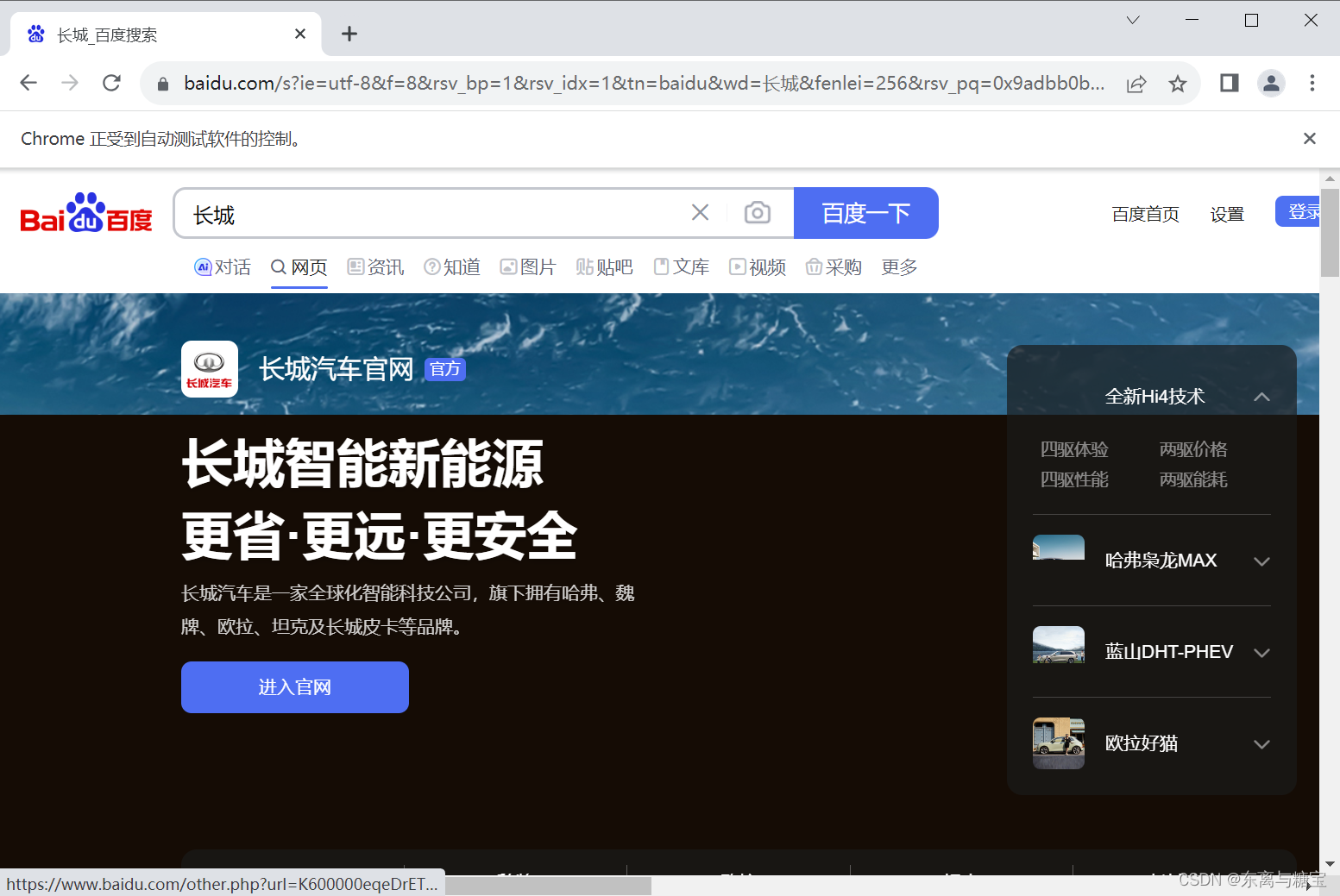
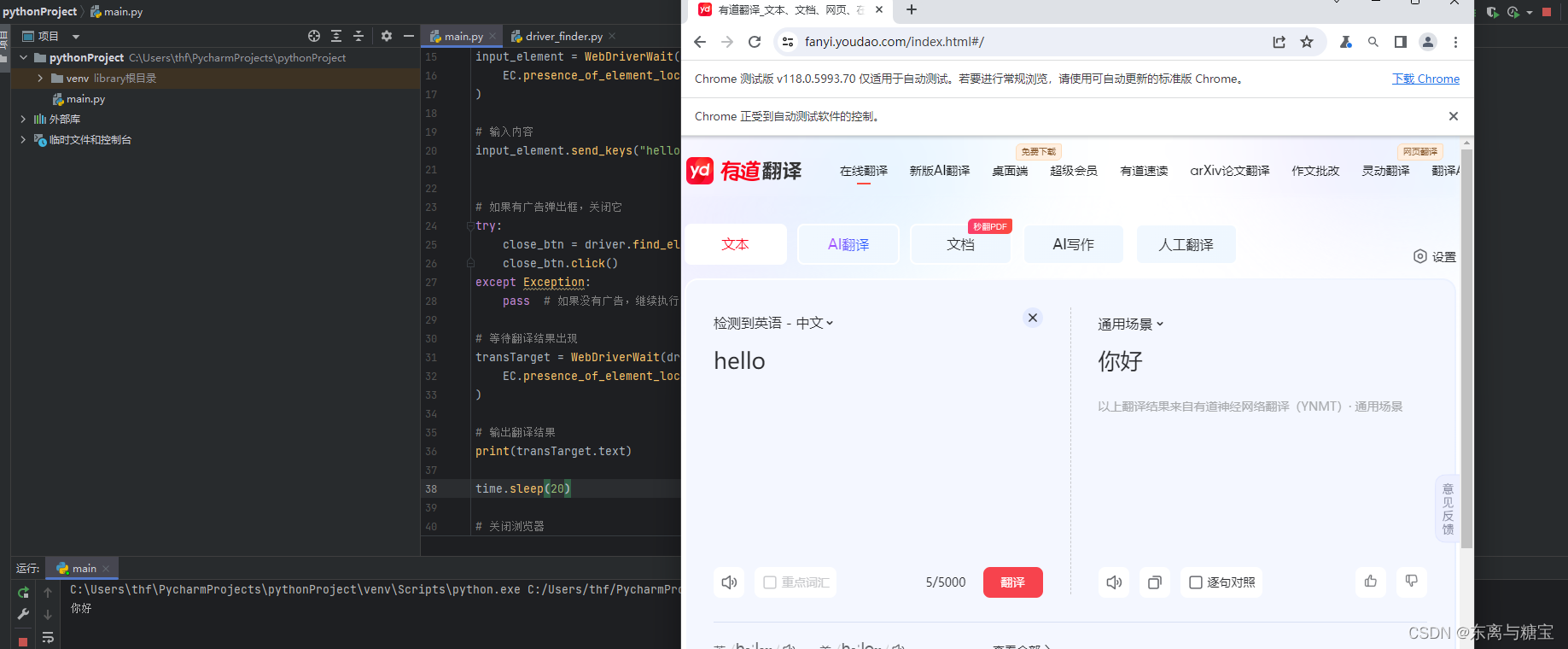
要使用 Selenium 通过元素的 ID 进行定位,你可以使用 By.ID 选择器和 find_element 方法。以下是如何通过元素的ID进行定位的示例:
from selenium import webdriver
# 初始化一个WebDriver实例,这里使用Chrome作为浏览器
driver = webdriver.Chrome()
# 打开指定的页面
url = "https://www.example.com"
driver.get(url)
# 通过元素的ID进行定位并执行操作
element = driver.find_element(By.ID, "element_id")
# 在这里,你可以执行与该元素相关的操作,例如单击、输入文本等
element.click()
# 最后,关闭浏览器窗口
driver.quit()
复制代码
在上述示例中,driver.find_element(By.ID, "element_id") 通过元素的ID属性来定位元素,并将其存储在变量 element 中,然后可以执行与该元素相关的操作。记得将 "element_id" 替换为你要查找的元素的实际 ID。
3. name 定位
# 通过元素的name属性进行定位并执行操作
element = driver.find_element(By.NAME,"element_name")
复制代码
4. class 定位
# 通过元素的CSS类名进行定位并执行操作
element = driver.find_element(By.By.CLASS_NAME, ".element_class")
复制代码
5. tag 定位
每个 tag 往往用来界说一类功能,所以通过 tag 来识别某个元素的成功率很低,每个页面一般都用很多雷同的 tag
# 通过元素的标签名进行定位并执行操作
element = driver.find_element(By.TAG_NAME,"element_tag")
复制代码
element_tag 在示例代码中代表你要查找的元素的 HTML 标签名,例如 < div >, < a >, < p >等。具体来说,如果你要查找一个 < div > 元素,你可以将 element_tag 替换为 "div" ,如果你要查找一个 < a > 元素,你可以将 element_tag 替换为 "a",以此类推
6. xpath 定位
XPath(XML Path Language)是一种用于在 XML 文档中定位元素的语言,也适用于HTML 文档,由于 HTML 是一种基于 XML 的标记语言的变体。XPath 是一种功能强大的元素定位方法,它答应你准确地定位网页上的元素,无论它们在文档中的位置如何。以下是XPath定位的一些示例: 1. 通过元素名称定位:
定位所有的链接元素://a
定位所有的段落元素://p
定位第一个标题元素://h1
2. 通过元素属性定位:
定位具有特定 id 属性的元素:
//*[@id='element_id']
复制代码
定位具有特定 class 属性的元素:
//*[@class='element_class']
复制代码
3. 通过文本内容定位:
定位包含特定文本的元素:
//*[text()='要查找的文本']
复制代码
定位以特定文本开头的元素:
//*[starts-with(text(), '开头文本')]
复制代码
定位包含特定文本的链接:
//a[contains(text(), '链接文本')]
复制代码
4. 通过元素条理结构定位:
定位父元素的子元素:
//div[@id='parent_id']/p(查找 id 属性为 'parent_id' 的 < div > 元素下的所有 < p > 元素)
复制代码
定位祖先元素的子元素:
//div[@class='grandparent_class']//span(查找 class 属性为 'grandparent_class' 的祖先元素下的所有< span >元素)
复制代码
5. 使用逻辑运算符:
定位同时满足多个条件的元素:
//input[@type='text' and @name='username'](查找type属性为 'text' 且 name 属性为 'username' 的输入框)
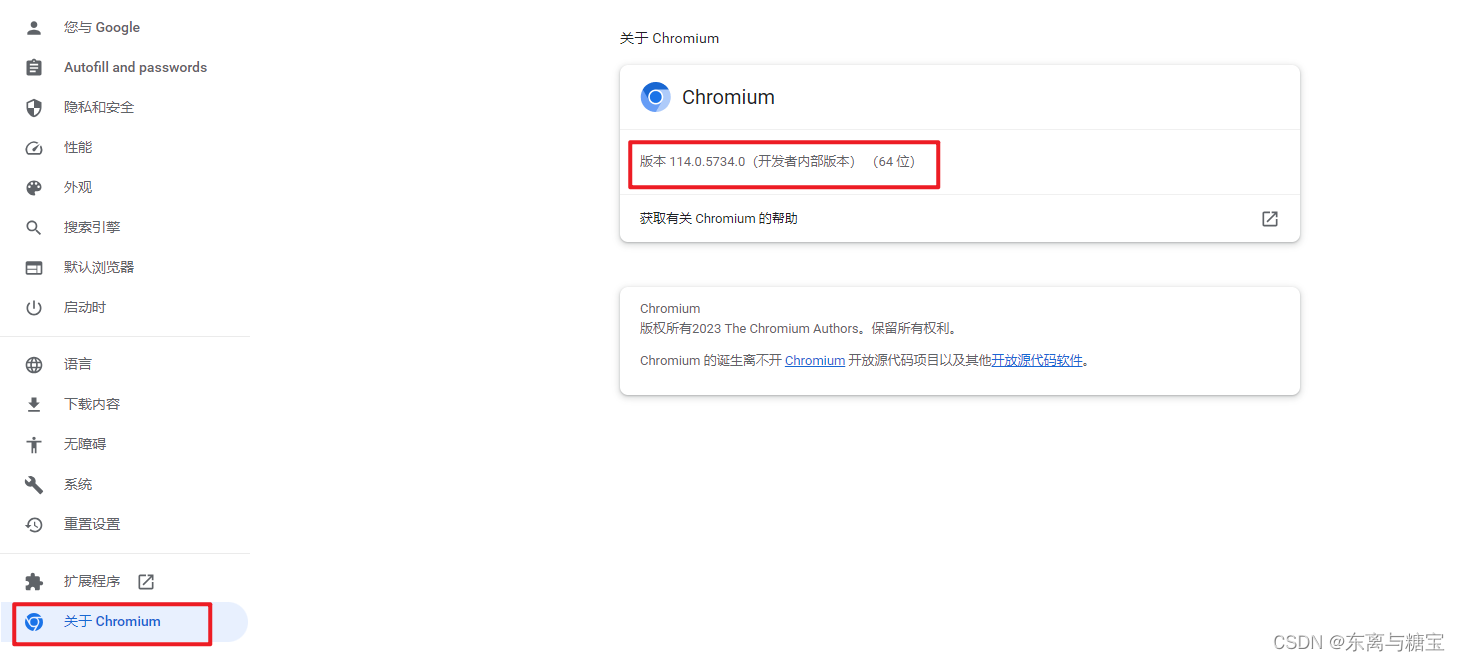



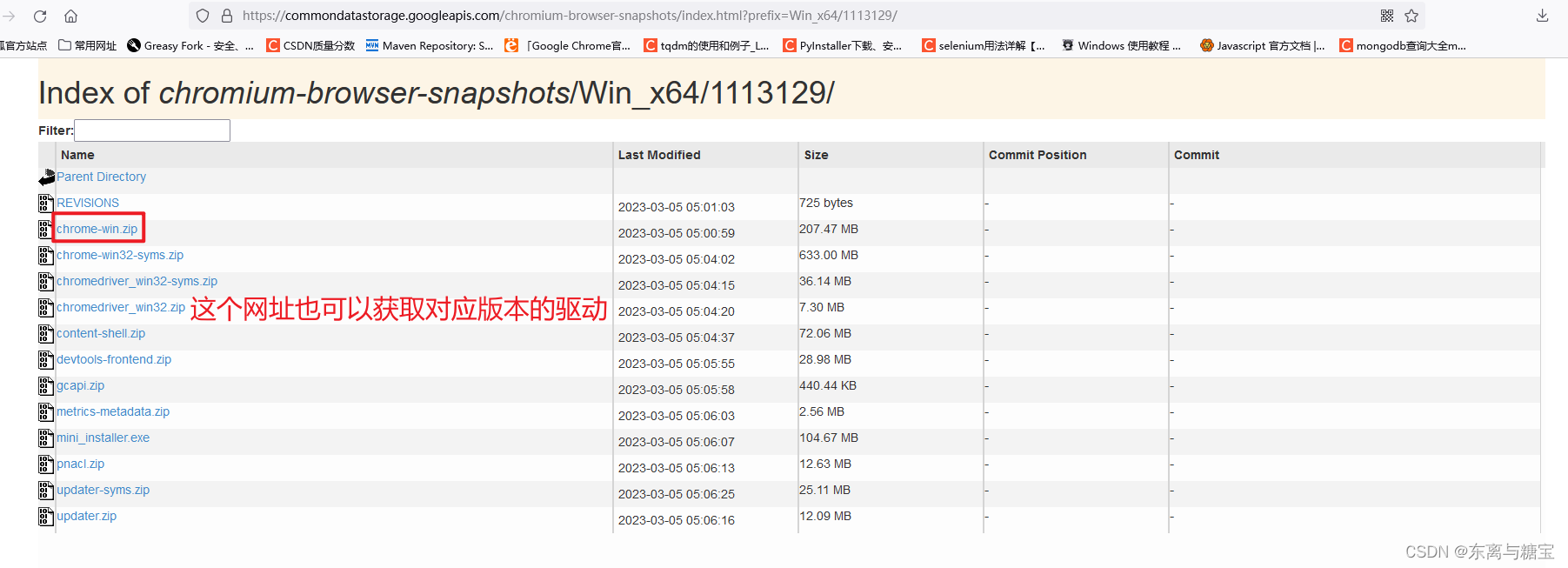
 ath),添加的时间要注意不要把 path 变量给覆盖了,如果覆盖了千万别关机,然后百度。添加成功后使用下面代码进行测试。
ath),添加的时间要注意不要把 path 变量给覆盖了,如果覆盖了千万别关机,然后百度。添加成功后使用下面代码进行测试。