IT评测·应用市场-qidao123.com
标题:
【Linux】命名管道 && 共享内存
[打印本页]
作者:
冬雨财经
时间:
2024-6-22 12:57
标题:
【Linux】命名管道 && 共享内存
提示:文章写完后,目次可以自动生成,如何生成可参考右边的资助文档
目次
前言
一、命名管道
1.1、命名管道实现进程间通信的原理
1.2、创建和删除一个命名管道的指令
1.3、匿名管道与命名管道的区别
1.4、用命名管道实现server&client通信
二、共享内存
2.1、共享内存实现进程间通信的原理
2.2、共享内存的相关接口
2.3、实现共享内存完成进程间的通信
三、system V消息队列 - 选学相识即可
四、system V信号量 - 选学相识即可
5个概念:
对于信号量的理论理解:
信号量的操纵
总结
前言
世上有两种耀眼的光芒,一种是正在升起的太阳,一种是正在积极学习编程的你!一个爱学编程的人。各位看官,我衷心的希望这篇博客能对你们有所资助,同时也希望各位看官能对我的文章给与点评,希望我们能够携手共同促进进步,在编程的蹊径上越走越远!
提示:以下是本篇文章正文内容,下面案例可供参考
一、命名管道
管道应用的一个限定就是只能在具有共同祖先(具有亲缘关系)的进程间通信。
假如我们想在不相关的进程之间交换数据,可以利用FIFO文件来做这项工作,它经常被称为命名管道。
命名管道是一种特殊类型的文件。
1.1、命名管道实现进程间通信的原理
第二个进程打开与第一个进程打开雷同文件时,也肯定要在创建一个struct file,缘故原由是打开文件时,也要拿到对应的文件描述符表,也要拿到新的文件描述符,有新的文件指针,就得有新的struct file;还有一个缘故原由:一个以写的方式打开文件,另一个以读的方式打开文件,两个进程之间为了避免相互冲突,创建两个struct file。
匿名管道,两个具有血缘关系的进程,通过父子继续的方式,看到同一个被打开的文件。
那么两个毫无关系的进程看到同一份资源(打开了同一个文件)呢?每一个文件,都有文件路径(唯一性);要保证两个好不干系的进程看到同一个管道文件,就要有同一个路径,要让client和server都能看到同一个管道文件的路径。
1.2、创建和删除一个命名管道的指令
命名管道可以从命令行上创建,命令行方法是利用下面这个命令:
man mkfifo
// 查看创建一个命名管道文件的指令
复制代码
mkfifo myfifo
// 创建一个myfifo为名的管道文件(文件的第一个属性为p)
复制代码
命名管道也可以从步调里创建,相关函数有:
int mkfido(const char *pathname,mode_t mode);
复制代码
第一个参数:创建一个文件所对应的路径 + 文件名;
参数二:创建文件时所对应的权限;
/return val -> 检察函数的返回值,乐成返回0;失败返回-1。
命名管道可以从命令行上删除,命令行方法是利用下面这个命令:
man 2 unlink
// 查看删除管道文件的指令
复制代码
unlink myfile
// 删除指定的myfile特殊的管道文件
复制代码
命名管道也可以从步调里删除,相关函数有:
int unlink(const char* pathname);
// 删除指定目录下的文件
复制代码
1.3、匿名管道与命名管道的区别
匿名管道由pipe函数创建并打开。
命名管道由mkfifo函数创建,打开用open
FIFO(命名管道)与pipe(匿名管道)之间唯一的区别在它们创建与打开的方式差别,一但这些工作完成之后,它们具有雷同的语义。
1.4、用命名管道实现server&client通信
Mikefile
复制代码
Makefile默认只能形成一个可实行步调,会自动匹配第一个目标对象(client),第二个server就不会形成。
要形成两个可实行步调,就界说一个为目标all,all只有依赖关系,依赖的是client server;所以Makefile从上到下扫描时,第一个目标文件叫做all,所以就得先形成client,再形成server;但是all没有依赖方法,所以只要把依赖关系推到完毕,all什么都不做,就相当于一次形成两个可实行步调。
.PHONY:all
all : client server
client : client.cc
g++ - o $@ $ ^ -std = c++11
server:server.cc
g++ - o $@ $ ^ -std = c++11
.PHONY:clean
clean :
rm - rf client server
复制代码
namedPipe.hpp // 命名管道
复制代码
#include <iostream>
#include <cstdio>
#include <cerrno>
#include <string>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
// 把管道文件的路径(公共路径)放在当前路径下,管道文件的名字叫做myfifo
const std::string comm_path = "./myfifo";
// 将文件描述符默认定义为-1
#define DefaultFd -1
// 定义管道文件的创建者和使用者
#define Creater 1
#define User 2
// 以只读和只写的方式打开文件
#define Read O_RDONLY
#define Write O_WRONLY
// 定义一个通信的基本大小
#define BaseSize 4096
class NamePiped
{
private:
// 打开文件(方式)
bool OpenNamedPipe(int mode)
{
_fd = open(_fifo_path.c_str(), mode);
if (_fd < 0)
return false;
return true;
}
public:
// 构造函数
NamePiped(const std::string& path, int who)
: _fifo_path(path), _id(who), _fd(DefaultFd)
{
// 创建者才创建管道文件
if (_id == Creater)
{
// 初始化期间,将管道构建好了
// mkfifo创建命名管道的接口
int res = mkfifo(_fifo_path.c_str(), 0666);
if (res != 0)
{
perror("mkfifo");
}
std::cout << "creater create named pipe" << std::endl;
}
}
bool OpenForRead()
{
return OpenNamedPipe(Read);
}
bool OpenForWrite()
{
return OpenNamedPipe(Write);
}
// const &(输入型参数),比如:const std::string &XXX
// *(输出型参数) 比如: std::string *
// &(输入输出型参数) 比如: std::string &
// 假如双方通信的内容是字符串
int ReadNamedPipe(std::string* out)
{
char buffer[BaseSize];// 定义一个缓冲区
// 将对应文件描述符中的数据读到buffer数组中
int n = read(_fd, buffer, sizeof(buffer));
if (n > 0)
{
buffer[n] = 0;
*out = buffer;// 将buffer数组中的内容带出去了
}
return n;
}
int WriteNamedPipe(const std::string& in)
{
// c_str:C风格的字符串
return write(_fd, in.c_str(), in.size());
}
// 删除管道文件
~NamePiped()
{
if (_id == Creater)
{
// unlink删除管道文件的接口
int res = unlink(_fifo_path.c_str());
if (res != 0)
{
perror("unlink");
}
std::cout << "creater free named pipe" << std::endl;
}
if (_fd != DefaultFd) close(_fd);
}
private:
const std::string _fifo_path;// 管道文件的路径
int _id;// 使用管道文件当前进程的pid
int _fd;// 打开文件的方式,文件描述符
};
复制代码
server.cc // 服务端
复制代码
#include "namedPipe.hpp"
// server进程read的方式打开管道文件,而且也要管理命名管道的整个生命周期
int main()
{
// 利用管道文件的类创建一个变量,并以创建者的身份调用构造函数创建公共的管道文件(comm_path)
NamePiped fifo(comm_path, Creater);
// 对于读端而言,如果我们打开文件,但是写还没来,我会阻塞在open调用中,直到对方打开
// 进程同步
if (fifo.OpenForRead())
{
std::cout << "server open named pipe done" << std::endl;
sleep(3);
while (true)
{
std::string message;
int n = fifo.ReadNamedPipe(&message);// 把对应的数据读到message中
if (n > 0)
{
std::cout << "Client Say> " << message << std::endl;
}
else if (n == 0)
{
std::cout << "Client quit, Server Too!" << std::endl;
break;
}
else
{
std::cout << "fifo.ReadNamedPipe Error" << std::endl;
break;
}
}
}
// 程序结束时,会自动调用析构函数,结束管道文件
return 0;
}
复制代码
client.cc // 客户端
复制代码
#include "namedPipe.hpp"
// write
int main()
{
// 以使用者的身份,只使用公共管道的文件(comm_path)
NamePiped fifo(comm_path, User);
if (fifo.OpenForWrite())
{
std::cout << "client open namd pipe done" << std::endl;
while (true)
{
std::cout << "Please Enter> ";// 请用户输入消息
std::string message;
std::getline(std::cin, message);// 按行从cin中获取消息,将消息输入到message中
fifo.WriteNamedPipe(message);
}
}
return 0;
}
复制代码
二、共享内存
匿名管道和命名管道都是通过复用文件的内核数据结构的代码,来举行进程间的通信;
我们实际在通信时,除了上面的文件版的;系统设计者专门为了通信,在内核当中重新从0搭一套班子,从0开始设计进程间的通信方案;
第一种通信方案:本地通信方案的代码:System V IPC
System V:尺度 IPC:进程间通信
2.1、共享内存实现进程间通信的原理
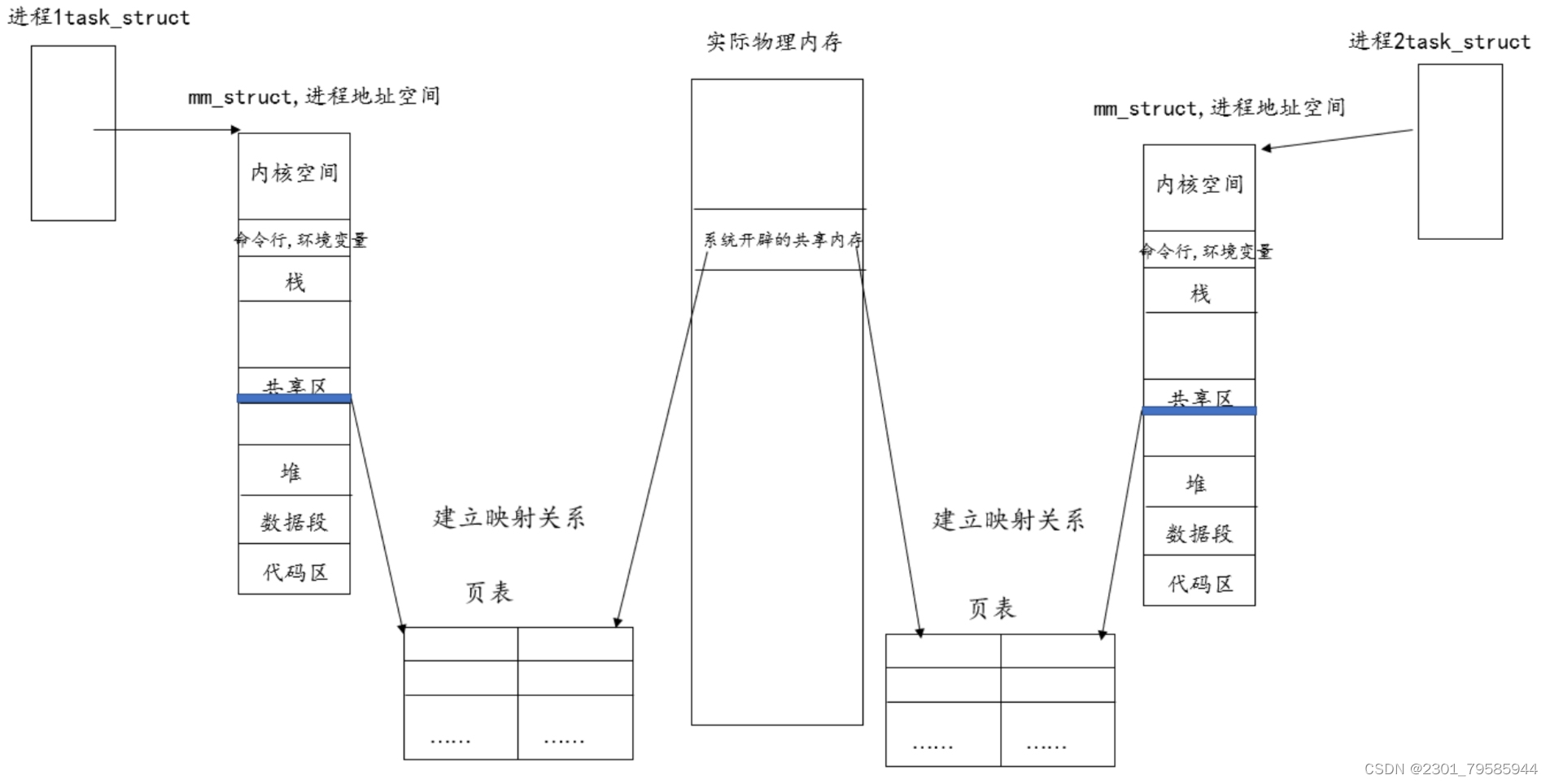
共享内存实现进程间通信,是操纵系统在实际物理内存开辟一块空间,进程1和2都在堆和栈之间存在共享区,进程1和2都是通过各自的页表创建共享内存挂接到各自进程地址空间中的共享区并创建映射关系;
OS系统提供系统调用接口,让用户利用,使一个进程往该空间写入内容时,别的一进程访问该空间,读取写入的值,即实现了进程间的通信;
AB、CD、EF、XY----共享内存在系统中可以同时存在多份,供差别个数,差别对进程同时举行通信;
OS注定了要对共享内存举行管理! --- 先描述,在构造 --- 共享内存,不是简朴的一段内存空间,也要有描述并管理共享内存的数据结构和匹配的算法;
共享内存 = 内存空间(数据) + 共享内存的属性!
描述共享内存的结构体Struct Shm中肯定要有标识共享内存唯一性的字段!
2.2、共享内存的相关接口
man shmget
// 查看申请一个System V版本的共享内存
复制代码
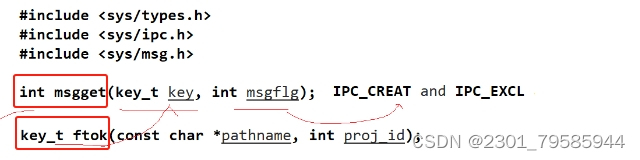
int shmget(key_t key,size_t size,int shmflg);
复制代码
参数1:用户形成的一个key值,这个key值进程A、B都能形成,进程A在创建共享内存时,颠末系统调用把key值设置为共享内存对应的结构体中唯一性的字段,那么此时进程B就能通过这个key值直接找到对应的共享内存(进程A和B不用做任何的通信,就能通过key值看到同一个共享内存);
参数2:共享内存的大小;
参数3:标记位。
参数3:
IPC_CREAT:假如你要创建的共享内存不存在,创建之;假如存在,获取该共享内存并返回;
IPC_EXCL:单独利用没有意义,只有和IPC_CREAT组合才有意义;
IPC_CREAT | IPC_EXCL:假如你要创建的共享内存不存在,创建之;假如存在,出错返回。(假如使乐成返回的话,就意味着共享内存shm使全新的)
key是什么?参考参数1的表明。
为什么要有key?为了让两个进程能通过key值找同一份资源(共享内存)。
key值是用户形成的,用户如何形成的呢?利用ftok()系统调用接口形成。
int ftok(const char* pathname,int proj id);
复制代码
是OS提供的,但不属于系统调用;
需要用户随便设一个路径,随便设一个项目id;
只是做一些算法方面的设计,比如:将参数1和参数2都当作一个整数,两个数字再加一个随机数,形成一个唯一的key值;
返回值:乐成是返回共享内存的标识符(key);失败返回-1,并设置错误码。
b进程怎么知道A进程通过系统调用shmget()接口让OS创建共享内存呢?
进程A和B通过利用同样的ftok()函数,对ftok()函数利用同样的参数,就能得到同样的key值;
进程A将key值设置为共享内存对应的结构体中唯一性的字段,进程B通过ftok()函数,得到同样的key值,从而找到共享内存。
shmget()函数的返回值是共享内存的标识符,ftok()函数的返回值也是共享内存的标识符(key值),着两者有何区别呢?
key:属于用户形成,内核利用的一个字段,用户不能利用key来举行shm的管理。内核举行区分shm的唯一性的字段。(类似于文件的地址);
shmid:内核给用户返回的一个标识符,用来举行用户级对共享内存举行管理的id值。(类似于fd)
原先的进程创建一个文件,进程竣事之后,文件会被自动开释;
但是对于共享内存来说:shmget()函数的参数3利用IPC_CREAT | IPC_EXCL这两个标记位:会看到第一次进程利用shmget()函数创建共享内存,会有对应的key值和共享内存;进程竣事后,第二次进程再次利用shmget()函数创建共享内存,会发现创建共享内存失败,返回-1,因为原先的key值还存在,已经被占用了,所以得出的结论:共享内存不随着进程的竣事而自动开释。
共享内存不是由进程创建的,而是由OS让进程利用shmget()系统调用接口创建的。
我们要开释共享内存,不然共享内存会不停存在,直到系统重启。
手动开释(指令或者其它的系统调用)
控制共享内存
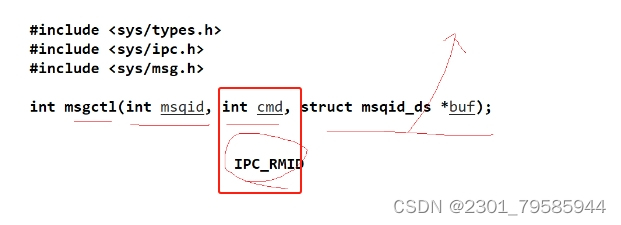
int shmctl(int shmid,int cmd,struct shmid_ds *buf);
// 移除成功返回0,否则失败返回-1
// 参数1:OS给用户的共享内存的标识符
// 参数2:将cmd替换成IPC_RMID
// 参数3:OS提供的一个内核级的数据结构(共享内存),来获取共享内存的属性;也可以设置共享内存的结构体,设置成nullptr就可
复制代码
IPC_RMID:是一个命令,大写的形式,也是一个宏,用来举行标记共享内存当前是被删除的。
IPC_STAT:利用这个命令,使OS在调用shmctl()系统调用接口时,会把内核当中共享内存所有的属性拷贝到参数3的结构体中。
将共享内存段挂接到进程地址空间
// 将System V标准的共享内存挂接到对应的进程地址空间当中
void *shmat(int shmid,const void *shmaddr,int shmflg);
// 参数1:用户级的共享内存标识符;
// 参数2:对应的共享内存挂接到哪个地址上,今天不考虑,设为nullptr;
// 参数3:设置共享内存的访问权限,默认是读写的,设置为0;
// 成功返回:地址空间中,共享内存的起始地址;失败:返回nullptr
复制代码
使共享内存在进程地址空间中分离
int shmdt(const void *shmaddr);
// 参数:shmat()接口的返回值(进程地址空间的起始地址)
复制代码
dt:detach(分离) shm:共享内存 at:attach(挂接、关联的意思)
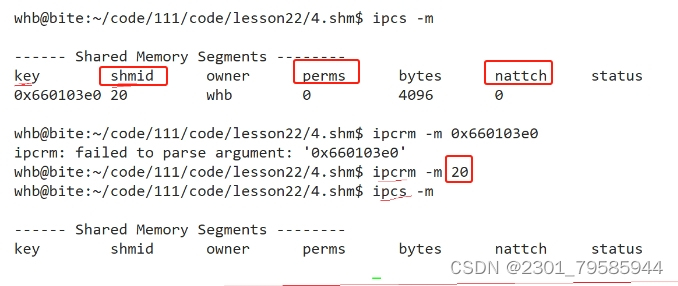
ipcs -m:查找共享内存
perms:共享内存的权限
nattch:当前共享内存被挂接到几个进程地址空间上了
ipcrm -m shmid:删除共享内存(shmid是创建共享内存shmget()系统调用的返回值)
2.3、实现共享内存完成进程间的通信
shm.hpp // 共享内存的所有接口
复制代码
// 共享内存的所有接口 client:客户 server:服务器
// 防止头文件包含
#ifndef __SHM_HPP__
#define __SHM_HPP__
#include <iostream>
#include <string>
#include <cerrno>
#include <cstdio>
#include <cstring>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <unistd.h>
// 定义两个身份标识,一个创建共享内存,一个使用共享内存
const int gCreater = 1;
const int gUser = 2;
const std::string gpathname = "/home/whb/code/111/code/lesson22/4.shm";// 设路径为当前的路径
const int gproj_id = 0x66;// 随便设一个项目id
const int gShmSize = 4097; // 定义一个共享内存的大小,建议共享内存的大小为4096的整数倍
class Shm
{
private:
// 获取公共的key值
key_t GetCommKey()
{
// string类型的对象_pathname中的C格式的字符串
key_t k = ftok(_pathname.c_str(), _proj_id);
if (k < 0)
{
perror("ftok");
}
return k;
}
// 创建一个共享内存的公共的方法
int GetShmHelper(key_t key, int size, int flag)
{
int shmid = shmget(key, size, flag);
if (shmid < 0)
{
perror("shmget");
}
return shmid;
}
// 将角色转换成字符串
std::string RoleToString(int who)
{
if (who == gCreater)
return "Creater";
else if (who == gUser)
return "gUser";
else
return "None";
}
// 将共享内存挂接到进程的地址空间中
void* AttachShm()
{
if (_addrshm != nullptr)
DetachShm(_addrshm);
// shmat():挂接到进程地址空间的接口
void* shmaddr = shmat(_shmid, nullptr, 0);
if (shmaddr == nullptr)
{
perror("shmat");
}
std::cout << "who: " << RoleToString(_who) << " attach shm..." << std::endl;
return shmaddr;// 返回进程的地址空间的起始地址
}
// 分离共享内存和进程地址空间的关联
void DetachShm(void* shmaddr)
{
if (shmaddr == nullptr)
return;
// shmdt()接口
shmdt(shmaddr);
std::cout << "who: " << RoleToString(_who) << " detach shm..." << std::endl;
}
public:
Shm(const std::string& pathname, int proj_id, int who)
: _pathname(pathname), _proj_id(proj_id), _who(who), _addrshm(nullptr)
{
_key = GetCommKey();
if (_who == gCreater)
GetShmUseCreate();
else if (_who == gUser)
GetShmForUse();
_addrshm = AttachShm();// 创建好共享内存之后,就直接挂接到进程地址空间中
std::cout << "shmid: " << _shmid << std::endl;
std::cout << "_key: " << ToHex(_key) << std::endl;
}
~Shm()
{
if (_who == gCreater)
{
// shmctl():删除指定的共享内存
int res = shmctl(_shmid, IPC_RMID, nullptr);
}
std::cout << "shm remove done..." << std::endl;
}
// 将key值转16进制
std::string ToHex(key_t key)
{
char buffer[128];
// snprintf()进行格式化输出,将输出的内容放在一个缓冲区里,将key格式化成0x16进制
// 因为使用ipcs -m指令查找到的共享内存的key值是0x16进制的
snprintf(buffer, sizeof(buffer), "0x%x", key);
return buffer;
}
// 使用一个创建共享内存的公共的方法来创建一个共享内存
bool GetShmUseCreate()
{
if (_who == gCreater)
{
_shmid = GetShmHelper(_key, gShmSize, IPC_CREAT | IPC_EXCL | 0666);
if (_shmid >= 0)
return true;
std::cout << "shm create done..." << std::endl;
}
return false;
}
// 使用者使用共享内存
bool GetShmForUse()
{
if (_who == gUser)
{
// 共享内存创建者创建好之后,使用者不需要再创建了
_shmid = GetShmHelper(_key, gShmSize, IPC_CREAT | 0666);
if (_shmid >= 0)
return true;
std::cout << "shm get done..." << std::endl;
}
return false;
}
// 将共享内存清0
void Zero()
{
if (_addrshm)
{
// 将_addrshm共享内存全部初始化为0
memset(_addrshm, 0, gShmSize);
}
}
void* Addr()
{
return _addrshm;
}
// 获取共享内存的属性
void DebugShm()
{
struct shmid_ds ds;
// IPC_STAT:使用这个命令,使OS在调用shmctl()系统调用接口时,会把内核当中共享内存所有的属性拷贝到参数3的结构体中
int n = shmctl(_shmid, IPC_STAT, &ds);
if (n < 0) return;
std::cout << "ds.shm_perm.__key : " << ToHex(ds.shm_perm.__key) << std::endl;
std::cout << "ds.shm_nattch: " << ds.shm_nattch << std::endl;
}
private:
key_t _key;// 共享内存中唯一性的标识符
int _shmid;// OS给用户使用的共享内存的标识符
std::string _pathname;// 为了ftok()函数的参数1随机设置一个共享内存的路径变量
int _proj_id; // 为了ftok()函数的参数2随机设置一个共享内存的id变量
int _who;// 进程的身份
void* _addrshm;// 共享内存挂接到进程地址空间的起始地址的变量
};
#endif
复制代码
server.cc // 服务端(读端)
复制代码
#include "Shm.hpp"
#include "namedPipe.hpp"
int main()
{
// 1. 创建共享内存
// 使用Shm的类型创建一个shm的对象,调用构造函数
Shm shm(gpathname, gproj_id, gCreater);
char* shmaddr = (char*)shm.Addr();
shm.DebugShm();
// // 2. 创建管道
// NamePiped fifo(comm_path, Creater);
// fifo.OpenForRead();
// while(true)
// {
// // std::string temp;
// // fifo.ReadNamedPipe(&temp);
// std::cout << "shm memory content: " << shmaddr << std::endl;
// }
sleep(5);
return 0;
}
复制代码
client.cc // 客户端(写端)
复制代码
#include "Shm.hpp"
#include "namedPipe.hpp"
int main()
{
// 1. 创建共享内存
Shm shm(gpathname, gproj_id, gUser);
shm.Zero();
char* shmaddr = (char*)shm.Addr();// 返回共享内存挂接到进程地址空间的起始地址
sleep(3);
// 2. 打开管道
NamePiped fifo(comm_path, User);
fifo.OpenForWrite();
// 当成string
char ch = 'A';
while (ch <= 'Z')
{
// 将shmaddr当作一个数组,每隔两秒向共享内存中写入一个字符
shmaddr[ch - 'A'] = ch;
std::string temp = "wakeup";
std::cout << "add " << ch << " into Shm, " << "wakeup reader" << std::endl;
fifo.WriteNamedPipe(temp);
sleep(2);
ch++;
}
return 0;
}
复制代码
共享内存不提供对共享内存的任何保护机制,比如:写端向共享内存中写入hello world数据,读端是不会等待写端的,会直接读取数据,写端大概只写了hello数据,还来不及写入world数据,就被读端读取了,读取的数据需要解析,但是数据不完整,会解析有误。这种题目叫做数据不一致。
所以我们可以提供管道的机制,管道提供了同步机制,让客户端和服务端两个进程除了创建共享内存之外,也把管道创建好;服务器读数据之前,都得先读管道,管道里没数据,就等待;当客户端写完数据后,让管道关照服务器,使服务器从管道中读取数据。
至于管道文件里写入和读取什么样的数据,这些不重要;重要的是我们让管道文件的同步机制来变相的使两个进程在共享内存中写入和读取数据的过程也创建同步机制。
我们在上面管道文件的 namedPipe.hpp 和 Mikefile 文件就看拿下来,这里就不拿了。
我们在访问共享内存的时间,没有效任何的系统调用。
共享内存是所有进程间通信(IPC)中,速度最快的,因为,共享内存大大淘汰了数据的拷贝次数!
命名管道:写入数据时,先将数据写入语言级的缓冲区,再通过文件描述符表找到文件的地址,将数据拷贝到文件级的内核缓冲区;读取数据时,先通过文件描述符表找到文件的地址,将文件级的内核缓冲区的数据拷贝到用户级的缓冲区。
共享内存:因为物理内存中的共享内存被挂接到了进程的地址空间中的堆栈之间的共享区,所以可以直接通过进程地址空间返回的起始地址写入共享内存中,大大淘汰了拷贝的次数,所以说共享内存是速度最快的通信方式。
三、system V消息队列 - 选学相识即可
原理:OS能够开辟结构性的内存空间,OS会在OS内部给我们申请一个消息队列(msg_queue),刚开始队列为空,然后我们有两个进程A和B,进程A可以利用消息队列的系统调用接口,来向消息队列中放入节点,数据块会自动的来连入消息队列;因为进程间通信要让两个进程看到同样的资源,所以进程B也可以往消息队列中放入节点;它们都往公共的队列里放节点时,那么此时B可以拿A放的节点,A也可以拿B放的节点,这种方式叫消息队列。
因为进程A和B都在消息队列中放入许多的节点,为了区分这些节点,所以要求消息队列中发出去的节点都必须叫做有类型。
消息队列提供了一个从一个进程向别的一个进程发送一块数据的方法
每个数据块都被认为是有一个类型,接收者进程接收的数据块可以有差别的类型值
IPC资源必须删除,否则不会自动清除,除非重启,所以system V IPC资源的生命周期随内核
获取消息队列
控制消息队列
四、system V信号量 - 选学相识即可
5个概念:
多个实行流(进程),能看到的一份资源:共享资源;
被保护起来的资源 --- 临界资源 --- 用同步和互斥的方式保护共享资源 --- 临界资源;
互斥:任何时刻只能有一个进程在访问资源;
资源 --- 要被步调员访问 --- 资源被访问,朴素的认识,就是通过代码访问 --- 访问 = 访问共享资源的代码(临界区) + 不访问共享资源的代码(非临界区);
所谓的对共享资源举行保护 --- 临界资源 --- 本质是对访问共享资源的代码和保护(临界区)!
同步:让多个实行流之间,在实行时,具有肯定的次序性。
互斥:一个公共资源时,我正在访问,你就不能访问,任何一个时刻,只允许我一个人访问这部门公共资源。
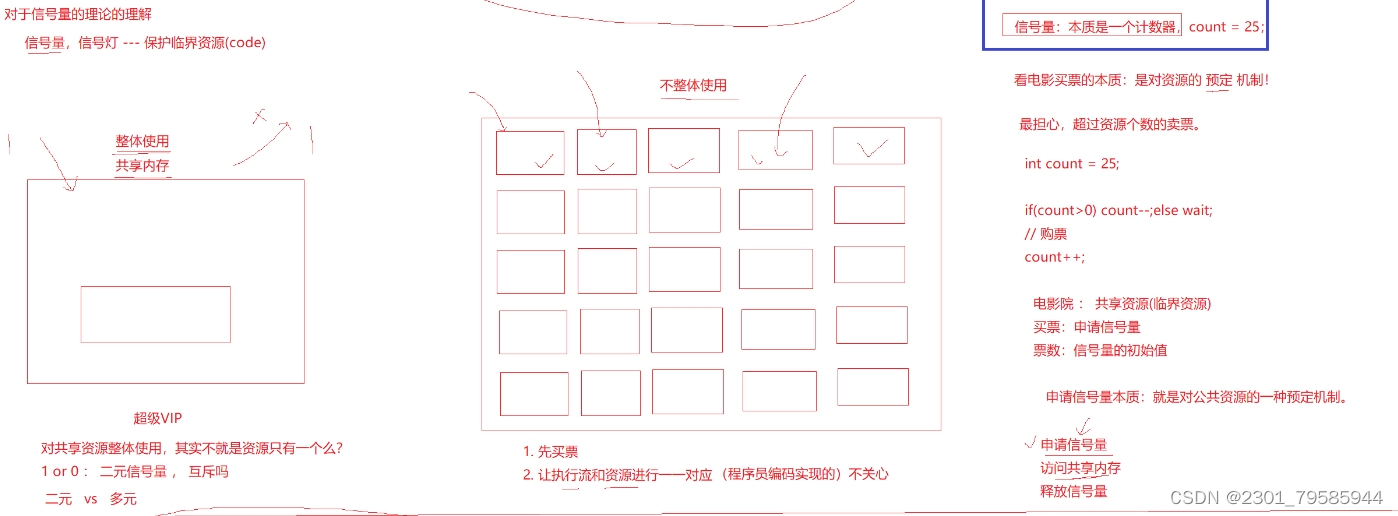
对于信号量的理论理解:
假如共享内存中有1000字节,可以把1000字节看成50字节一块一块的小的内存块,我们不想团体利用1000个字节的共享内存,那么A进程访问第一块50个字节的区域,B进程访问第5块50个字节大小的区域,C进程访问第n个50个字节大小的区域....,可以允许多个实行流同时访问共享内存中的局部性的资源。
if (gcount > 0)
{
gcount--;
}
else
{
wait;// 等待的过程,就是++的时候(联想电影院的票数)
}
复制代码
信号量的本质:就是一个计数器,比如:gcount = 25.
申请信号量 -- ->就是P操纵;访问公共资源(共享内存);开释信号量 ++ ->就是V操纵。
申请和开释信号量,还要保证安全性,叫做PV操纵。
可不可以用一个进程级别的全局变量来充当对公共资源的保护呢?不能。
缘故原由:对于父子进程来说,会发生写实拷贝;对于两个绝不干系的进程来说,一个进程界说一个全局变量,另一个进程是看不到的;所以要用信号量来对公共资源的保护。
信号量也是一个公共资源。
信号量的操纵
允许用户一次申请多个信号量,多个信号量叫信号量集(用数组来维护的)。
int semget(key_t key,int nsems,int semflg);// 获取信号量
// 参数2:申请一个信号量集中有几个信号量
复制代码
允许用户一次申请多个信号量和一个信号量的值为n是两个概念
总结
好了,本篇博客到这里就竣事了,假如有更好的观点,请及时留言,我会认真观看并学习。
不积硅步,无以至千里;不积小流,无以成江海。
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 IT评测·应用市场-qidao123.com (https://dis.qidao123.com/)
Powered by Discuz! X3.4