标题: NL2SQL基础系列(1):业界顶尖排行榜、权势巨子测评数据集及LLM大模型(Spider v [打印本页] 作者: 魏晓东 时间: 2024-6-15 01:17 标题: NL2SQL基础系列(1):业界顶尖排行榜、权势巨子测评数据集及LLM大模型(Spider v NL2SQL基础系列(1):业界顶尖排行榜、权势巨子测评数据集及LLM大模型(Spider vs BIRD)全面临比优劣分析[Text2SQL、Text2DSL]
NL2SQL的汗青要追溯到1973年,Woods等人开发了一个名为LUNAR的体系,紧张用来回答从月球带回来的岩石相干的问题。1978年,Hendrix计划了一个名叫LIFER/LADDER的接口,可以通过自然语言查询数据库。但是上面提到的体系都是针对特定数据库开发的,而且只支持单表操作。2008年,Siasar等人基于句法和语义知识的基本概念提出了专家体系,并提出一个可以或许从多个效果中选择一个符合查询语句的算法。2010年,Rao等人提出了一个包含简朴和隐式查询的体系。2013年,Chaudhari利用原型技能实现了一个可以或许处理简朴查询和聚合函数的体系。虽然这些体系可以或许天生不同的查询语句,但依然无法支持多表关联的问题。2014年,Ghosh等人基于Chaudhari的研究结果,在其基础上又开发了一个自动查询天生器,它采用语音或自然语言文本作为输入,支持简朴的嵌套查询和聚合操作,同时体系还可以或许处理那些明确指出的属性。同年,Reinaldha和Widagdo利用了不同的方法来研究用户不同情势的输入,他们采用语义规则来找出问题中出现的词与数据库中的属性之间的关系。2015年,Palakurthi等人提供了与属性类型和分类特性相干的信息,描述了不同属性出现在句子中的处理方式也是不一样的。2016年,Ghosal等人提出了一个体系,可以或许很好地处理多表简朴查询,不外体系利用的数据字典有限。同年,Kaur and J, Jan 强化了体系的简朴查询和毗连操作,但不支持聚合函数、GROUPBY和HAVING等高级子句。Singh and Solanki也提出了一种将自然语言转为sql查询的算法。他们利用动词表、名词表和规则将属性和表映射到句子中的单词,体系还机敏地处理了文本的含糊输入。2017年,Google开发了Analyza体系,一个以自然语言为人机交互的接口的体系,支持用户用自然语言做数据探索与数据分析。该体系已在Google两个产物中投入利用,一是Online Sheet产物的QA问答模块,二是提供了一个库存和收入数据数据库的一个访问入口。同年,Sukthankar, Nandan等人开发了nQuery体系,一个自然语言到SQL的查询天生器,支持聚合函数,以及where子句中的多个条件、高级子句(如order by、group by和having)操作。2018年,Utama, Prasetya等人开发了DBPal工具,一个面向数据库的端到端的自然语言接口。DBPal紧张有两大特性,一是采用深度模型将自然语言语句转为SQL,二是在用户不知道数据库模式和查询特性的环境下,支持短语提问,同时支持用户查询扩展提示,有助于提高查询效果。
1.2 NL2SQL 业内环境
(2023-International Conference on Very Large Data Bases, VLDB, CCF-A)A survey on deep learning approaches for text-to-SQL [paper]
(2022-IEEE Transactions on Knowledge and Data Engineering, TKDE, CCF-A) A Survey on Text-to-SQL Parsing: Concepts, Methods, and Future Directions [paper]
(2022-International Conference on Computational Linguistics, COLOING, CCF-B) Recent Advances in Text-to-SQL: A Survey of What We Have and What We Expect [paper]
(2022-arXiv)Deep Learning Driven Natural Languages Text to SQL Query Conversion: A Survey [paper]
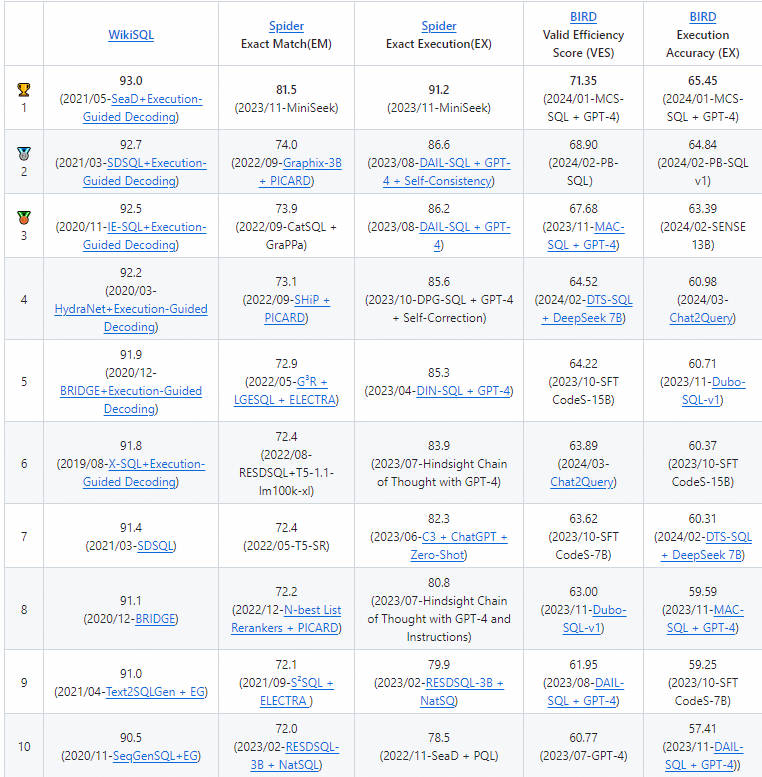
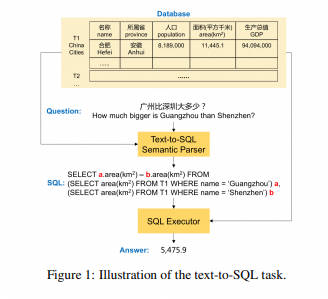
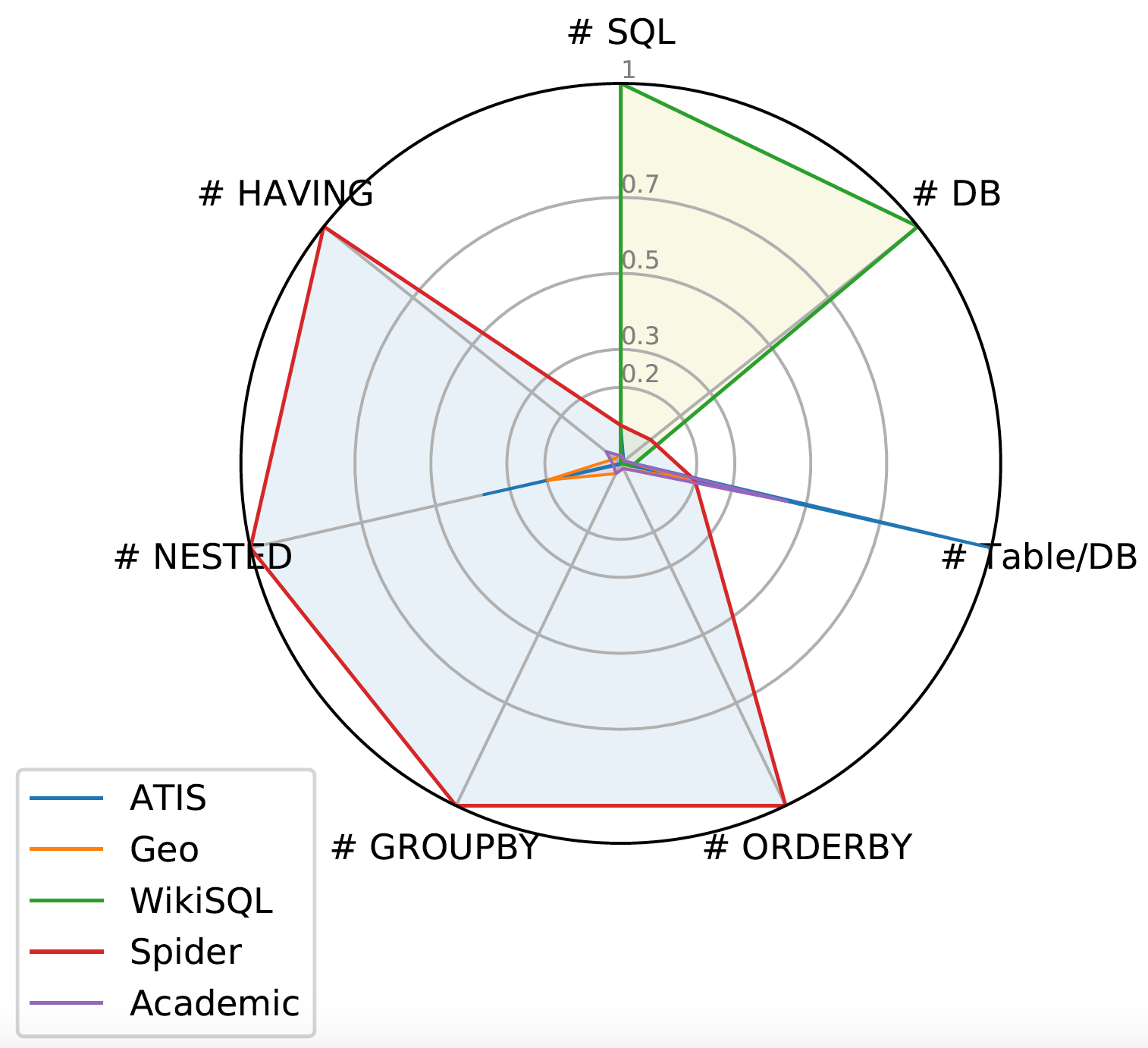
