ToB企服应用市场:ToB评测及商务社交产业平台
标题:
hadoop(1)--hdfs部署(亲测可用)
[打印本页]
作者:
张国伟
时间:
2024-6-29 14:31
标题:
hadoop(1)--hdfs部署(亲测可用)
一、预备:
1、三台集群部署,配置hosts
#cat /etc/hosts
192.168.46.128 node1 #nameNode dataNode secondaryNameNode
192.168.46.129 node2 #datanode
192.168.46.130 node3 #datanode
复制代码
说明:
NameNode: 主节点管理者
DataNode:从节点工作者
SecondaryNameNode:主节点辅助
2、三台节点做相互免密。
node1 ->node2; node1->node3;
node2 ->node1; node2 ->node3;
node3 ->node1; node3 ->node2;
复制代码
天生ssh
ssh-key-gen -t rsa #一路回车
ssh-copy-ip 节点名称 # 拷贝公钥
复制代码
3、安装java环境
#1、 上传安装包,解包。
cd /usr/local/java/
#2、修改profile配置文件,最后追加
# vim /etc/profile
JAVA_HOME=/usr/local/java/jdk1.8.0_221
CLASSPATH=$JAVA_HOME/lib/
PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH
复制代码
二、上传hadoop安装包
1、创建hadoop目次
mkdir /data/hadoop
复制代码
三、修改配置文件
所有配置文件都在hadoop包中etc目次下:
1、修改core-site.xml文件
# vim hadoop-3.3.6/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
复制代码
2、修改hadoop-env.sh文件
# vim hadoop-3.3.6/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/java #修改安装的Java目录
export HADOOP_HOME=/data/hadoop/hadoop-3.3.6 #修改当前hadoop的路径
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
复制代码
3、修改hdfs-site.xml文件
# vim hadoop-3.3.6/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop/data/nn</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>node1,node2,node3</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop/data/dn</value>
</property>
</configuration>
复制代码
4、修改workers配置
#vim hadoop-3.3.6/etc/hadoop/workers
node1
node2
node3
复制代码
5、创建数据目次
# node1 节点创建:mkdir /data/hadoop
/data/dnmkdir /data/hadoop
/data/nn# node2、 node3 节点创建:mkdir /data/hadoop
/data/dn
复制代码
6、创建hadoop用户,并授权
useradd hadoop
# 以root身份,在三台服务器上均执行
chown -R hadoop:hadoop /data/hadoop
复制代码
7、格式化NaneNode
#1、在主节点虚拟机node1中切换到hadoop用户
su - hadoop
#2. 格式化namenode
hadoop namenode -format
复制代码
四、启动集群
1、启动hdfs集群
cd /data/hadoop/hadoop-3.3.6
./sbin/start-dfs.sh
复制代码
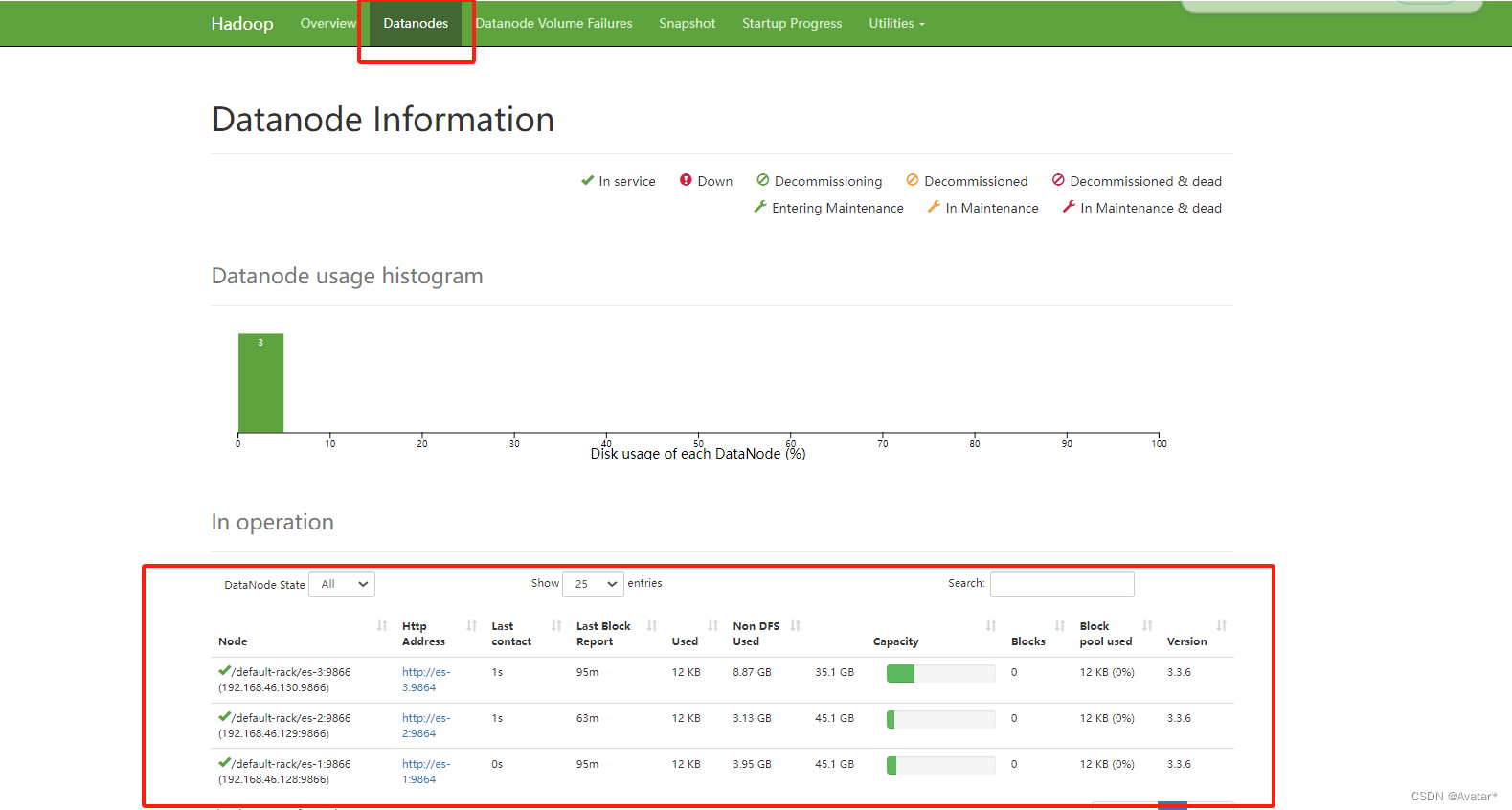
登录web界面:

Powered by Discuz! X3.4