2023下半年到2024第一季度,AI视频生成范畴出现了显着的发作趋势。在Open AI的Sora之前,Runway ML的Gen-2、谷歌的Lumiere、Stable Video Diffusion等技术或产品连续登场,一起为Sora的横空出世铺平了道路。
对Open AI来说,通过人工智能理解和模仿运动中的物理天下,可以帮助人类解决必要现实天下交互的各种使命或题目,这也是Open AI练习Sora这类T2V(Text to Video,文生视频)模子的目的。国内网络上流传有Sora用于影视或者数字孪生等种种设计目的推测,但相对于让AI理解真实的物理天下来说,影视和数字孪生的目的都显得太渺小。
Open AI团队发现,在大规模练习下,Sora展示出了一系列引人注目的涌现能力。这让 Sora 有能力在一定程度上模仿真实天下中的人、动物和环境。比方画家可以在画布上留下新的笔触,并随着时间的推移而连续,符合真实天下的物理规律。
Sora在真实天下物理状态模仿方面具备以下特点: 简单影响行为模仿:Sora能够模仿一些简单的与天下互动的行为,如画家在画布上留下笔触,或者人物在吃食品时留下痕迹。这些行为不是预设的规则,而是模子通过学习大量数据后自然涌现的能力。 动态相机运动:Sora能够生成包含动态相机运动的视频,这意味着视频中的人物和场景元素能够在三维空间中保持连贯的运动。比方,当相机移动或旋转时,视频中的物领会相应地改变位置,就像在现实天下中一样。
1.4 Sora原理
以Encoder为例的Transformer生成示例(泉源:Towards Data Science)
Transformer在数学上类似大矩阵的计算,通过计算差别语义之间的关联度(概率)来生成具有最高概率的语义反馈。传统的RNN、LSTM或者GRU主要是进行模式识别,而Transformer不仅仅是一个矩阵计算,毕竟上还承载着语义关联的紧张功能。
Transformer中的核心组件是多头自注意机制模块。Transformer将输入的编码表现视为一组键值对(K,V),两者的维度都等于输入序列长度。
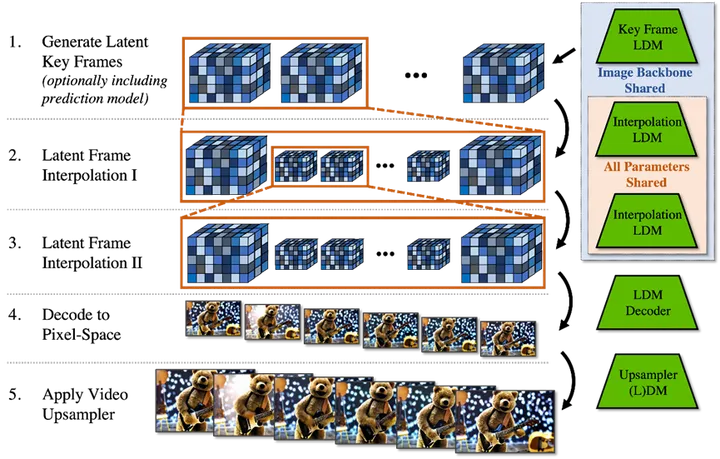
Sora通过联合扩散Transformer模子和视频压缩网络的工作原理,实现了高效的视频生成能力。Sora还设计了相应的解码器来处置惩罚生成的低维潜空间数据,增强视频帧的渲染结果,确保了模子的实用性和机动性。
在练习(Training)过程中,Sora通过视频压缩网络来压缩输入的视频或图片(练习数据),使其成为一个低维的潜空间表征形式,然后将该表征形式传入扩散过程进行练习。对应的表征形式为空间时间图块(Spatial and Temporal Patches)。时间和空间信息被压缩入图块(Patchs),淘汰视频动态内容的数据量(有助于提高模子的练习服从和可扩展性)。Transformer功能被练习为理解时空数据图块,并进行逻辑自洽的推演,生成对应于视频的低维潜空间数据。
Sora 本身是一种扩散模子与Transformer模子的合体,其本质是根据输入,通过Transformer生成潜空间表征序列,再通过扩散模子对表征序列进行解释,逐渐消除噪声生成逻辑自洽的图像序列的过程。
Sora 的关键在于能一次生成整个较长的视频(60秒),而且保持视频中的主体和逻辑的一致性,确保主体暂时脱离视野时也保持不变。
2.1 传统文生图技术的回首
为了更好的了解Sora中的技术,我们首先回首下文生图的一些传统技术。视频本质上就是图像的序列。
在文生图范畴,比力成熟的模子模式包括生成对抗网络( GAN )和扩散模子( Diffusion Models ),本次OpenAI 推出的 Sora 则是一种扩散模子的变种。相较于 GAN,扩散模子的生成多样性和练习稳定性都要更好很多。
Sora 之中有几个紧张的安全步调,包括对抗性测试、检测分类器。
Sora团队与红队成员(错误信息、仇恨内容和私见等范畴的专家)合作,并以对抗性方式测试Sora模子。
Sora前后端还包括检测误导性内容的检测分类器。前端的文天职类检测器将检查并拒绝违反利用许可的输入提示,比方要求仇恨图像、名人肖像或他人 IP 的文本输入提示。Sora后端的图像分类检测器,会检查生成的每个视频帧,以帮助在显示之前符正当律法规和OpenAI的规则。