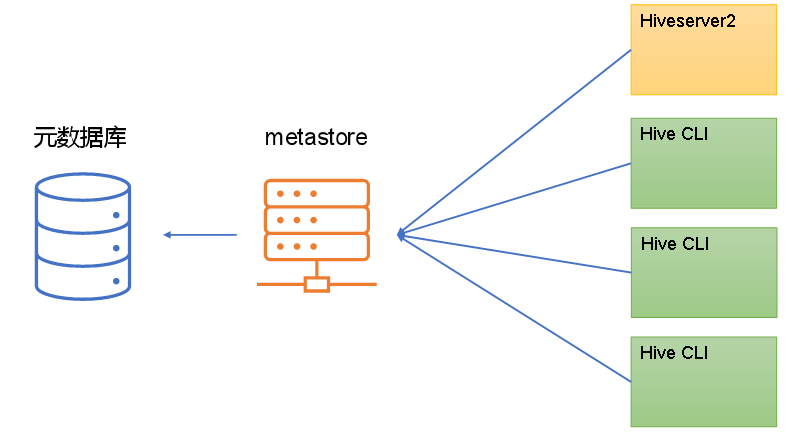
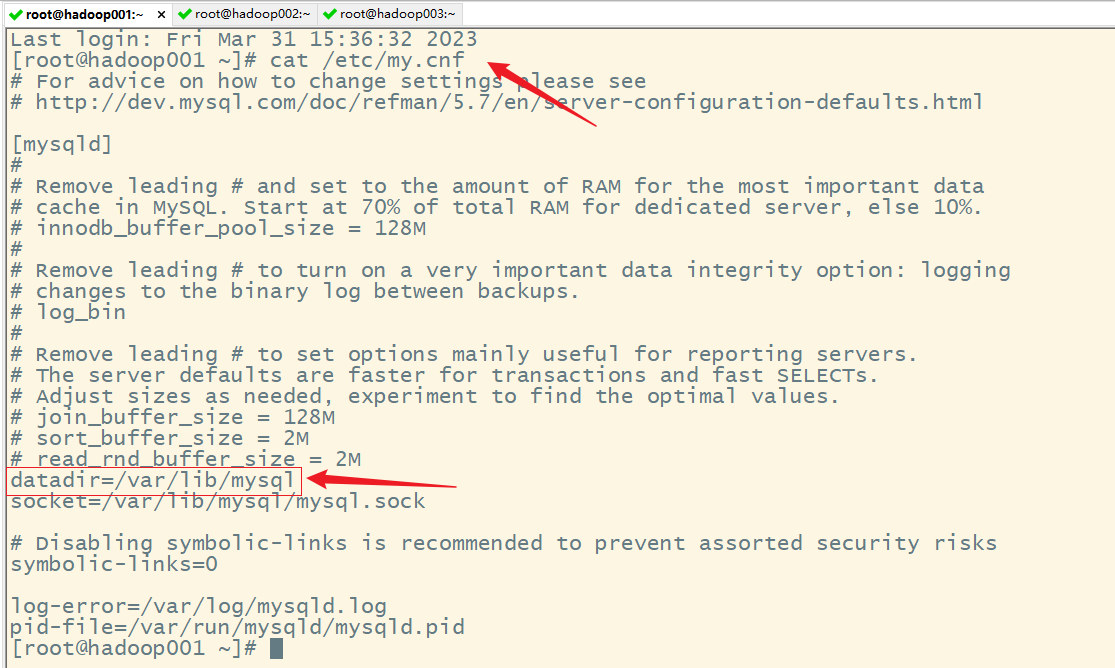
题目缘故原由:大概是由于MySQL数据库和元数据库在同一台假造机上。
解决方案:不配置元数据服务即可。
参考文章:
MySQL启动时出现initialize specified but the data directory has files in it. Aborting题目
Centos7安装hive3.1.2遇到报错
hive启动日记关闭解决方法
Hive数据堆栈的安装配置