利用命令 hdfs oiv
cd /opt/hadoop-2.6.0-cdh5.14.0/hadoopDatas/namenodeDatas/current
hdfs oiv -i fsimage_0000000000000000112 -p XML -o hello.xml
4、edits 当中的文件信息查看
查看命令 hdfs oev
cd /opt/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/edits
hdfs oev -i edits_0000000000000000112-0000000000000000113 -o myedit.xml -p XML
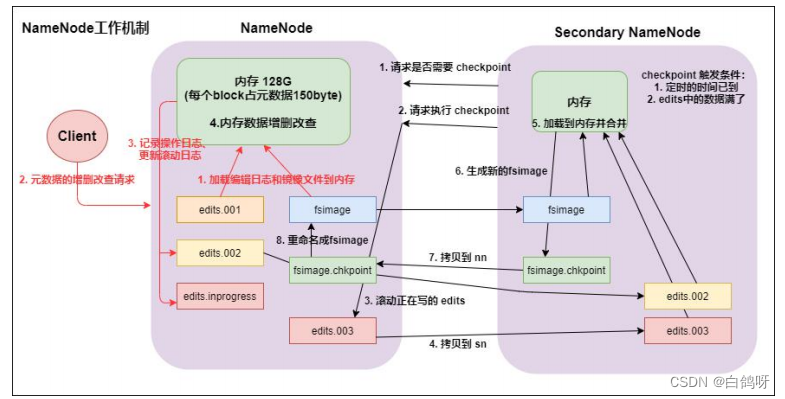
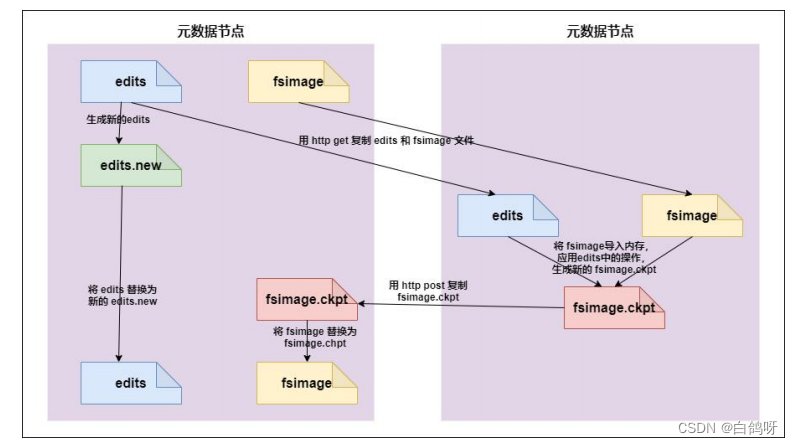
5、secondarynameNode 如何辅助管理 FSImage 与 Edits 文件
进入到以下路径 : 此基础路径为 上述配置中 value 的路径
cd /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/datanodeDatas/current/BP-5574
66926-192.168.52.100-1549868683602/current/finalized/subdir0/subdir3



 PWDnode04 解压安装包
PWDnode04 解压安装包