vivo 互联网服务器团队 - Ma Jian一、概述
实现类1
实现类2

jdk.spi.DataBaseSPI
JdkSpiTest#main()
ServiceLoader部分源码
一个Java接口,等同于服务提供接口,需用@SPI注解修饰。② 扩展
扩展点的实现类。③ 扩展类加载器:ExtensionLoader
类似于Java SPI的ServiceLoader,主要用来加载并实例化扩展类。一个扩展点对应一个扩展加载器。④ Dubbo扩展文件加载路径
Dubbo框架支持从以下三个路径来加载扩展类:⑤ 扩展配置文件
Dubbo框架针对三个不同路径下的扩展配置文件对应三个策略类:
- META-INF/dubbo/internal
- META-INF/dubbo
- META-INF/services
三个路径下的扩展配置文件并没有特殊之处,一般情况下:
- DubboInternalLoadingStrategy
- DubboLoadingStrategy
- ServicesLoadingStrategy
- META-INF/dubbo对开发者开放
- META-INF/dubbo/internal 用来加载Dubbo内部的扩展点
- META-INF/services 兼容Java SPI
和Java SPI不同,Dubbo的扩展配置文件中扩展类都有一个名称,便于在应用中引用它们。如:Dubbo SPI扩展配置文件
扩展点
扩展类1
扩展类2

dubbo.spi.DataBaseSPI
DubboSpiTest#main()
ExtensionLoader#getExtensionLoader()
再看下new ExtensionLoader(type)源码
- 判断当前type类型是否为接口类型。
- 当前扩展点是否使用了@SPI注解修饰。
- EXTENSION_LOADERS为ConcurrentMap类型的内存缓存,内存中存在该类型的扩展加载器则直接使用,不存在就new一个并放入内存缓存中。
ExtensionLoader#ExtensionLoader()
ExtensionLoader#getExtension()
ExtensionLoader#createExtension()
ExtensionLoader#getExtensionClasses()
ExtensionLoader#loadExtensionClasses()
MysqlDataBaseHandler
OracleDataBaseHandler
spring.handlers
SpringSpiTest#main()
DefaultNamespaceHandlerResolver#resolve()
DefaultNamespaceHandlerResolver#getHandlerMappings()
BeanDefinitionParserDelegate#parseCustomElement()

DefaultBeanDefinitionDocumentReader#parseBeanDefinitions()
接口
MysqlDataBaseImpl
MysqlDataBaseImpl
spring.factories
SpringSpiTest#main()
SpringFactoriesLoader#loadFactories()
SpringFactoriesLoader#loadFactoryNames()
SpringFactoriesLoader#instantiateFactory()
SpringApplication#getSpringFactoriesInstance()
首先,spring.factories的实现类似Java SPI,在加载到服务提供接口的实现类后需要循环遍历才能访问,不是很方便。五、应用实践
其次,Spring在5.0.x版本以前SpringFactoriesLoader类定义为抽象类,但在5.1.0版本之后Sping官方将SpringFactoriesLoader改为final类,类型变化对前后版本的兼容不友好。
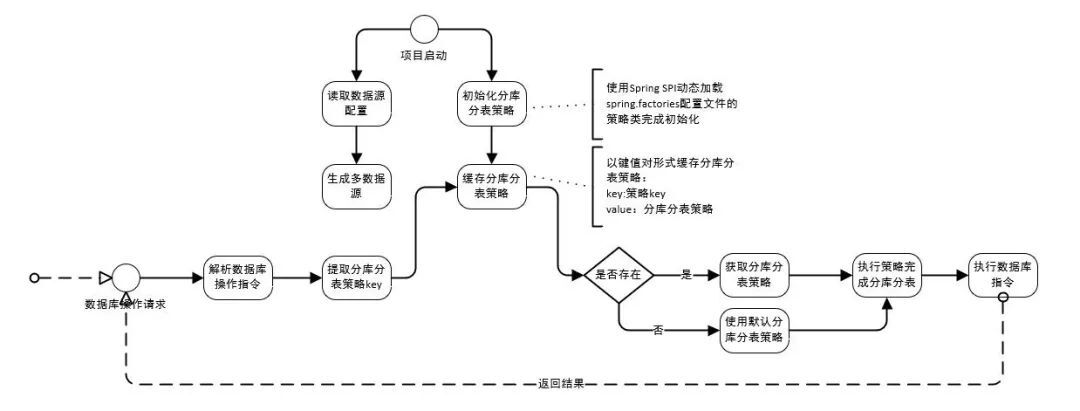
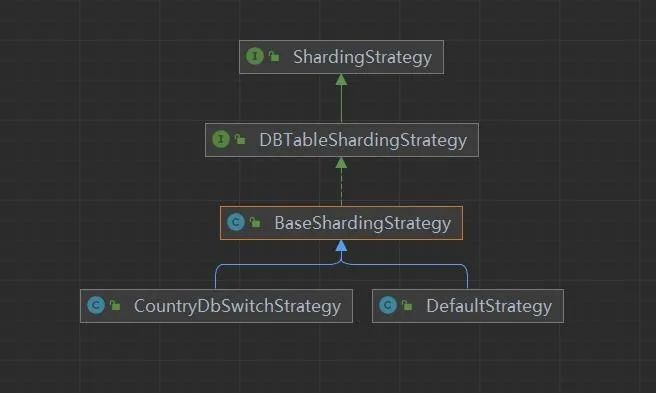
通过上述的流程图可以看到,分库分表SDK通过spring.factories支持动态加载分库分表策略以兼容不同项目的不同使用场景。
- 上述流程图中项目启动过程中生成数据源和分库分表策略的初始化,策略初始化完成后缓存到内存中。
- 发起数据库操作指令时,解析是否需要分库分表(流程中只给出了需要分库分表的流程),需要则通过提取到的策略key获取对应的分库分表策略并进行分库分表,完成数据库操作。
| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |