
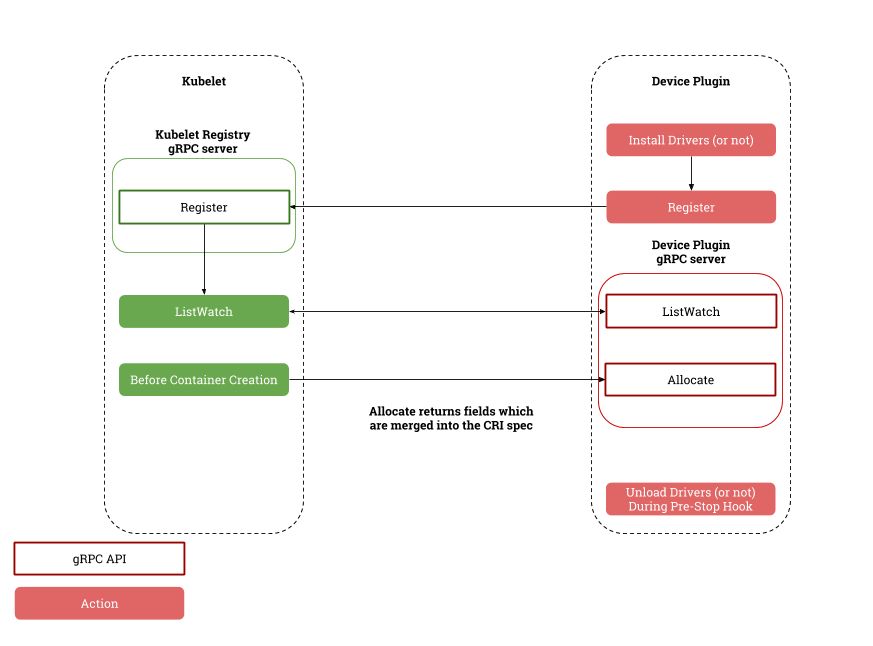
 arallel"selector: # define how the deployment finds the pods it managesmatchLabels: app: binpack-1 template: # define the pods specificationsmetadata: labels: app: binpack-1 spec: containers: - name: binpack-1image: cheyang/gpu-player:v2resources: limits: # GiB aliyun.com/gpu-mem: 3
arallel"selector: # define how the deployment finds the pods it