ToB企服应用市场:ToB评测及商务社交产业平台
标题:
spring中,为什么前端明显传了值,后端却接收不到
[打印本页]
作者:
锦通
时间:
2024-6-22 12:51
标题:
spring中,为什么前端明显传了值,后端却接收不到
题目场景
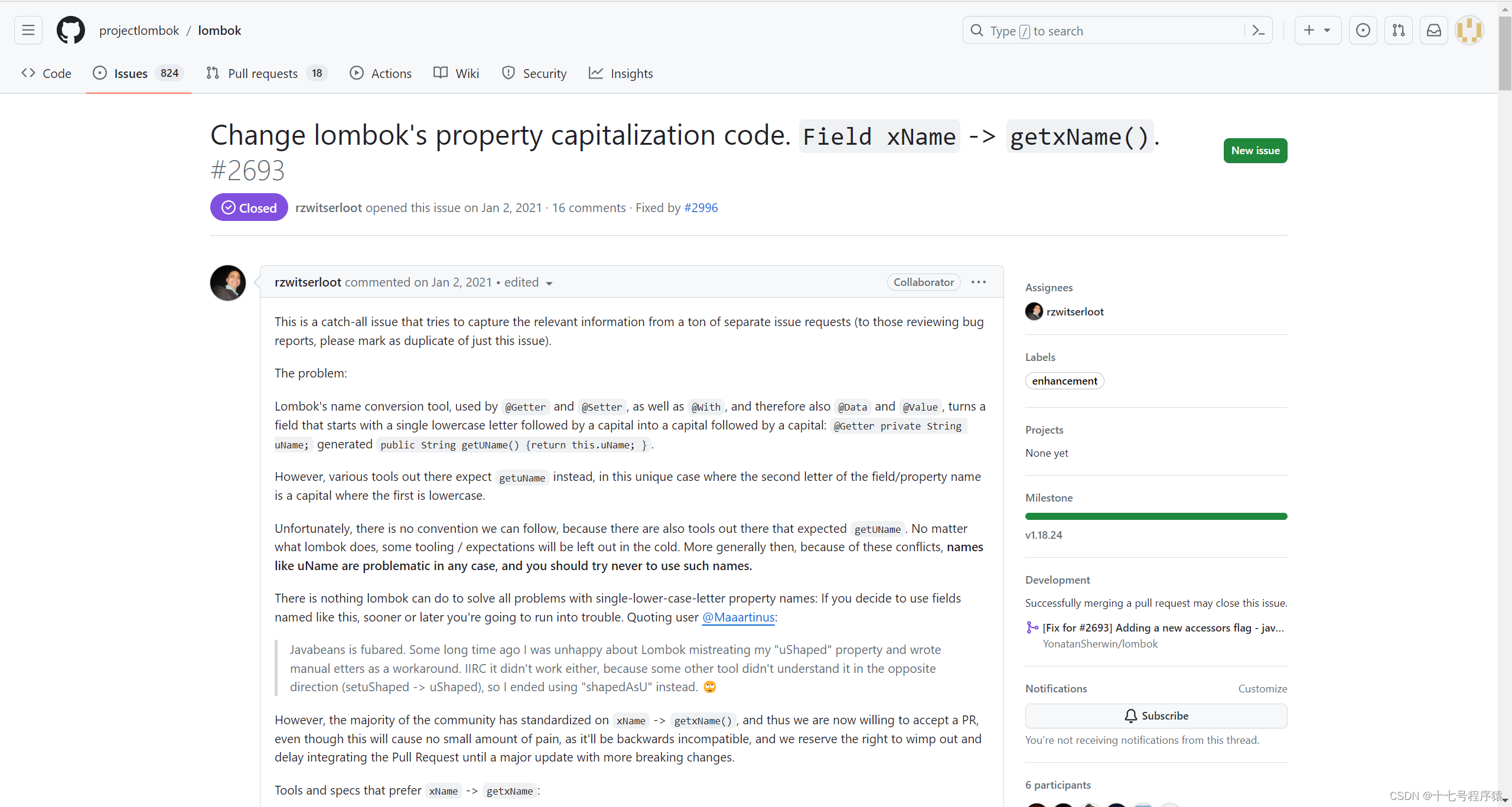
在进行前后端的联调时,偶然候会出现,前端明显传了值,后端接口却接收不到的情况,这种情况常常让人很苦恼,然后就会去仔细对比前后端的参数单词是不是对应上了,也会去检查是不是前端的请求参数格式有题目,又或者是后端接口接收的参数格式有题目,一通检查对比下来,发现都没题目。那毕竟是为什么呢?那就继续往下看吧。
题目重现
控制层代码:
@PostMapping(value = "/test")
public void test(@RequestBody UserVO userVO) {
System.out.println("用户代码:" + userVO.getUCode());
System.out.println("用户名称:" + userVO.getUName());
}
复制代码
参数实体类:UserVO
@Data
public class UserVO {
/**
* 用户代码
*/
private Long uCode;
/**
* 用户名称
*/
private String uName;
}
复制代码
用postman模仿前端调用:
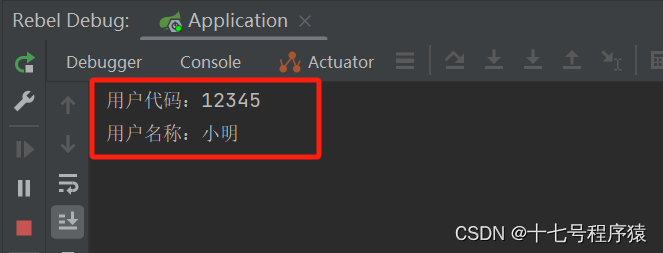
控制台预期打印结果:
用户代码:12345
用户名称:小明
复制代码
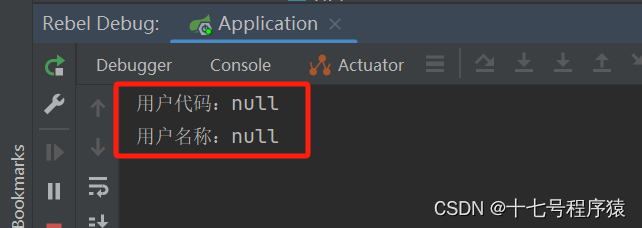
控制台现实打印结果:
解决方式
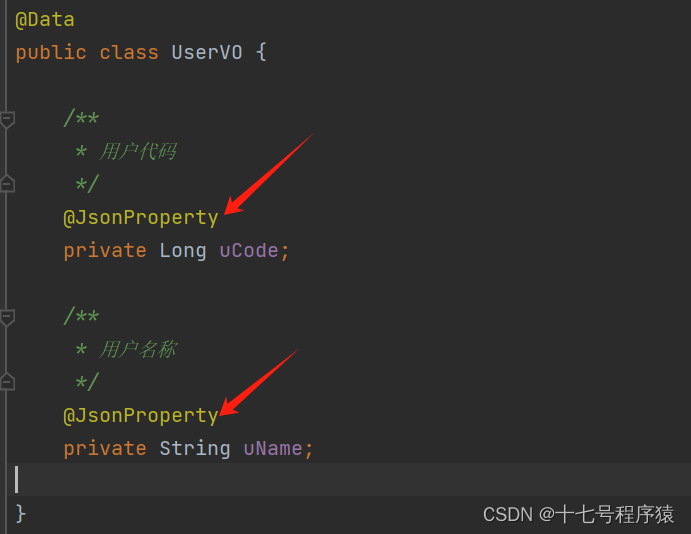
在实体类的属性上方加@JsonProperty注解,如下图:
然后测试控制台打印结果:
原因分析
起首我们先把实体类复原,并且加上一个新的属性loginType
@Data
public class UserVO {
/**
* 用户代码
*/
private Long uCode;
/**
* 用户名称
*/
private String uName;
/**
* 登录类型
*/
private String loginType;
}
复制代码
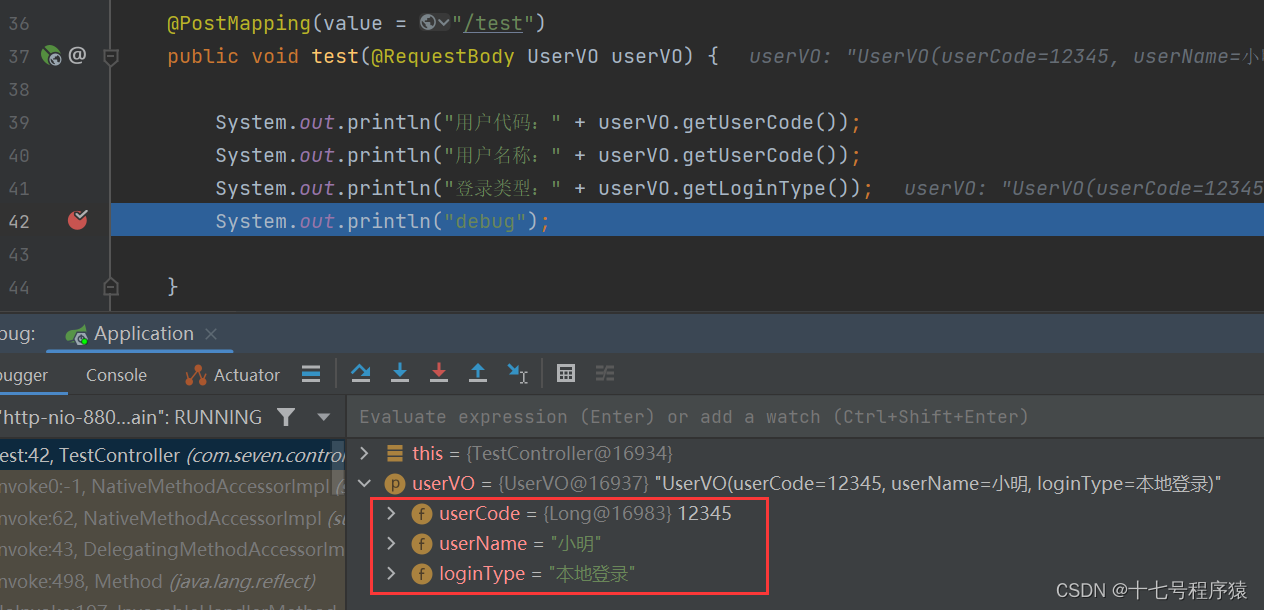
眼尖的同学可能会发现了,我新加的属性loginType长得是不是跟原来两个属性uCode和uName不太一样,不一样的点在于uCode和uName都是首字母小写,第二个字母大写的单词,而loginType则不然。但是它们三都符合驼峰命名法的规范,对吧。这时候可以猜测,难道是这个原因导致的?
在这里我们先来简单验证下uCode、uName、loginType的情况
通过断点发现,uCode、uName是空的,loginType却不是空的
然后我们将uCode、uName分别改为userCode、userName后再进行测试
@Data
public class UserVO {
/**
* 用户代码
*/
private Long userCode;
/**
* 用户名称
*/
private String userName;
/**
* 登录类型
*/
private String loginType;
}
复制代码
这个时候我们就可以得出结论,原因就是首字母小写,第二个字母大写的单词的属性是有题目的。
但是我们不禁要问,为啥呢?它这也符合驼峰命名法的规范啊。为什么它就有题目呢?感兴趣的同学可以接着往下看。
原理分析
起首我们要知道,在Spring中,前后端之间数据传输会涉及到数据的序列化和反序列化的操作,并且SpringBoot默认是使用Jackson作为JSON数据格式处理的类库。
序列化:按照指定的格式、顺序等将实体类对象转换为JSON对象;
反序列化:将JSON对象中的字符串、数字等,将其转换为实体对象;
那么现在咱们就来断点调试Jackson的源码来看看原因。为方便展示,我将实体类留下uName、loginType两个属性
@Data
public class UserVO {
/**
* 用户名称
*/
private String uName;
/**
* 登录类型
*/
private String loginType;
}
复制代码
开始调试:
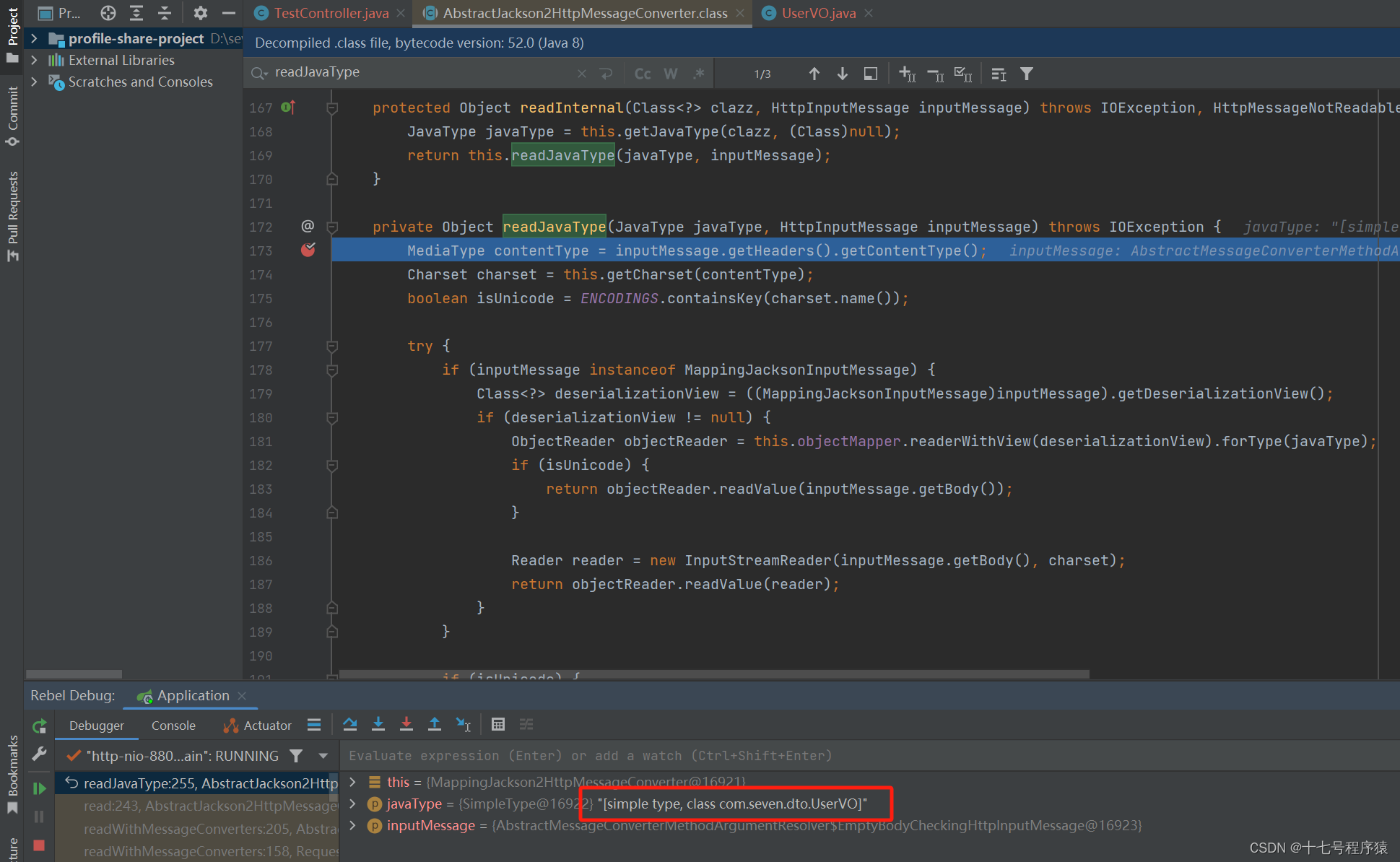
Jackon主要是通过抽象类AbstractJackson2HttpMessageConverter的readJavaType方法将 HTTP 请求中的消息体转换为对象,以是我们找到这部分代码,对他进行断点调试:
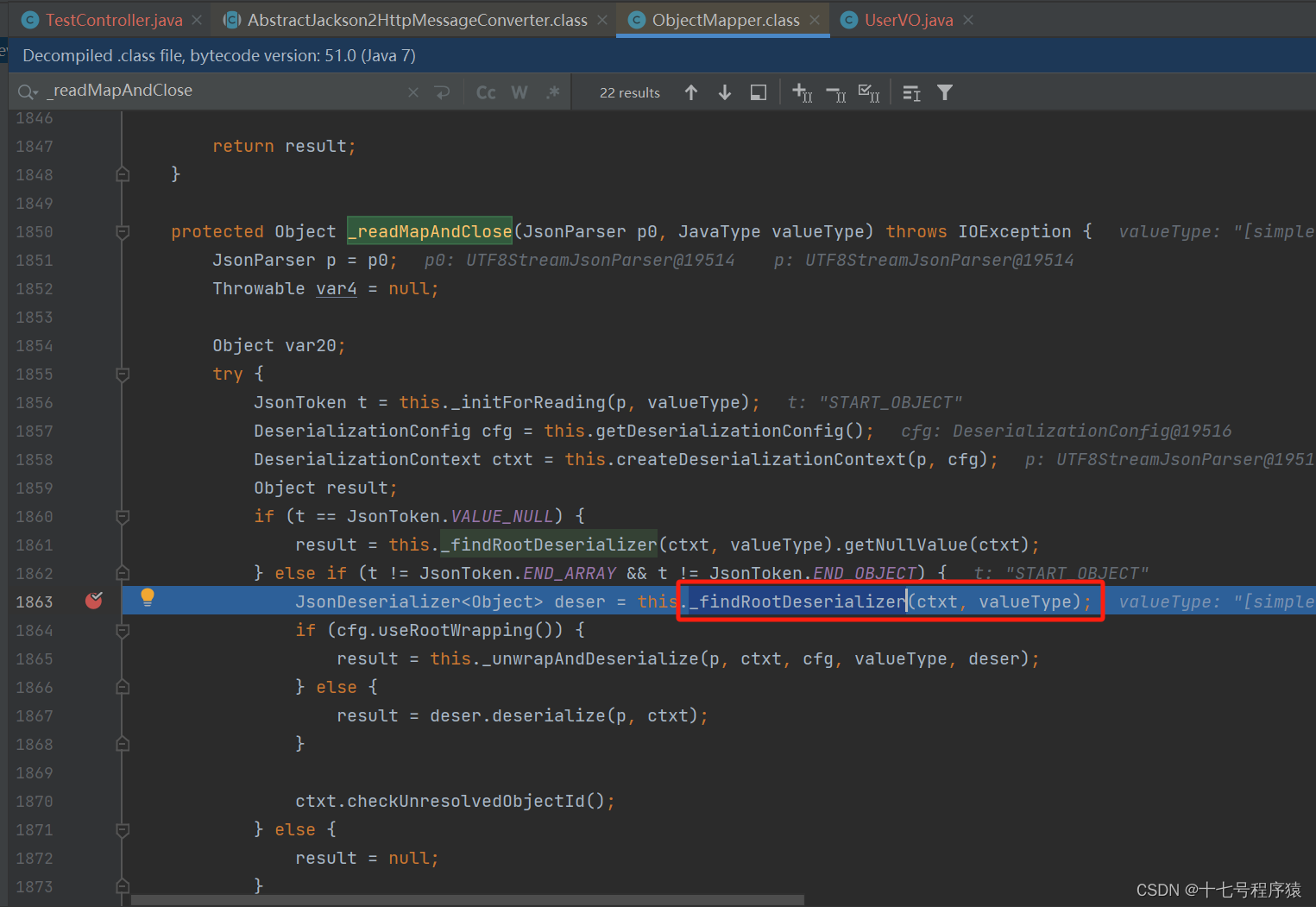
然后逐步断点,在上图的第192行和第195行,它会调用ObjectMapper.readValue,然后断点推进到调用方法的核心地方ObjectMapper的_readMapAndClose方法
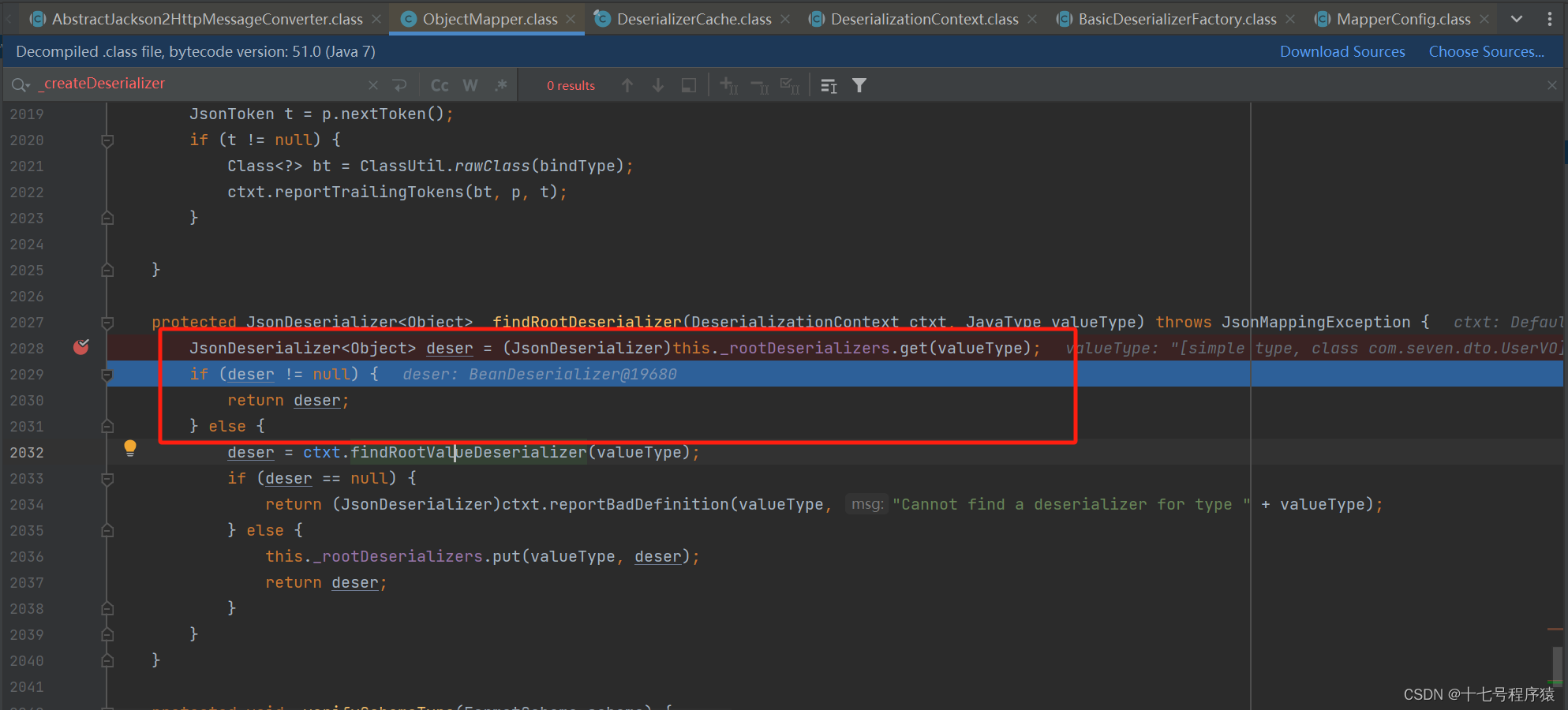
this._findRootDeserializer(ctxt, valueType);的大概意思就是根据类型找到反序列化器,注意在这边是先从缓存中取,取到了的话就直接返回了。假如没到下一步断点,在这边你可以清除一下缓存。
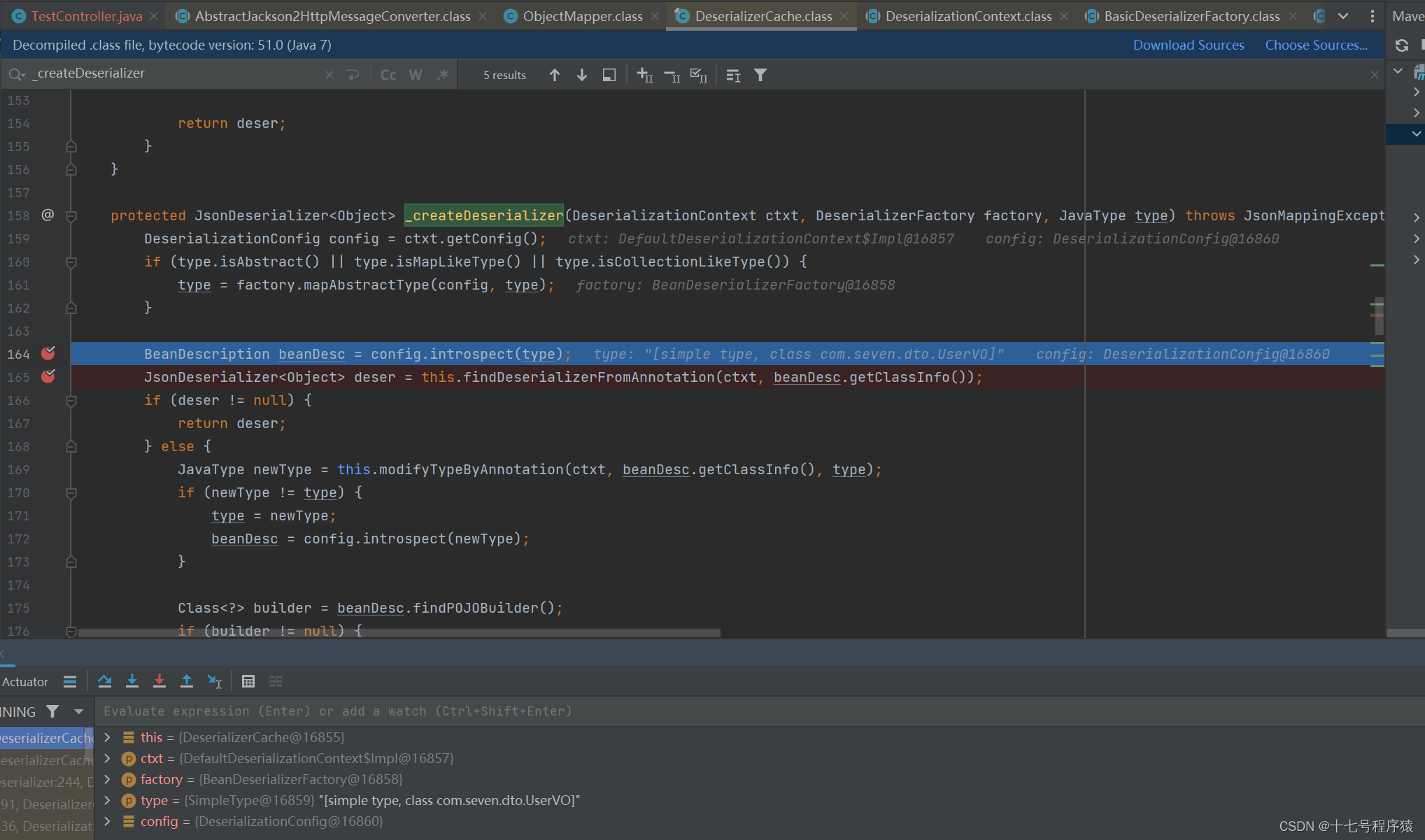
然后断点继续推进到创建反序列化器的地方DeserializerCache._createDeserializer
假如你清除缓存或者重启项目在调用时会直接进入到这个创建反序列化器的地方,你直接在这个方法上打断点就好了
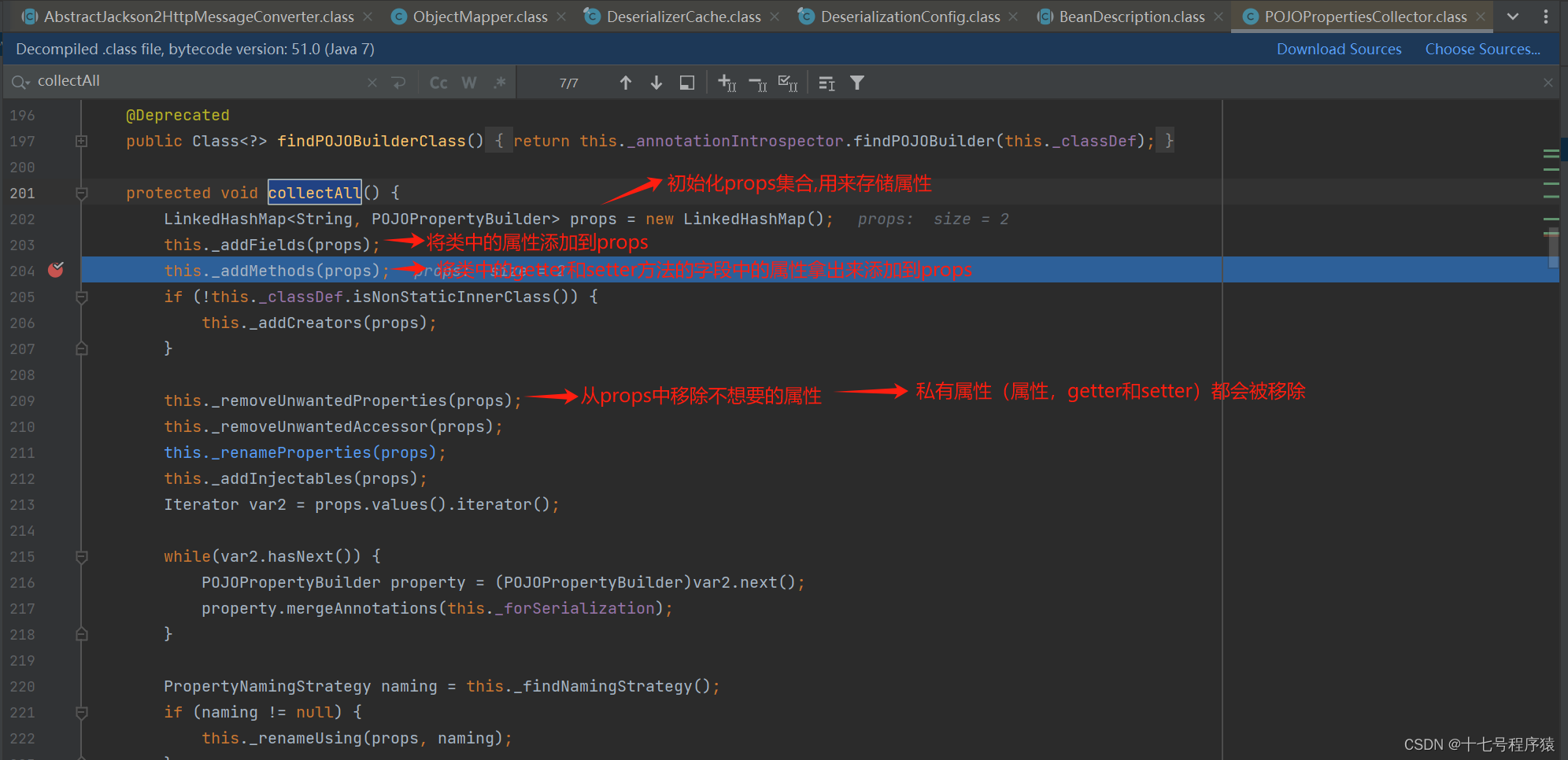
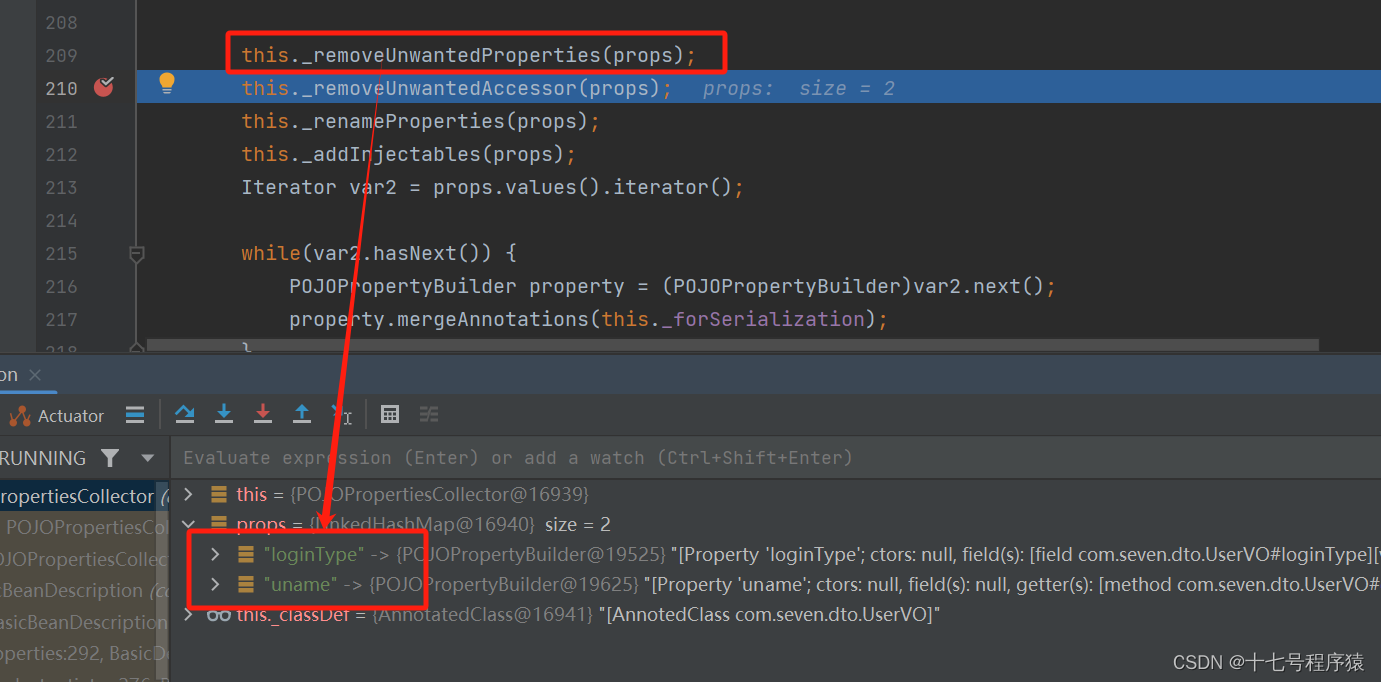
找到上图中第164行的代码,BeanDescription是类的描述的意思,所有的属性都在这里被剖析,然后我们断点进去看看。会进入到POJOPropertiesCollector.collectAll方法,就是字面意思,网络所有。方法逻辑详见下图:
实行完this._addFields(props);后props加入了uName和loginType
实行完this._addMethods(props);后发现props竟然多了一个uname
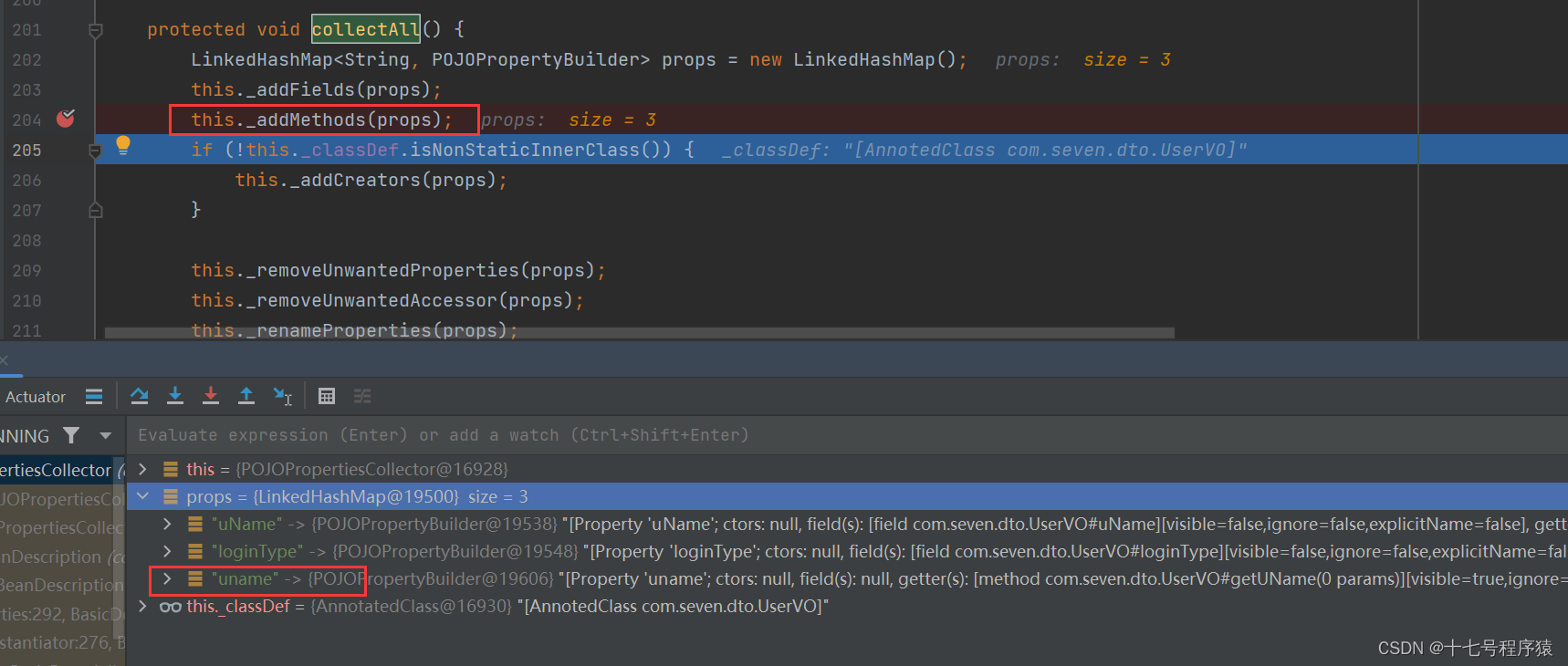
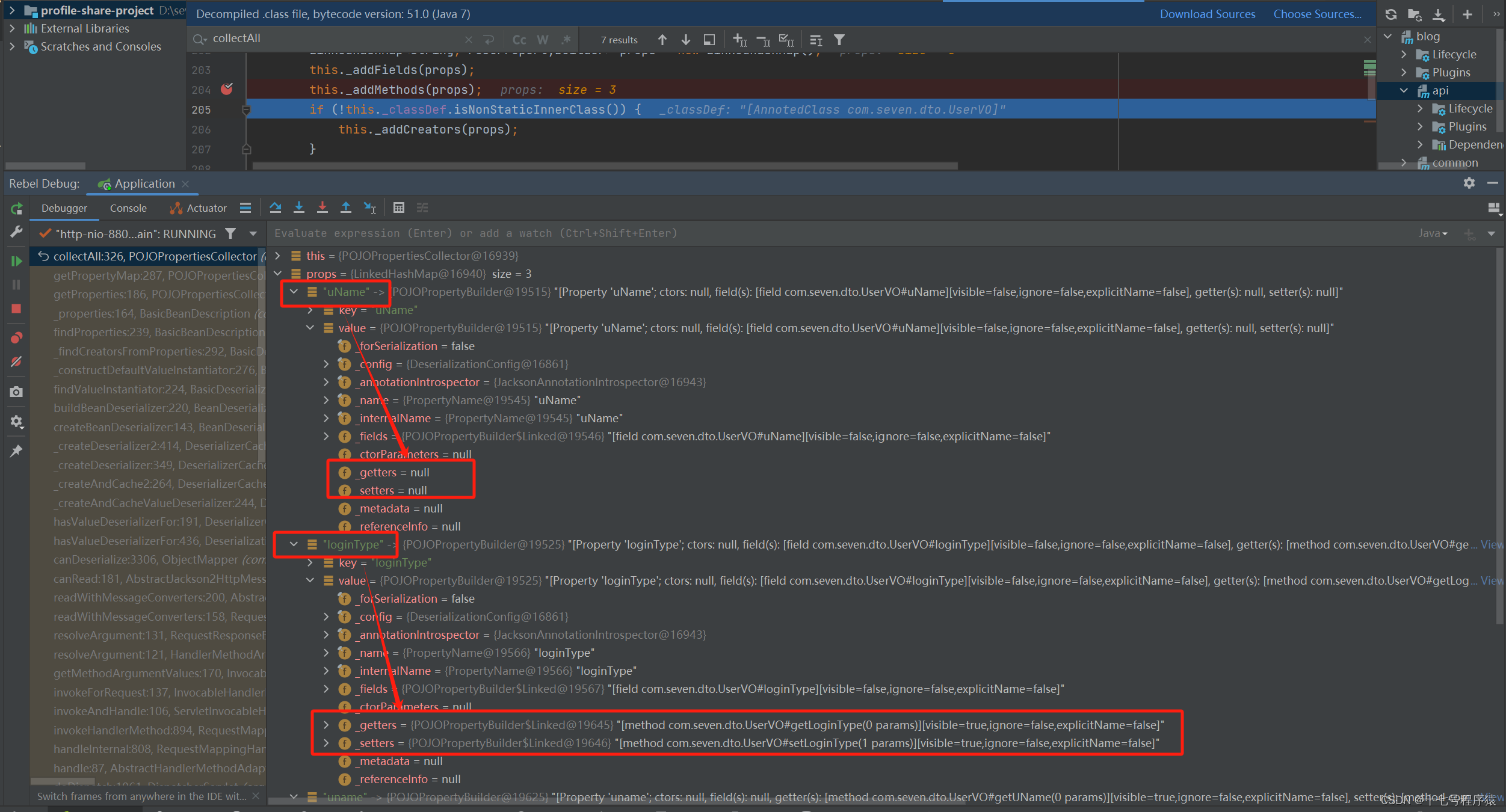
在这里我们点开属性具体去看,会发现uName的get和set为空,但是loginType的是正常的,并且uname这个不知道哪里跑出来的属性的get和set也是不为空的。
再接着实行this._removeUnwantedProperties(props);移除不想要的属性之后,会发现就剩下loginType和uname了,因为uName没有get和set。为什么
然后props中现在存储的就是loginType和uname
现在我们就要弄明白为什么有get/set的是uname而不是uName
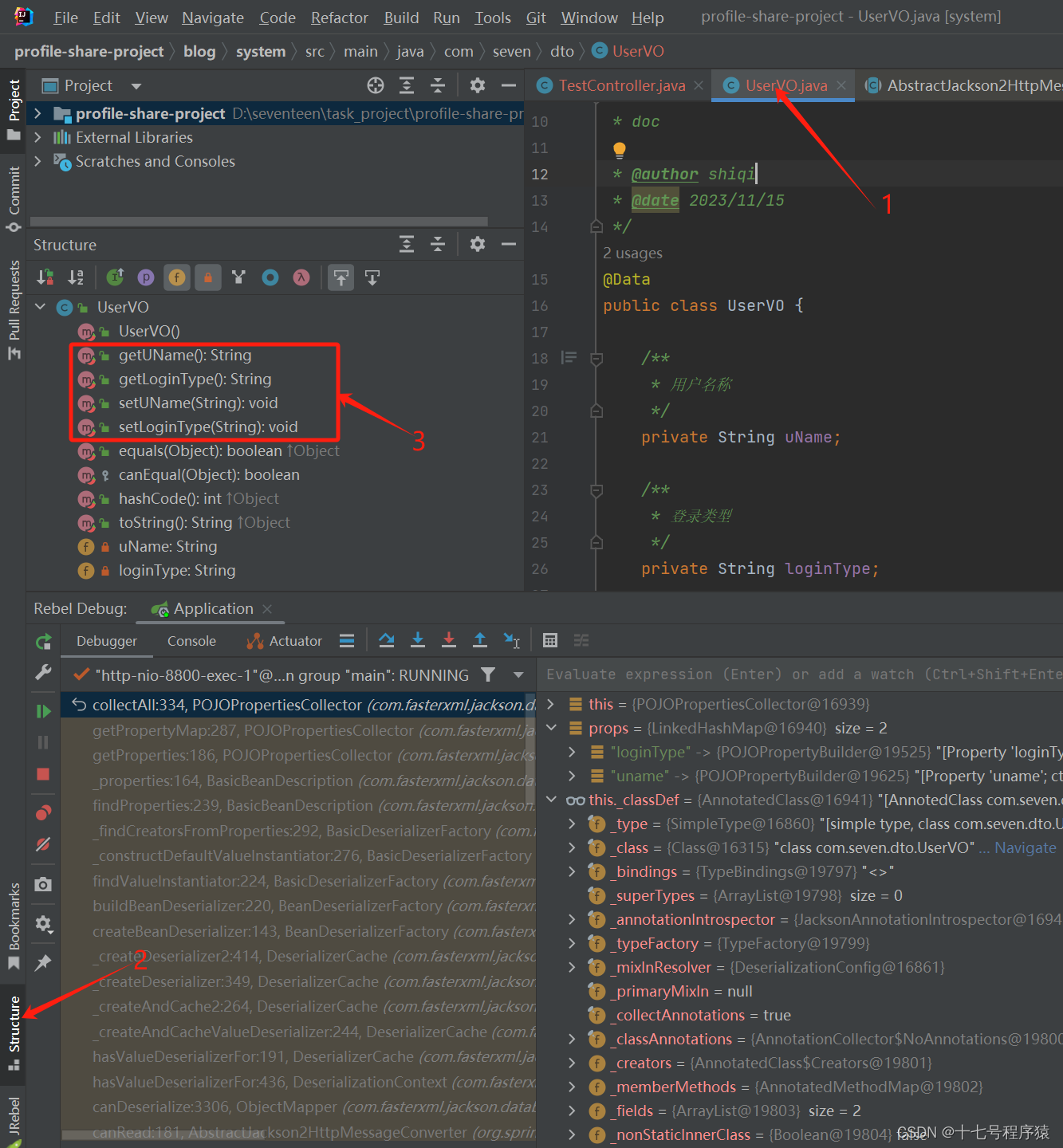
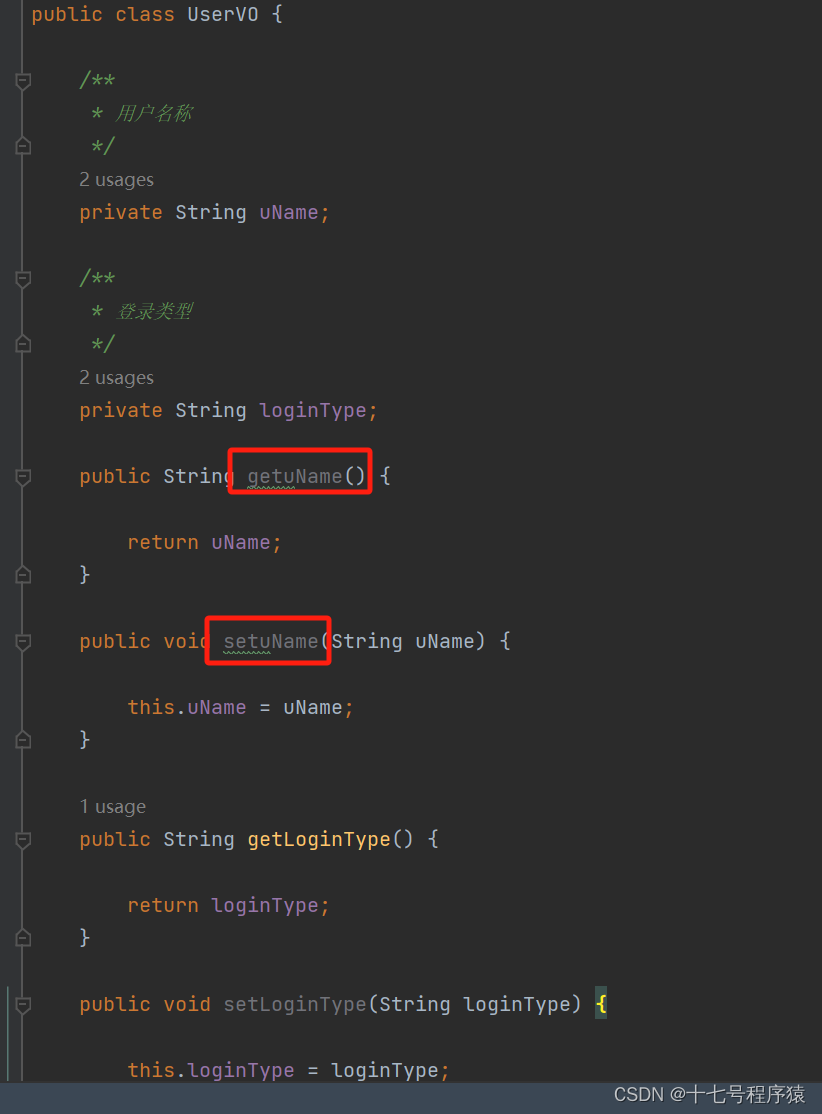
起首,在这个例子中我使用的是@Data注解,也就是使用的 Lombok,也就是说 getter 和 setter 是由 Lombok 天生的。使用注解的话会将get/set方法隐藏起来,然后我们可以通过IDEA的Structure来看,见下图:
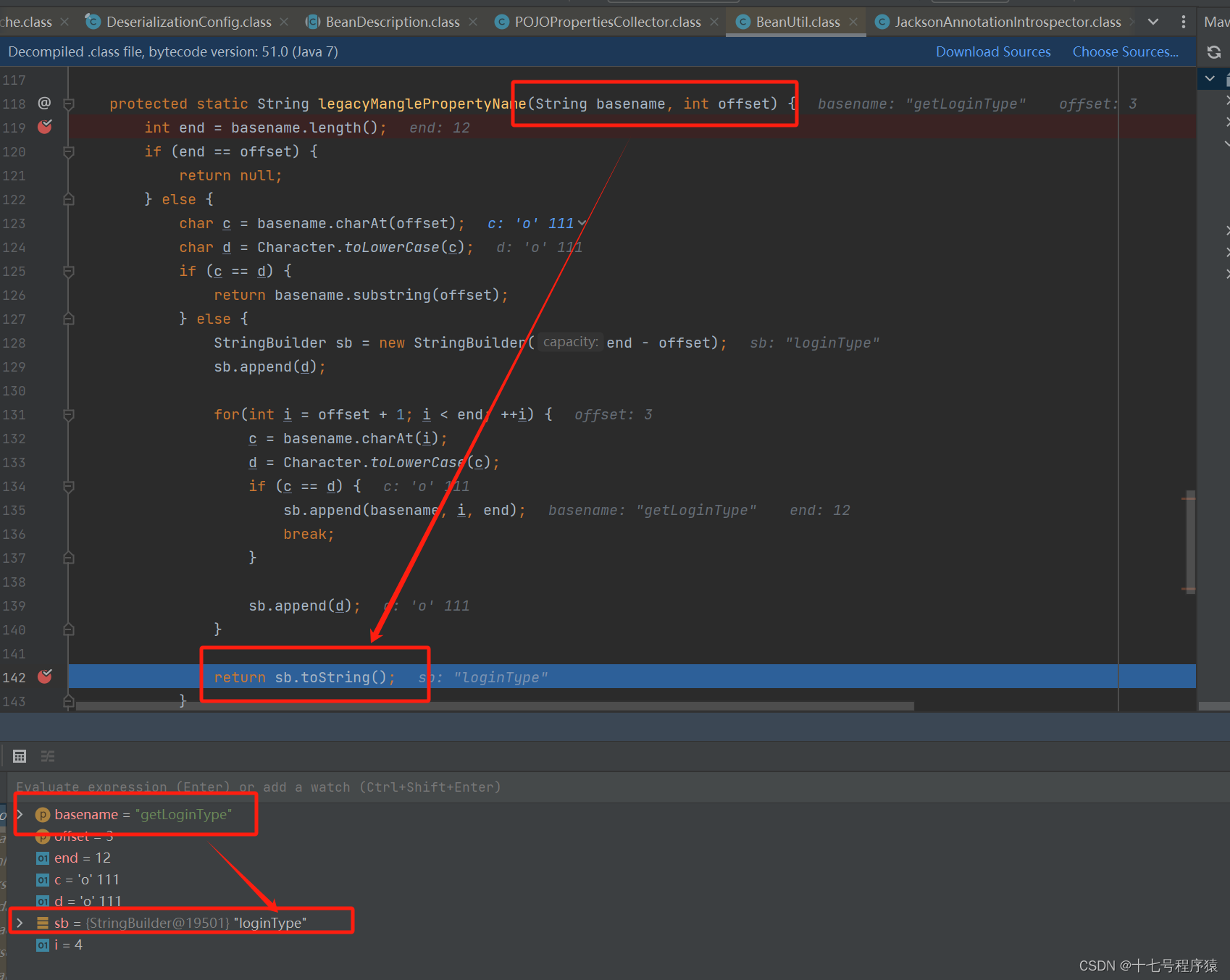
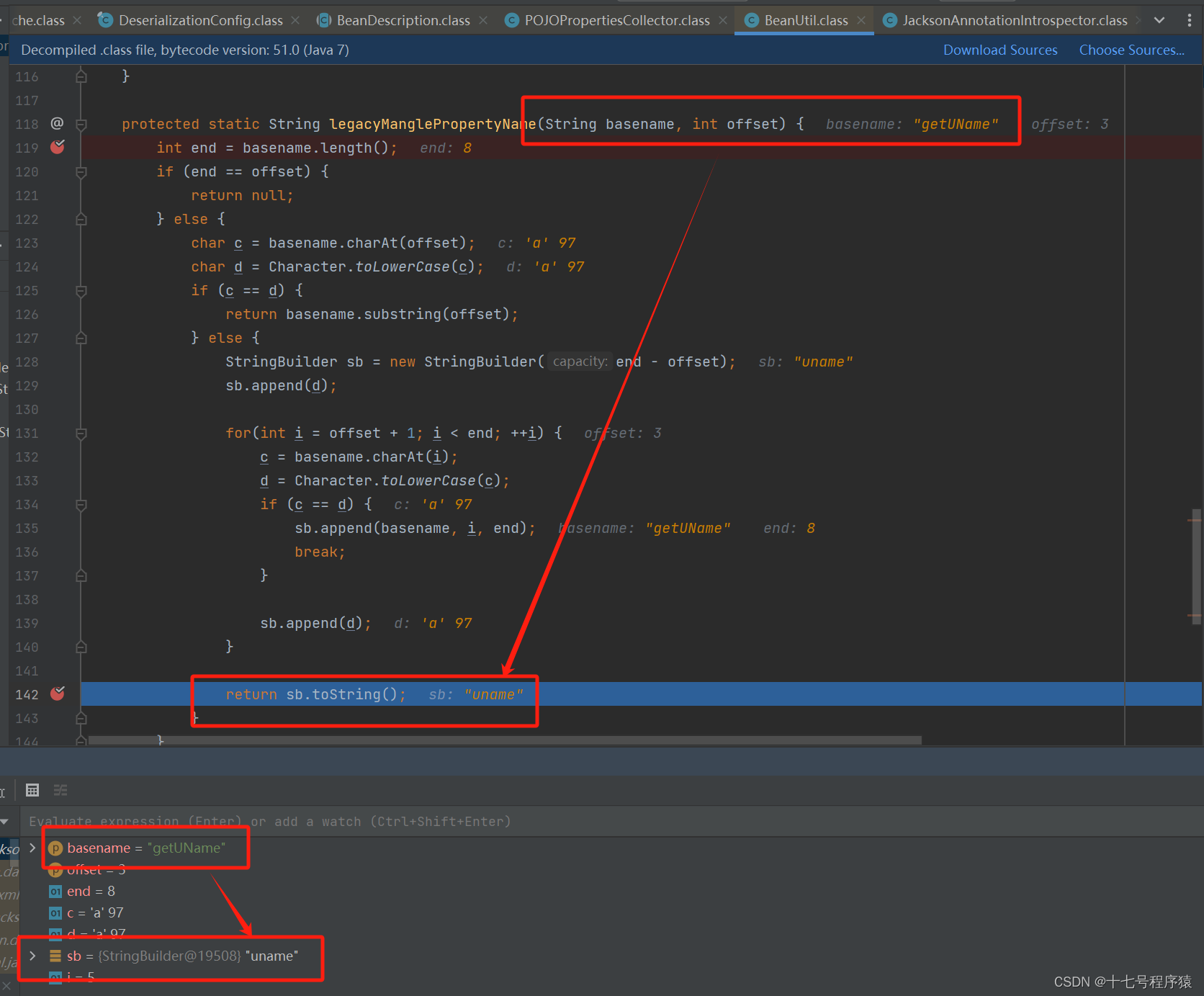
那么Jackson 到底是怎样剖析的,使得剖析出来的是uname,而不是uName。它剖析的具体代码在com.fasterxml.jackson.databind.util.BeanUtil类中的legacyManglePropertyName方法中
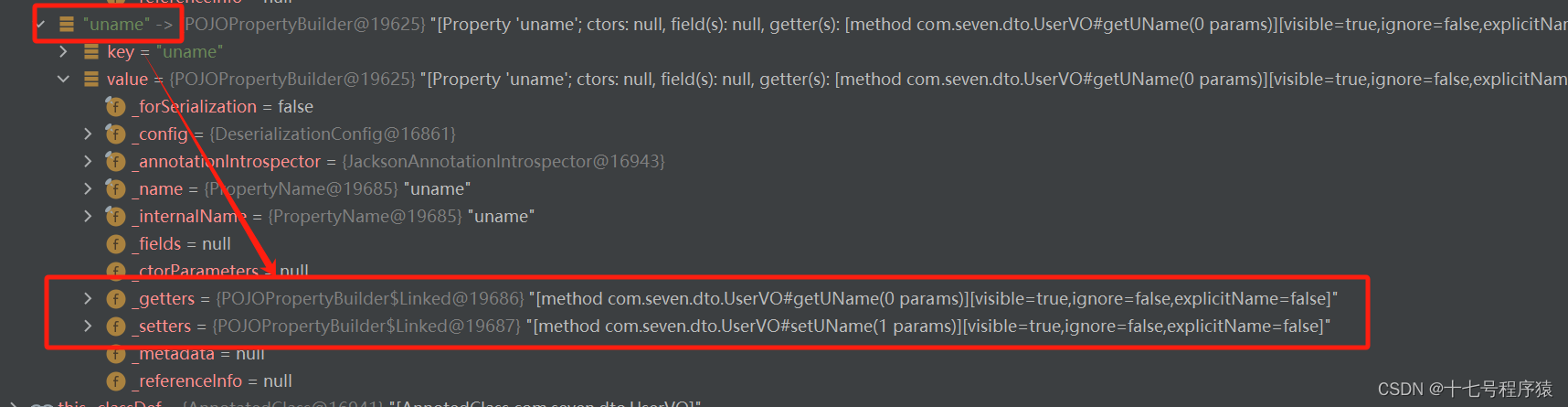
从上图为我们可以很明显的看到,通过这个方法之后getLoginType被剖析成loginType了。那我们再来看看uName,见下图:
从上图断点我们可以清楚的看见getUName被剖析成uname了,按照我们正常的头脑逻辑的话,loginType和uName都符合驼峰命名法的规范,那么uName对应的get方法剖析出来应该是uName啊,为什么变成了uname呢?原因就在于这个legacyManglePropertyName方法的处理逻辑,它的逻辑大概是:
1.根据入参offset去除get或者get,然后就剩下UName或者LoginType了
2.然后从第一个字母开始剖析,假如第一个字母是大写的,于是就将它转成小写,然后找下一个,假如照旧大写,就继续转成小写,直到找到一个小写字母后,就把之后的字母(不管巨细写)一起拼接进来。
如许就能解释了:
去除get之后的LoginType找到第一个字母是大写,转为小写的l,下一个字母是小写的了,就直接把背面的全拼接进来,终极形成了loginType
去除get之后的UName找到第一个字母是大写,转为小写的u,下一个字母又是大写,转为小写的n,在下一个字母是小写的了,就直接把背面的全拼接进来,终极形成了uname
假如说这边的getUName换成getuName,那么剖析出来的就是正确的uName了。
结论
到这里,我们就可以得出结论了
因为 Lombok 天生 get、set 方法的语义规范与和Jackson 处理 get、set 方法之间的不一致,导致属性名无法匹配上,终极也就导致了前端明显传了参数,后端却接收不到的题目。
扩展
我背面去github的 lombok社区 了解了相关内容,lombook社区是如许描述的:
用网页翻译给他翻译成中文,翻译有些不对,但是能看明白大概意思就行
lombok的大概意思就是:我就是如许的规范,即使其他的工具框架都改了,我也不改,但是发起你们不要使用首字母小写第二个字母大写的属性名,避免出现题目,可能着名度比力高的框架都比力傲娇吧哈哈。
但是lombok照旧给出了一个解决方案,加上这个设置项
lombok.accessors.capitalization = [basic | beanspec] (default: basic)
复制代码
此中basic代表遵循lombok的规范(getUName);beanspec代表遵循Spring、Jackson 的规范(getuName)。默认是basic。
看到这里,我就来总结一下能解决这个题目的三种方案吧
1. 加@JsonProperty注解强行指定属性名
@Data
public class UserVO {
/**
* 用户名称
*/
@JsonProperty(value = "uName")
private String uName;
/**
* 登录类型
*/
private String loginType;
}
复制代码
2.不使用lombok,使用IDEA默认天生get/set方法
3.加上lombok设置项
lombok.accessors.capitalization = [basic | beanspec] (default: basic)
复制代码
末了,博主的发起是,尽量不要用这种命名方式,假如非要用,那就加上@JsonProperty注解强行指定属性名,如许比力方便。
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/)
Powered by Discuz! X3.4