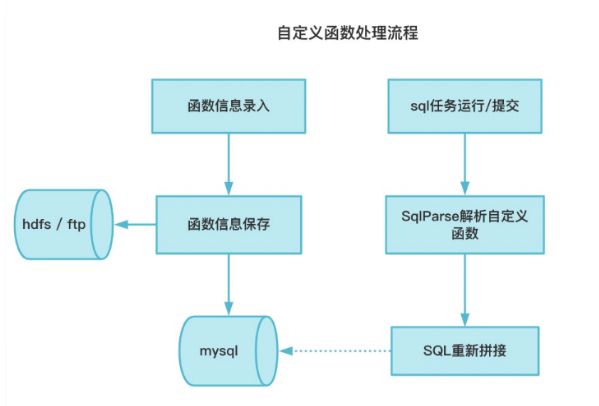
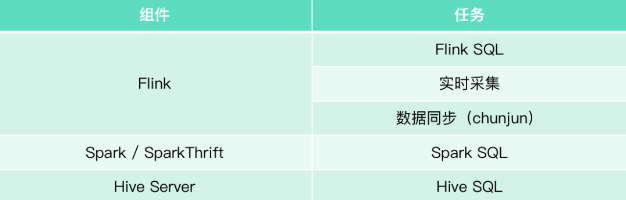
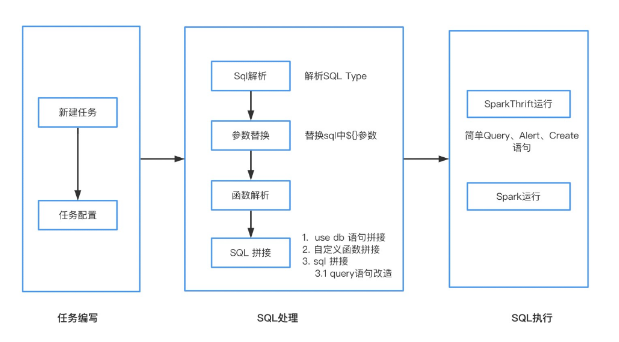
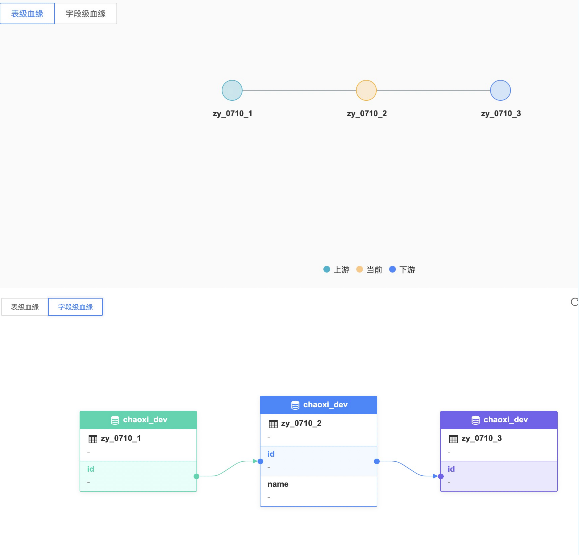
通过SQL解析可以得到表和表之间的关系,以及不同表中字段之间的血源关系。
● 实现工具:calcite
● 可操作任务:SparkSql、HiveSql、数据同步(ChunJun)
用sql举例:
create table zy_0710_1 (id int, name string);
create table zy_0710_2 as select id , name from zy_0710_1;
create table zy_0710_3 as select id , name from zy_0710_2;
四、Taier1.2尝鲜