managesmatchLabels: app: binpack-1 template: # define the pods specificationsmetadata: labels: app: binpack-1 spec: containers: - name: binpack-1image: cheyang/gpu-player:v2resources: limits: # GiB aliyun.com/gpu-mem: 3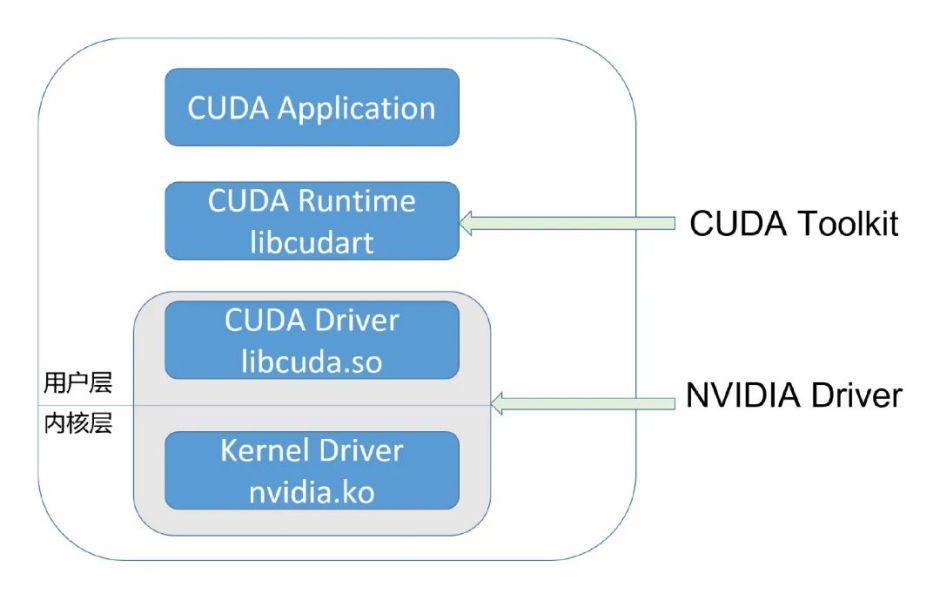
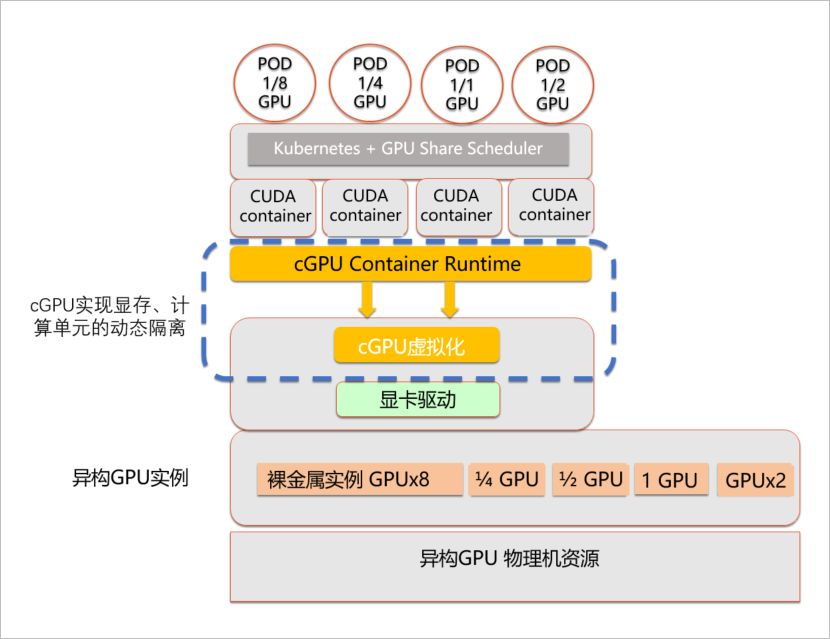
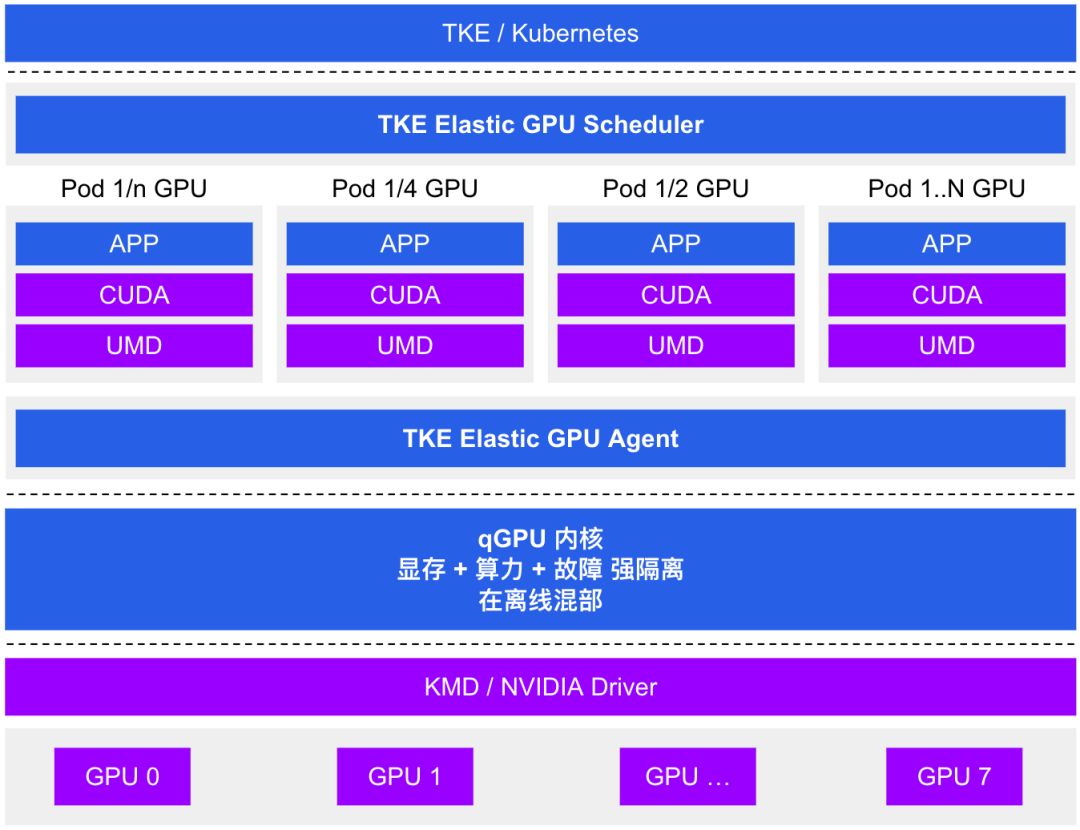
| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |