作者:vivo 互联网服务器团队- Hao Chan随着互联网业务的快速发展,基础设施的可用性也越来越受到业界的关注。内存发生故障的故障率高、频次多、影响大,这些对于上层业务而言都是不能接受的。
针对以上问题,我们需要寻找别的解决方案。这时EDAC便出现在我们的视野,它能够完美地解决上面所说的所有问题,并且能够实现内存CE故障的主动发现,提前发现内存问题。
- MCE日志很难直接定位到故障内存槽位。
- 没有直观的CE/UCE错误计数。
- 无法根据内存条上CE/UCE的数量判断内存的健康状况。
那么EDAC是如何控制和报告设备故障的呢?它又是如何将故障定位以及记录到对应的内存条上的呢?
- 【edac_mc_alloc()】:使用结构体mem_ctl_info来描述内存控制器,只有EDAC的核心才能接触到它,通过edac_mc_alloc()这个函数去分配填充结构体的内容。
- 【edac_device_handle_ce()】:标记CE错误。
- 【edac_device_handle_ue()】:标志UCE错误。
- 【edac_mc_handle_error()】:向用户空间报告内存事件,它的参数包括故障点的层次结构以及故障类型,累计的相关UCE/CE错误计数统计。
- 【edac_raw_mc_handle_error()】:向用户空间报告内存事件,但是不做任何事情来发现它的位置,只有当硬件错误来自BIOS时,才会被edac_mc_handle_error()直接调用。
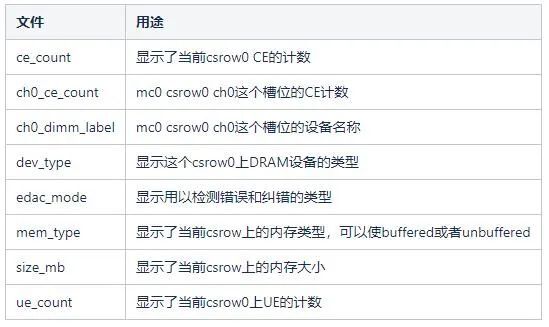
Linux 是通过sysfs文件系统来展示内核设备的层次关系,EDAC则通过它来控制和报告设备故障。EDAC是通过抽象出来的内存控制器模型,将故障定位到对应的内存条上,这主要也是与内存在系统中的排列结构相关。CPU对应的每个MC(memory controller)设备控制着一组DIMM内存模块,这些模块通以片选行(Chip-Select Row,csrowX)和通道(Channel,chX)的方式排布,在系统中可以有多个csrow和多个通道。通过下列路径可以查看相关文件:
① 使用edac-ctl查看SYSFS CONTETS条数是否正确这里我们还遇到一个rpm包的问题:对于厂商的主板的model name前后有多个空格的情况,edac-ctl无法识别到主板的model name,lables.db无法注册成功。最后我们修改了edac-utils包的源代码,重新进行了打包。
② 用dmidecode -t memory查看内存的名称是否一致
这里是通过debugfs向内核APEI结构中的EINJ表注入内存错误来进行测试,debugfs是一种用于内核调试的虚拟文件系统,简单来说就是可以通过debugfs映射内核数据到用户空间,使用户能够修改一些数据进行调试。
- BERT(Boot Error Record Table):主要用来记录在启动过程中出现的错误
- **ERST(Error Record Serialization Table) **:用来永久存储错误的抽象接口,存储各种硬件或平台的相关错误,错误类型包括 Corrected Error(CE),Uncorrected Recoverable Error(UCR),以及 Uncorrected Non-Recoverable Error,或者说Fatal Error。
- EINJ(Error Injection Table):主要作用是用来注入错误并触发错误,是一个用来测试的表
- HEST(Hardware Error Source Table):定义了很多错误源和错误类型。定义这些硬件错误源的目的在于标准化软硬件错误接口的实现。
| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |