ToB企服应用市场:ToB评测及商务社交产业平台
标题:
体系架构计划师【第19章】: 大数据架构计划理论与实践 (核心总结)
[打印本页]
作者:
曹旭辉
时间:
2024-6-19 22:07
标题:
体系架构计划师【第19章】: 大数据架构计划理论与实践 (核心总结)
19.1 传统数据处理体系存在的问题
1.传统数据库的数据过载问题
传统应用的数据体系架构计划时,应用直接访问数据库体系。当用户访问量增长时,数据库无法支持日益增长的用户哀求的负载,从而导致数据库服务器无法及时相应用户哀求,出现超时的错误。关于这个问题的常用解决方法如下:
(1)增长异步处理队列,通过工作处理层批量处理异步处理队列中的数据修改哀求。
(2)创建数据库程度分区,通常创建 Key 分区,以主键/唯一键 Hash 值作为 Key。
(3)创建数据库分片或重新分片,通常专门编写脚本来自动完成,且要举行充实测试。
(4)引入读写分离技术,主数据库处理写哀求,通过复制机制分发至从数据库。
(5)引入分库分表技术,按照业务上下文边界拆分数据构造布局,拆分单数据库压力。
2.大数据的特点
大数据具有体量大、时效性强的特点,并非构造单调,而是范例多样; 处理大数据时,传统数据处理体系因数据过载,泉源复杂,范例多样等诸多缘故原由性能低下,必要接纳以新式计算架构和智能算法为代表的新技术;大数据的应用重在发掘数据间的相关性,而非传统逻辑上的因果关系; 因 此,大数据的目的和代价就在于 发现新的知识,洞悉并举行科学决策。当代大数据处理技术,主要分为以下几种:
(1)基于分布式文件体系 Hadoop。
(2)使用 Map/Reduce 或 Spark 数据处理技术。
(3)使用 Kafka 数据传输消息队列及 Avro 二进制格式。
3.大数据利用过程
大数据的利用过程分为: 收罗、洗濯、统计和发掘 4 个过程。
19.2 大数据处理体系架构分析
19.2.1 大数据处理体系面对挑战
大数据处理体系面对的挑战主要有:
1)怎样利用信息技术等手段处理非布局化和半布局化数据。
2)怎样探索大数据复杂性、不确定性特性形貌的刻画方法及大数据的体系建模。
3)数据异构性与决策异构性的关系对大数据知识发现与管理决策的影响。
19.2.2 大数据处理体系架构特性
大数据处理体系应具有的属性和特性包括: 鲁棒性和容错性、低延迟、横向扩展(通过加强呆板性能扩展)、通用、可扩展、即席查询(用户按照本身的要求举行查询)、最少维护和可调试。
1.鲁棒性和容错性 (Robust and Fault-tolerant):对于大规模的分布式体系来说,人和呆板的错误每天都可能会 发生,怎样应对人和呆板的错误,让体系能够从错误中快速恢复尤其重要。
2.低延迟读取和更新能力 (Low Latency Reads and Updates):很多应用程序要求数据体系拥有几毫秒到几百毫秒的低延迟读取和更新能力。有的应用程序允许几个小时的延迟更新,但是只要有低延迟读取与更新的需求,体系就应该在包管鲁棒性 的前提下实现。
3.横向扩容 (Scalable):当数据量/负载增大时,可扩展性的体系通过增长更多的呆板资源来维持性能。也就是常说的体系必要线性可扩展,通常接纳scaleout(通过增长呆板的个数)而不是scaleup(通过增 强呆板的性能)。
4.通用性 (General) 体系必要支持绝大多数应用程序,包括金融范畴、社交网络、电子商务数据分析等。
5.延展性 (Extensible) 在新的功能需求出现时,体系必要能够将新功能添加到体系中。同时,体系的大规模迁移能力是计划者必要考虑的因素之一,这也是可延展性的表现。
6.即席查询能力 (Allows Ad Hoc Queries) 用户在使用体系时,应当可以按照本身的要求举行即席查询 (Ad Hoc)。 这使用户可以通过体系多样化数据处理,产生更高的应用代价。
7.最少维护能力 (Minimal Maintenance) 体系必要在大多数时间下保持安稳运行。使用机制简单的组件和算法让体系底层拥有低复 杂度,是减少体系维护次数的重要途径。 Marz认为大数据体系计划不能再基于传统架构的增量 更新计划,要通过减少复杂性以减少发生错误的几率、制止繁重操作。
8.可调试性 (Debuggable)体系在运行中产生的每一个值,必要有可用途径举行追踪,并且要能够明确这些值是怎样 产生的。
19.3 Lambda架构
19.3.1 Lambda架构对大数据处理体系的理解
Lambda 架构是 一种用于同时处理离线和及时数据的、可容错的、可扩展的分布式体系,它 具备强鲁棒性,提供低延迟和持续更新。
19.3.2 Lambda架构应用场景
1.呆板学习中的Lambda架构
呆板学习可以受益于由 Lambda架构构 建的数据体系、所处理的各类数据。据此,呆板学习算法可以提出各种问题,并逐渐对输入到 体系中的数据举行模式识别。
2.物联网的 Lambda架构
如果说呆板学习利用的是 Lambda 架构的输出,那么物联网则更多地作为数据体系的输入。
3.流处理和Lambda架构挑战
在实际应用中,由于及时处理流以毫秒为单元,持续产生用于更新视图的数据流,是一个 非常复杂的过程。因此,将基于文档的数据库、索引以及查询体系共同在一起使用,是一种比较好的选择。
19.3.3 Lambda架构介绍
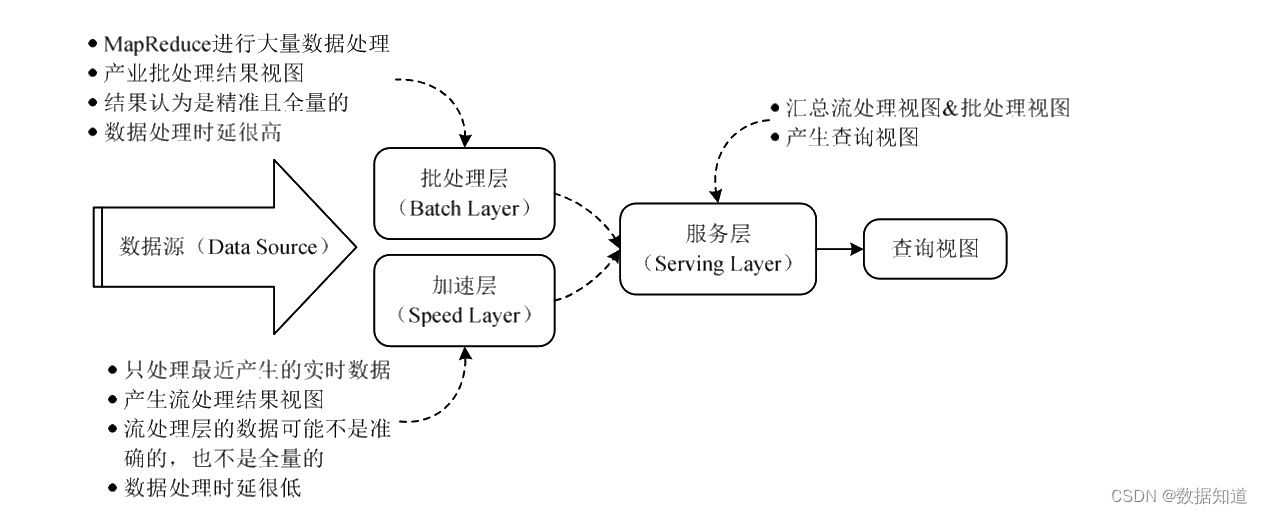
Lambda 架构如图:
Lambda 架构分为以下 3 层:
(1)批处理层。该层核心功能是 存储主数据集,主数据集数据具有 原始、不可变、真实 的特性。批处理层周期性地将增量数据转储至主数据集,并在主数据集上执行批处理,天生批视图。架构实现方面可以使用 Hadoop HDFS 或 HBase 存储主数据集,再利用 Spark 或 MapReduce 执行周期批处理,之后使用 MapReduce 创建批视图。
(2)加快层。该层的核心功能是 处理增量及时数据,天生及时视图,快速执行即席查询。架构实现方面可以使用 Hadoop HDFS 或 HBase 存储及时数据,利用 Spark 或 Storm 实现及时数据处理和及时视图。
(3)服务层。该层的核心功能是 相应用户哀求,归并批视图和及时视图中的结果数据集得到终极数据集。具体来说就是接收用户哀求,通过索引加快访问批视图,直接访问及时视图,然后归并两个视图的结果数据集天生终极数据集,相应用户哀求。架构实现方面可以使用 HBase 或 Cassandra 作为服务层,通过 Hive 创建可查询的视图。
19.3.4 Lambda架构的实现
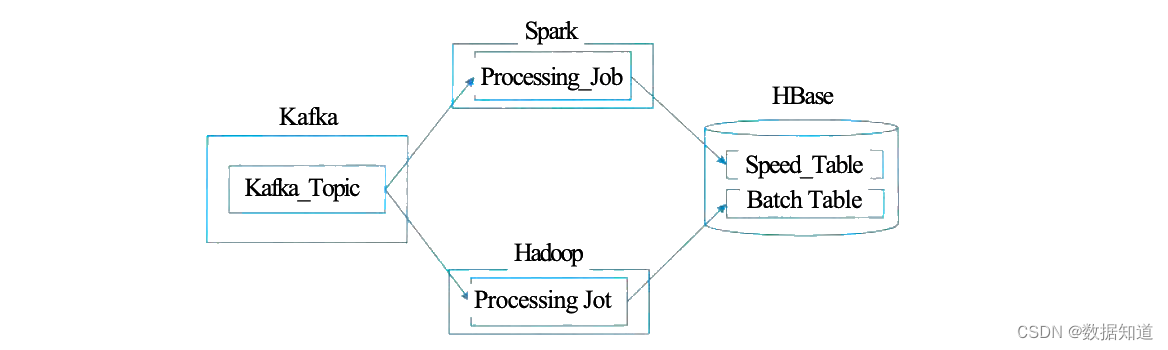
如图,在这种Lambda架构实现中,Hadoop(HDFS) 用于存储主数据集,Spark(或 Storm) 可构成速率层 (Speed Layer),HBase (或Cassandra) 作为服务层,由Hive创建可查询的视图。
Hadoop是被计划成得当运行在通用硬件上的分布式文件体系 (Distributed File System)。
Apache Spark是专为大规模数据处理而计划的快速通用的计算引擎。
HBase-Hadoop Database, 是一个高可靠性、高性能、面向列、可伸缩的分布式存储体系,利用HBase技术可在廉价 PCServer上搭建起大规模布局化存储集群。
19.3.5 Lambda架构优缺点
Lambda 架构的优点: 容错性好,查询灵活度高,弹性伸缩,易于扩展。
Lambda 架构的缺点: 编码量大,持续处理本钱高,重新摆设和迁移本钱高。
19.3.6 Lambda与其他架构模式对比
Lambda架构的诞生离不开很多现有计划头脑和架构的铺垫,如变乱溯源 (Event Sourcing) 架构和下令查询职责分离 (Command Query Responsibility Segregation,CQRS) 架构, Lambda架构的计划头脑和这两者有一定程度的相似。
1.变乱溯源(Event Sourcing)本质上是一种数据长期化的方式,其由三个核心观点构成:
(1)整个体系以变乱为驱动,所有业务都由变乱驱动来完成。
(2)变乱是核心,体系的数据以变乱为基础,变乱要保存在某种存储上。
(3)业务数据只是一些由变乱产生的视图,不一定要保存到数据库中。
Lambda架构中数据集的存储使用的概念与变乱溯源中的头脑完全一致,二者都是在使用统一的数据模型对数据处理变乱本身举行定义。
2.CQRS架构分离了对于数据举行的读操作(查询)和写(修改)操作。其将能够改变数据模型状态的下令和对于模型状态的查询操作实现了分离。这是范畴驱动计划 (Domain-Driven Design,DDD) 的一个架构模式,主要用来解决 数据库报表的输出处理方式。Lambda 架构中,数据的修改通过批处理和流处理实现,通过写操作将数据转换成查询时所对应的View。
19.4 Kappa架构
19.4.1 Kappa架构下对大数据处理体系的理解
为了计划出能满足前述的大数据关键特性的体系,我们必要对数据体系有本质性的理解。 我们可将数据体系简单理解为: 数据体系=数据+查询 进而从 数据和查询 两方面来认识大数据体系的本质。
1.数据的特性
数据是一个不可分割的单元,数据有两个关键的性子: When和 What。
(1)When。When是指数据是与时间相关的,数据一定是在某个时间点产生的。
(2)What。What 是指数据的本身。由于数据跟某个时间点相关,所以数据的本身是不可变的 (Immutable), 过往的数据已经成为究竟 (Fact), 你不可能回到过去的某个时间点去改变数据究竟。
2.数据的存储
Lamba架构中对数据的存储接纳的方式是: 数据不可变, 存储所有数据。
19.4.2 Kappa架构介绍
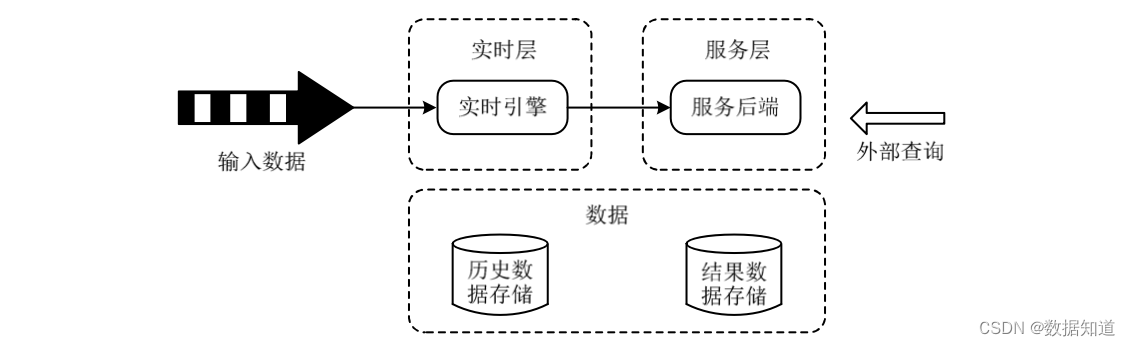
Kappa 架构是在 Lambda 架构的基础上举行了优化,删除了 Batch Layer 的架构,将数据通道以消息队列举行替换。Kappa 架构本质上是 通过改进 Lambda 架构中的加快层,使它既能够举行及时数据处理, 同时也有能力在业务逻辑更新的环境下重新处理以前处理过的历史数据,如图:
Kappa 架构分为如下 2 层:
(1)及时层。该层核心功能是处理输入数据,天生及时视图。具体来说是接纳流式处理引擎 逐条处理输入数据,天生及时视图。架构实现方式是接纳 Apache Kafka 回访数据,然后接纳 Flink 或 Spark Streaming 举行处理。
(2)服务层。该层核心功能是使用及时视图中的结果数据集相应用户哀求。实践中使用数据 湖中的存储作为服务层。
19.4.3 Kappa架构的实现
下面以Apache Kafka为例来讲述整个全新架构的过程:摆设 Apache Kafka, 并设置数据日志的保存期 (Retention Period)。 这里的保存期指的是你希望能够重新处理的历史数据的时间区间。例如:
如果你希望重新处理最多一年的历史数据, 那就可以把Apache Kafka中的保存期设置为365天。
如果你希望能够处理所有的历史数据,那就可以把 Apache Kafka 中的保存期设置为“永世 (Forever)”。
如果我们必要改进现有的逻辑算法,那就表现我们必要对历史数据举行重新处理。
19.4.4 Kappa架构的优缺点
Kappa 架构的优点是 将离线和及时处理代码举行了统一,方便维护。制止了 Lambda架构中与离线数据归并的问题,查询历史数据的时候只必要重放存储的历史数据即可 。
缺点是 消息中间件有性能瓶颈、数据关联时处理开销大、扬弃了离线计算的可靠性。
19.4.5 常见Kappa架构变形
Kappa 架构常见变形是
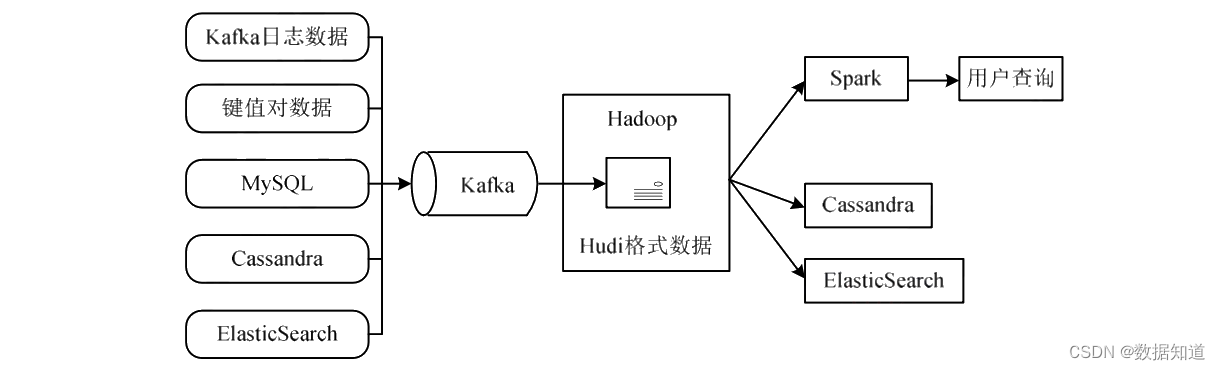
1、Kappa+架构
,如图 :
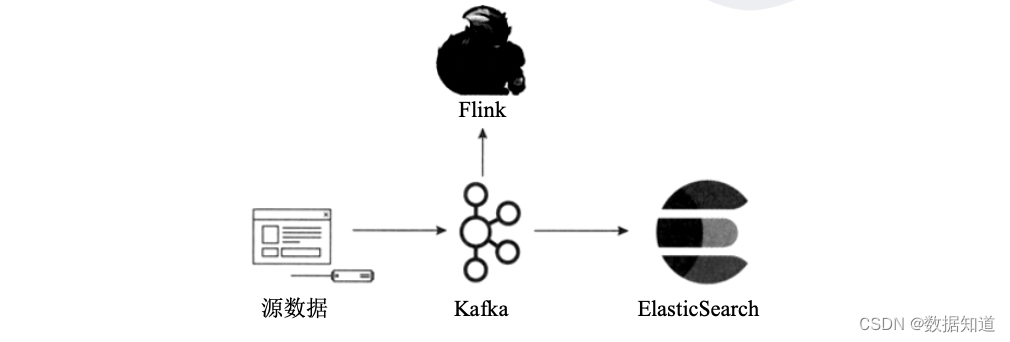
Kappa+是Uber提出流式数据处理架构,它的核心头脑是 让流计算框架直接读HDFS里的数据仓库数据,一并实现及时计算和历史数据backfll计算,不必要为backfll作业恒久保存日志大概把数据拷贝回消息队列。
2、混合分析体系 Kappa 架构
,如图:
在基于使用Kafka +Flink构建Kappa流计算数据架构,针对Kappa架构分析能力不敷的问题,再利用Kafka对接组合 Elastic- Search 及时分析引擎,部门增补其数据分析能力。但是ElasticSearch也只得当对合理数据量级的热点数据举行索引,无法覆盖所有批处理相关的分析需求,这种混合架构某种意义上属于Kappa和Lambda间的折中方案。
19.5 Lambda架构与Kappa架构的对比和计划选择
19.5.1 Lambda架构与Kappa架构的特性对比
Lambda 架构与 Kappa 架构的对比,见表:
对比内容Lambda 架构Kappa 架构复杂度与开发维护本钱维护两套体系(引擎),复杂度高,本钱高维护一套体系(引擎),复杂度低,本钱低计算开销周期性批处理计算,持续及时计算计算开销大须要时举行全量计算,计算开销相对较小及时性满足及时性满足及时性历史数据处理能力批式全量处理,吞吐量大;历史数据处理能力强;批视图与及时视图存在辩说可能流式全量处理,吞吐量相对较低 历史数据处理能力相对较弱 对于两种架构计划的选择可以从以下 4 个方面考虑,见表
19.5.2 Lambda架构与Kappa架构的计划选择
对于两种架构计划的选择可以从以下 4 个方面考虑,见表
计划考虑Lambda 架构Kappa 架构业务需求与技术要求依靠 Hadoop、Spark、Storm 技术依靠 Flink 计算引擎,偏流式计算复杂度及时处理和离线处理结果可能不一致频繁修改算法模型参数开发维护本钱本钱预算充足本钱预算有限历史数据处理能力频繁使用海量历史数据仅使用小规模数据集
19.6 大数据架构计划案例分析
19.6.1 Lambda架构在某网奥运中的大数据应用
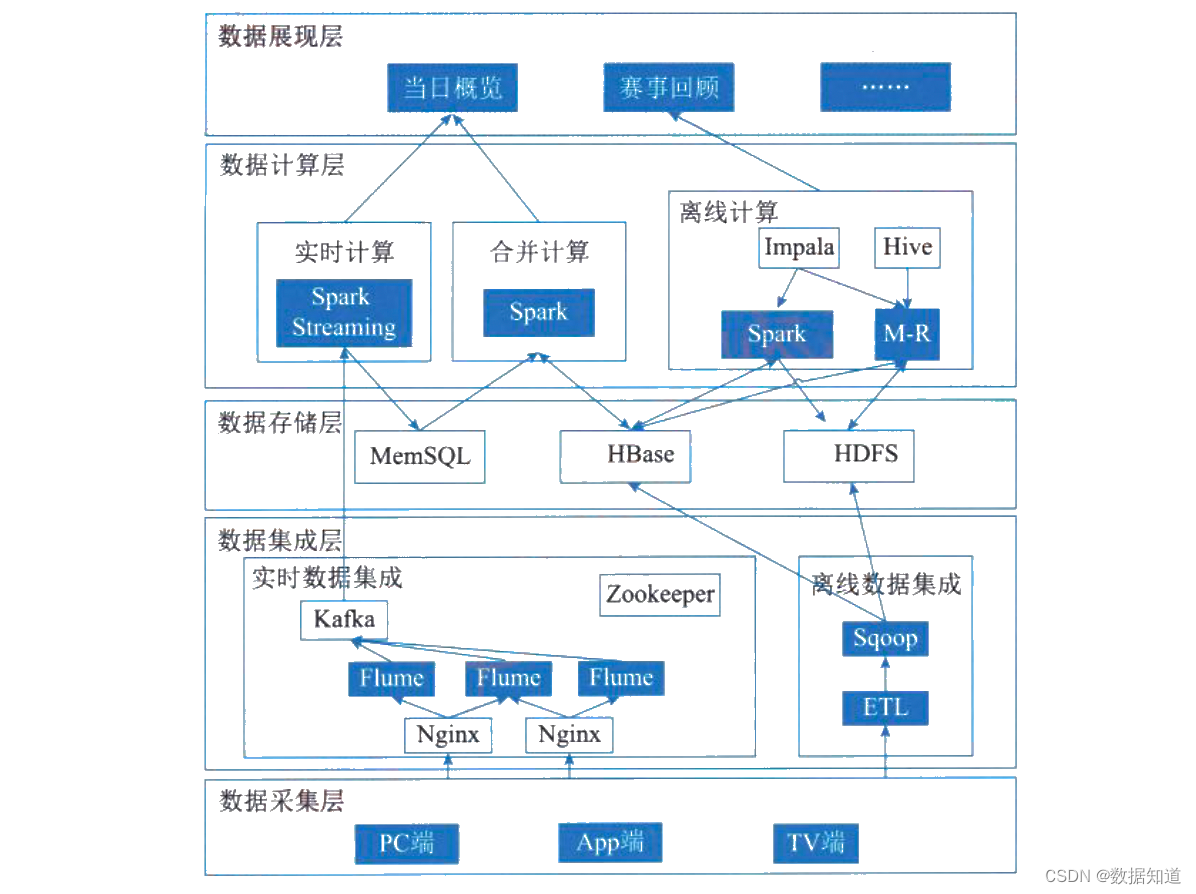
某网接纳以 Lambda 架构搭建的大数据平台处理里约奥运会大规模视频网络观看数据,具体平台架构计划如图 :
对于图中的数据计算层可以分为 离线计算、及时计算、归并计算 3 个部门。
(1)离线计算部门: 用于存储持续增长的批量离线数据,并且会周期性地使用 Spark 和 Map/Reduce 举行批处理,将批处理结果更新到批视图之后使用 Impala 大概 Hive 创建数据仓库, 将结果写入 HDFS 中。
(2)及时计算部门: 接纳 Spark Streaming,只处理及时增量数据,将处理后的结果更新到及时视图。
(3)归并计算部门: 归并批视图和及时视图中的结果,天生终极数据集,将终极数据集写入 HBase 据库中用于相应用户的查询哀求。
19.6.2 Lambda架构在某网广告平台的应用与演进
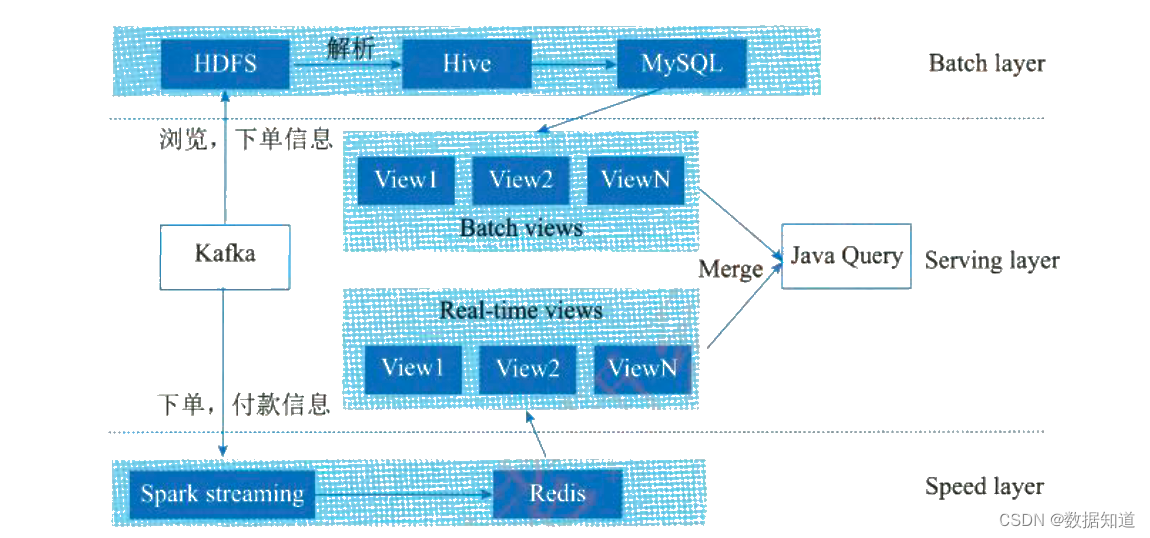
某网基于 Lambda 架构的广告平台,分为 批处理层(Batch Layer)、加快层(Speed Layer)、服 务层(Serving Layer),某网广告平台 Lambda 架构如图:
及时处理过程如下:
(1)批处理层: 每天凌晨将 Kafka 中浏览、下单等消息同步到 HDFS 中,将 HDFS 中数据剖析为 Hive 表,然后使用 HQL 或 Spark SQL 计算分区统计结果 Hive 表,将 Hive 表转储到 MySQL 中作为批视图。
(2)加快层: 使用 Spark Streaming 及时监听 Kafka 下单、付款等消息,计算每个追踪链接维度的及时数据,将及时计算结果存储在 Redis 中作为及时视图。
(3)服务层: 接纳 Java Web 服务,对外提供 HTTP 接口,Java Web 服务读取 MySQL 批视图表和 Redis 及时视图表。
19.6.3 某证券公司大数据体系
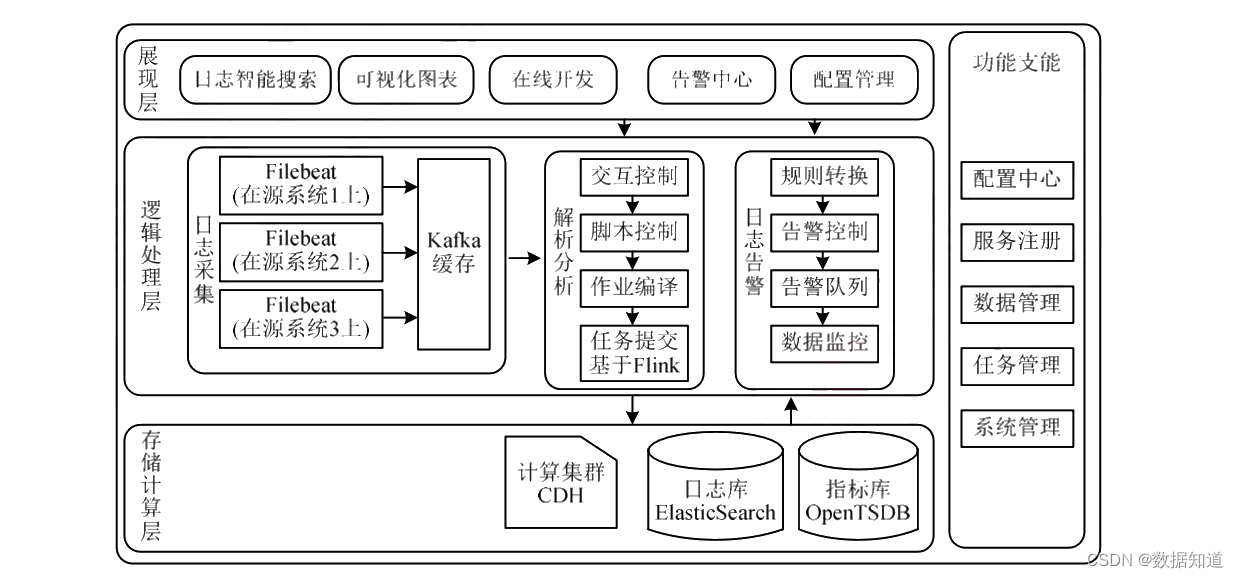
某证券公司智能决策大数据体系是一个基于 Kappa 架构的及时日志分析平台,如图:
具体的及时处理过程如下:
(1)日志收罗: 用统一的数据处理引擎 Filebeat 及时收罗日志并推送给 Kafka 缓存。
(2)日志洗濯剖析: 利用基于大数据计算集群的 Flink 计算框架及时读取 Kafka 消息并举行洗濯,剖析日志文本转换成指标。
(3)日志存储: 日志转储到 ElasticSearch 日志库,指标转储到 OpenTSDB 指标库。
(4)日志监控: 单独设置告警消息队列,保持监控消息时序管理和及时推送。
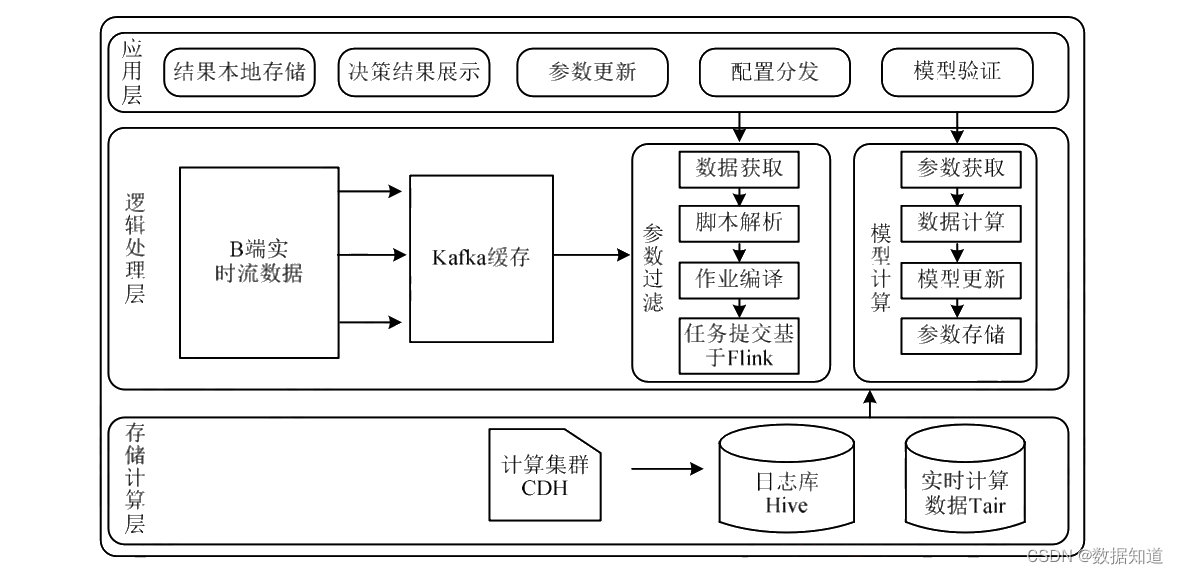
19.6.4 某电商智能决策大数据体系
该智能决策大数据平台基于 Kappa 架构,使用统一的数据处理引擎 Funk 可及时处理流数据,并将其存储到数据仓库工具 Hive 与分布式缓存 Tair 中,以供后续决策服务的使用。如图:
及时处理的过程如下:
(1)数据收罗: B 端及时收罗用户点击、下单、广告曝光、出价等数据然后推送给 Kafka 缓存。
(2)数据洗濯聚合: 由 Flink 及时读取 Kafka 消息,按需过滤参与业务需求的指标,将聚合时间段的数据转换成指标。
(3)数据存储: Flink 将计算结果转储至 Hive 日志库,将模型必要的参数转储至及时计算数据库 Tair 缓存,然后后续决策服务从 Tair 中获取数据举行模型训练。
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/)
Powered by Discuz! X3.4