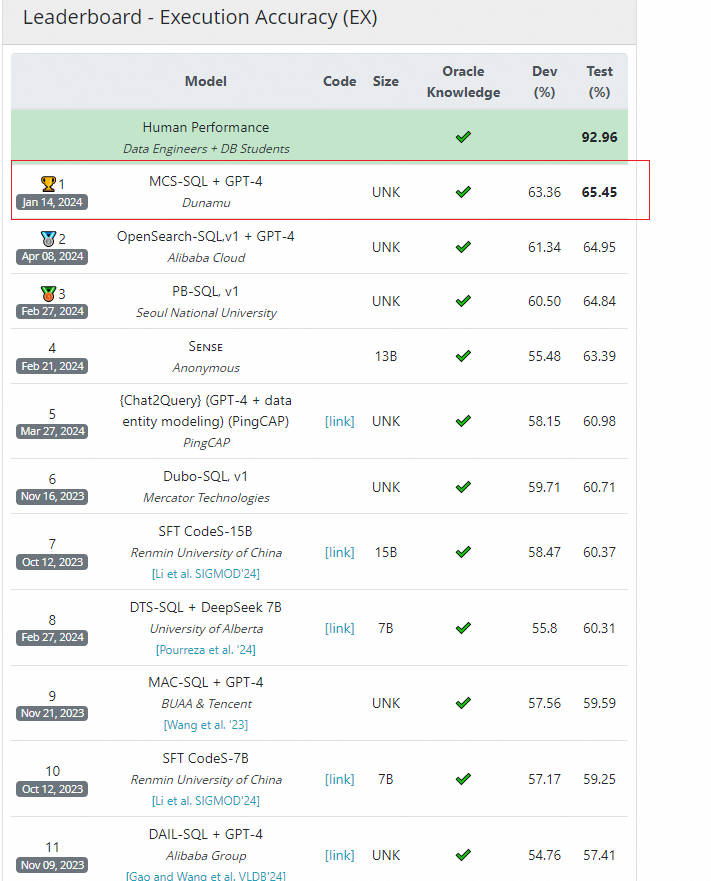
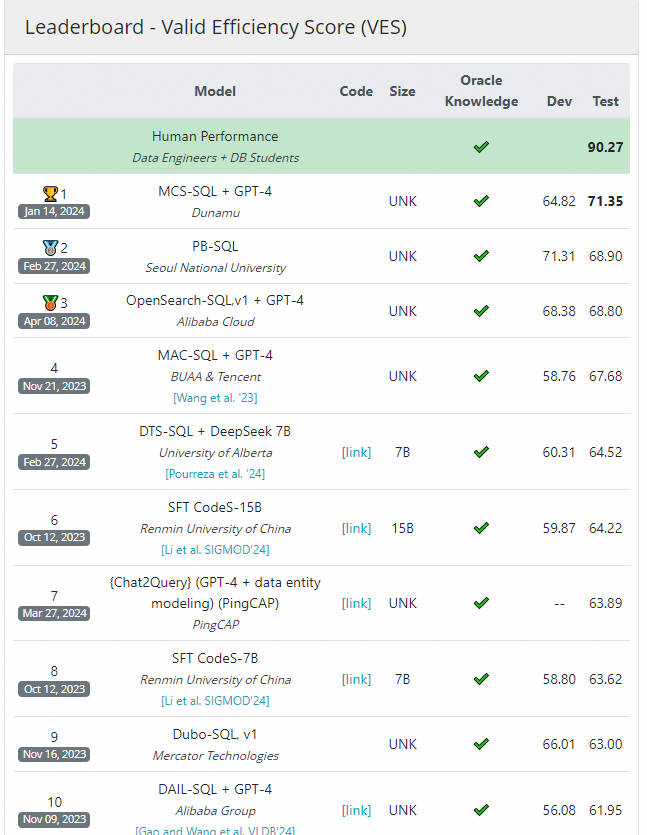
Spider 1.0与大多数先前的语义解析任务不同,因为:ATIS、Geo、Academic:它们各自仅包含一个数据库,SQL查询数量有限,且练习和测试集中SQL查询完全雷同。WikiSQL:SQL查询和表的数量明显增多。但所有SQL查询都很简朴,每个数据库仅是单一表,没有外键。Spider 1.0在图中占据最大面积,是首个复杂且跨领域的语义解析和文本到SQL数据集! Leaderboard - Execution with Values
Leaderboard - Exact Set Match without Values
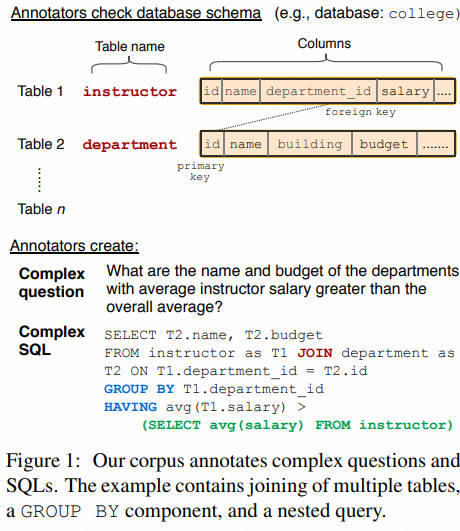
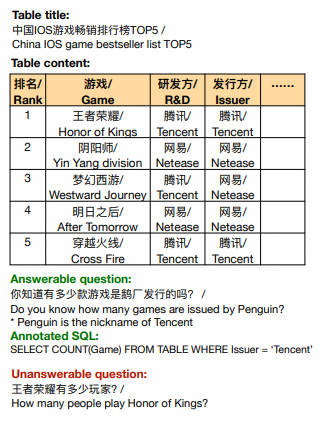
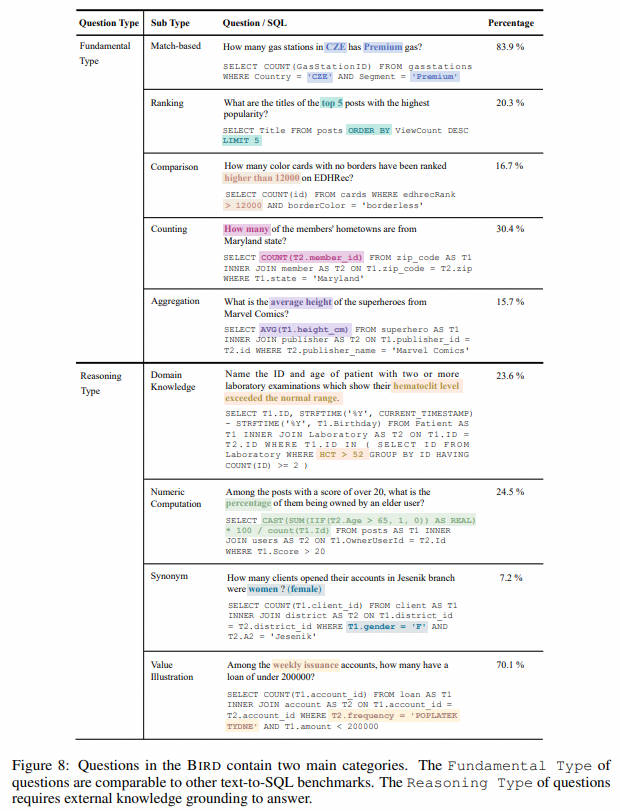
BIRD
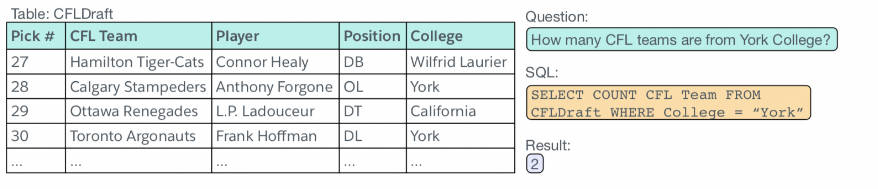
案例:
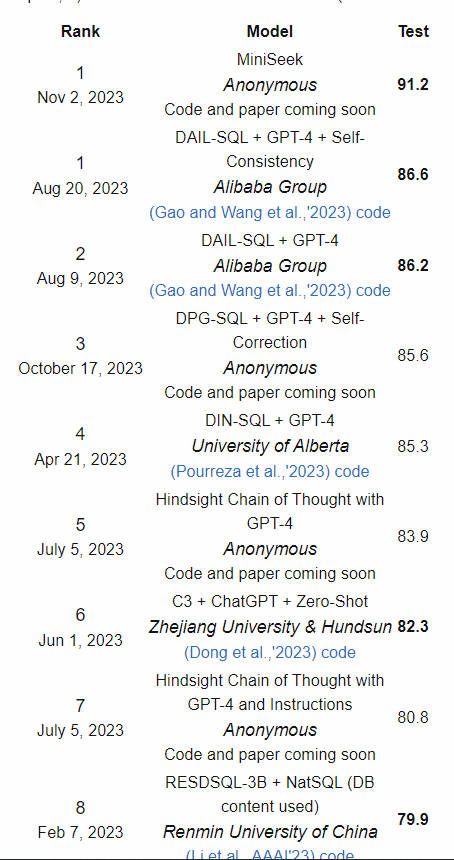
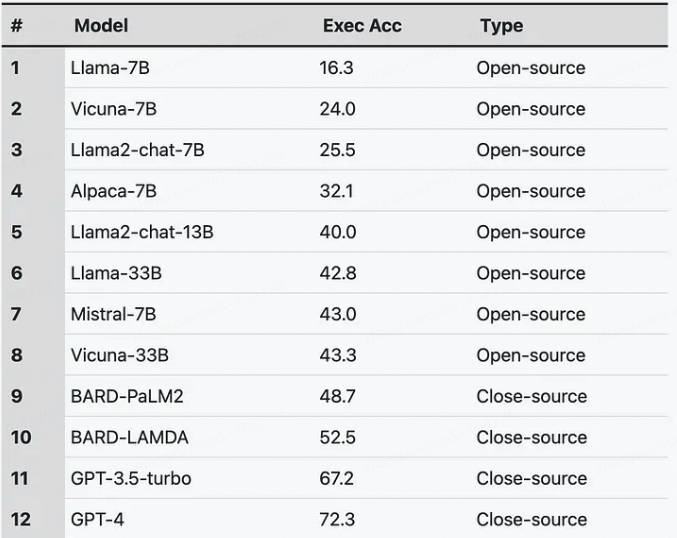
LLM排名:
3.大模型在NL2SQL上对比
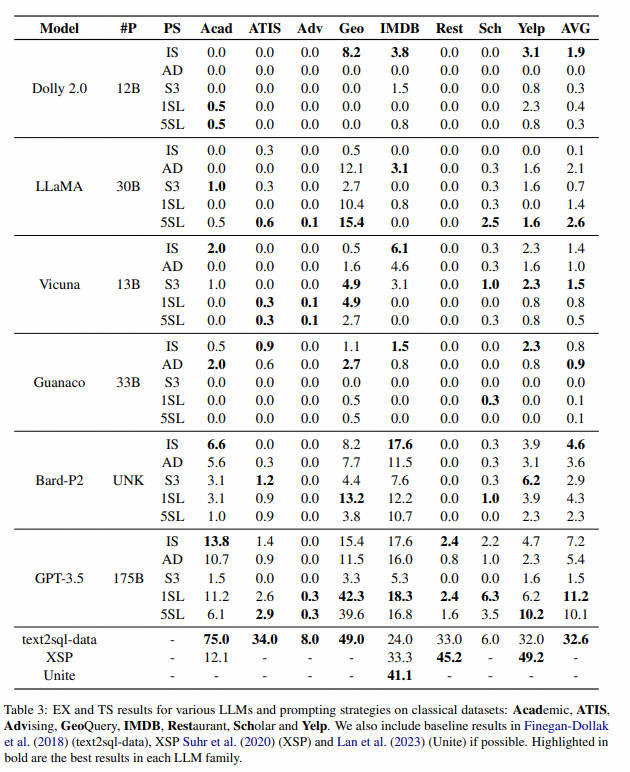
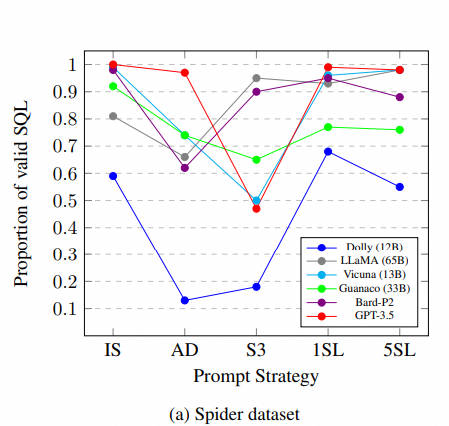
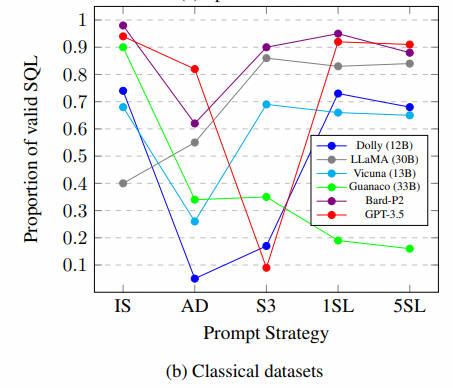
基于论文:Battle of the Large Language Models: Dolly vs LLaMA vs Vicuna vs Guanaco vs Bard vs ChatGPT - A Text-to-SQL Parsing Comparison (2023.10)效果进行对比
本文对六种语言模型进行了综合评估:Dolly、LLaMA、Vicuna、Guanaco、Bard 和 ChatGPT,利用五种不同的提示计谋,直接比力它们在九个基准数据集上的性能。
我们的紧张发现是: