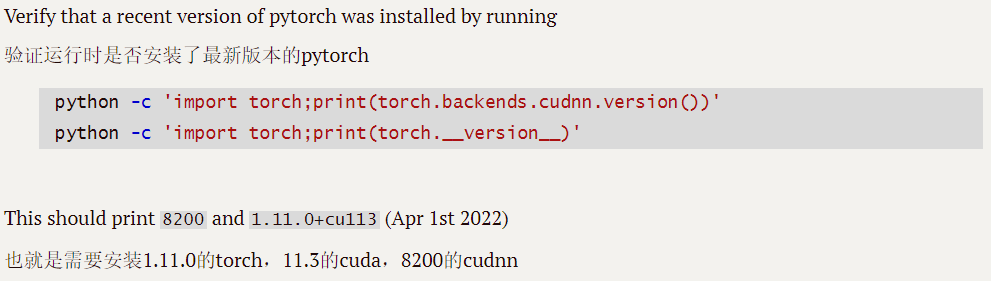
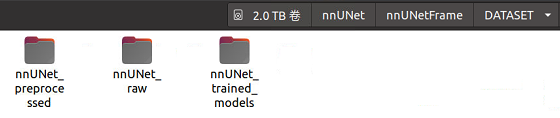
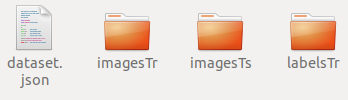
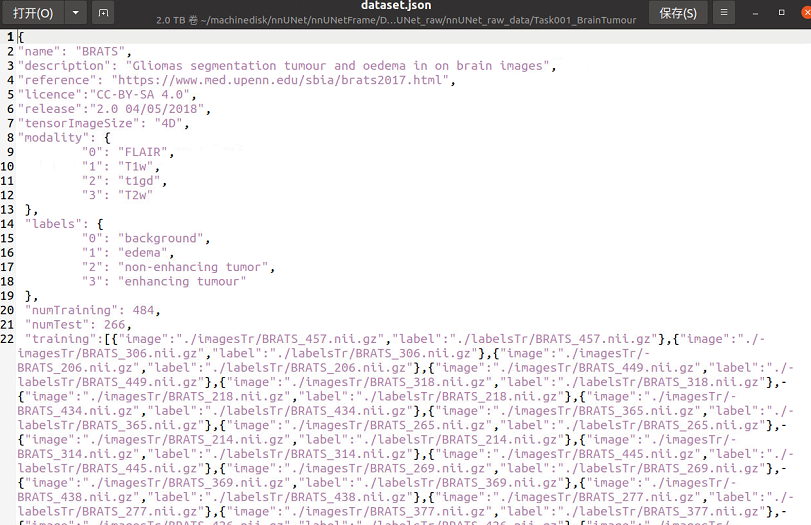
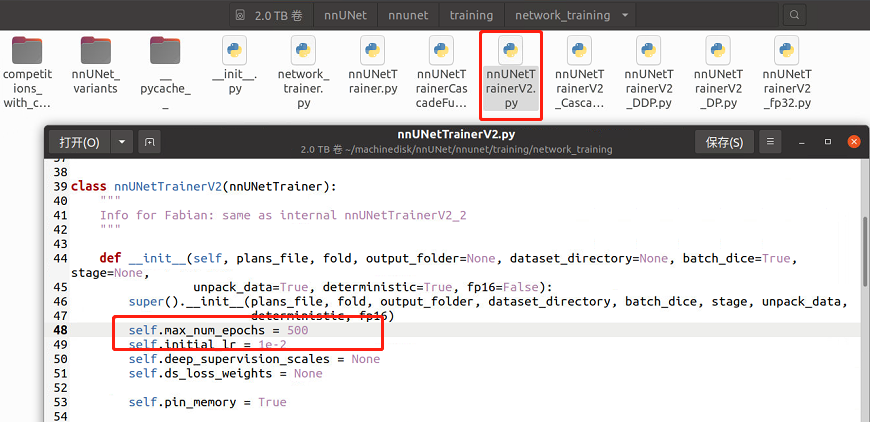
nnU-Net是由德国癌症研究中央、海德堡大学以及海德堡大学医院研究人员(Fabian Isensee, Jens Petersen, Andre Klein)提出来的一个自顺应任何新数据集的医学影像分割框架,该框架能根据给定命据集的属性自动调解所有超参数,整个过程无需人工干预。仅仅依赖于质朴的U-Net结构(就是原始U-Net)和鲁棒的练习方案,nnU-Net在六个得到公认的分割挑衅中实现了最先进的性能。
关于nnUNet,假如你想更加深入的相识,我推荐看一下这篇博客论文解读- nnU-Net: Self-adapting Framework for U-Net-Based Medical Image Segmentation(附实现教程)_Tina姐的博客-CSDN博客,是比力概括性的解说,更深入的学习照旧发起精读论文。
https://blog.csdn.net/u014264373/article/details/116792649
(四:2020.07.28)nnUNet最舒服的练习教程(让我的奶奶也会用nnUNet(上))(21.04.20更新)_花卷汤圆的博客-CSDN博客_nnuet
(五:2020.07.31)nnUNet最简单的推理教程(让我的奶奶也会用nnUNet(下))_花卷汤圆的博客-CSDN博客_nnunet推理
医学图像分割 3D nnUNet全流程快速实现_打南边来了个阿楠的博客-CSDN博客
论文解读- nnU-Net: Self-adapting Framework for U-Net-Based Medical Image Segmentation(附实现教程)_Tina姐的博客-CSDN博客
医学图像分割 3D nnUNet全流程快速实现_打南边来了个阿楠的博客-CSDN博客
论文解读- nnU-Net: Self-adapting Framework for U-Net-Based Medical Image Segmentation(附实现教程)_Tina姐的博客-CSDN博客 码字不易,您的点赞是对我最好的支持,假如有题目也接待在评论区或私信与我交流!