ToB企服应用市场:ToB评测及商务社交产业平台
标题:
云盘算导论—搭建Hadoop平台
[打印本页]
作者:
魏晓东
时间:
2024-7-11 16:17
标题:
云盘算导论—搭建Hadoop平台
一、Hadoop平台先容
Hadoop平台是一个由Apache基金会所开辟的分布式系统基础架构,专为大数据处理而设计。以下是关于Hadoop平台的具体先容:
1.1 Hadoop基础架构概述
核心组件
:Hadoop主要由两个核心组件构成,即Hadoop Distributed File System(HDFS)和MapReduce。
HDFS
:负责分布式存储,设计用于在平常硬件上存储超大规模数据集。它具有高容错性,并且提供了对大数据集的高吞吐量访问。
MapReduce
:负责分布式盘算,答应程序员在不了解分布式系统底层细节的情况下,编写处理大规模数据的程序。
1.2 Hadoop的特点
可扩展性
:Hadoop能够轻松地扩展到大量的数据和节点,支持集群规模从几个节点到成千上万个节点的扩展。
容错性
:Hadoop具有强大的容错本领,能够自动检测和处理故障,确保数据的安全性和可靠性。HDFS能检测并自动处理硬件故障,MapReduce也能自动重新分配失败的任务。
高可用性
:Hadoop支持跨多个节点的负载平衡和故障转移,确保应用程序的高可用性。
机动性
:Hadoop支持多种数据格式和编程语言,能够处理各种范例的数据和业务需求。
可定制性
:Hadoop答应用户编写自定义的MapReduce任务,以扩展其功能。
1.3 Hadoop的主要功能
数据存储
:Hadoop提供了分布式文件系统HDFS,用于存储大量数据。HDFS具有高可靠性和高可用性,能够处理大规模数据集。
数据处理
:Hadoop支持MapReduce编程模子,用于处理和分析大数据集。MapReduce是一种分布式盘算框架,能够将大数据集分解为多个小块,并在多个节点上并行处理。
数据集成
:Hadoop支持与其他数据源的集成,如数据库、数据堆栈等,实现数据共享和整合。
数据管理和监控
:Hadoop提供了数据管理和监控功能,包括数据导入、数据导出、数据备份等,确保数据的安全性和可靠性。
1.4 Hadoop的实用场景
Hadoop实用于以下几种场景:
大数据处理
:Hadoop能够处理海量数据,得当用于分布式存储和处理大规模数据集。
数据分析
:Hadoop提供了MapReduce框架,可以用于数据处理和分析,支持复杂的数据处理任务。
日志分析
:Hadoop能够处理大量的日志数据,帮助企业分析用户行为和系统运行情况。
数据挖掘
:Hadoop提供了强大的数据处理和盘算本领,可以用于数据挖掘和呆板学习任务。
实时数据分析
:通过结合Hadoop和实时处理框架(如Spark、Storm等),可以实现实时数据分析和处理。
图像识别和处理
:Hadoop可以用于处理大规模的图像数据,支持图像识别和处理任务。
综上所述,Hadoop是一个功能强大的分布式盘算平台,实用于大数据处理和分析。
二、实验过程
2.1
安装CentOS虚拟机
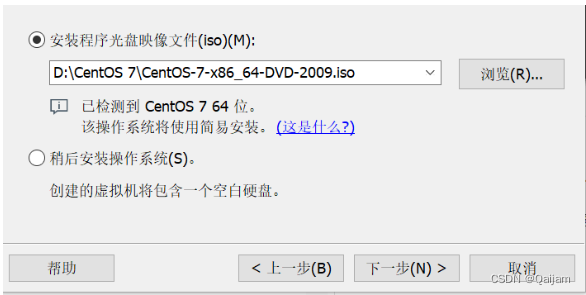
(1)Centos7镜像文件下载完成后,新建一个文件夹,用于存放Centos,把存放路径先复制好,备用。双击运行VMware,点击【创建新的虚拟机】,或选择文件→新建虚拟机,选择【典型】,点击【下一步】,选择【安装程序光盘映像文件】,点击【浏览】选择你所要安装的镜像,完成后选择【下一步】。
(2)命名虚拟机,设置其路径和分配磁盘空间,跳转至安装页面如下:
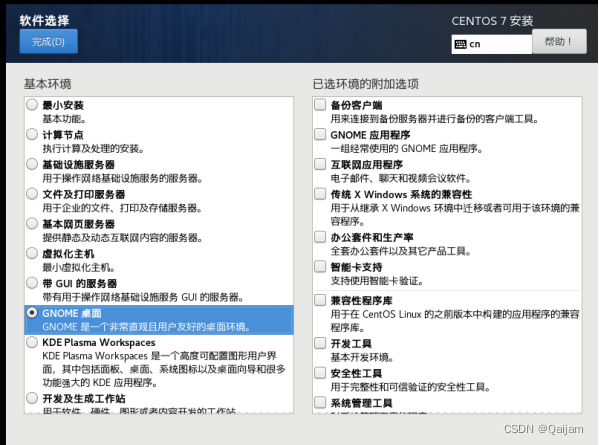
(3)系统停到引导菜单这里,我们选择【Install Centos7】然后回车继续,SOFTWARE SELECTION默认Minimal Install,我们可以选择GNOME Desktop桌面的软件举行安装。
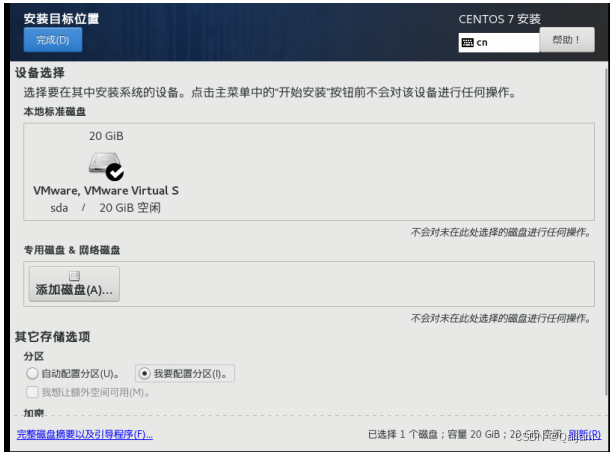
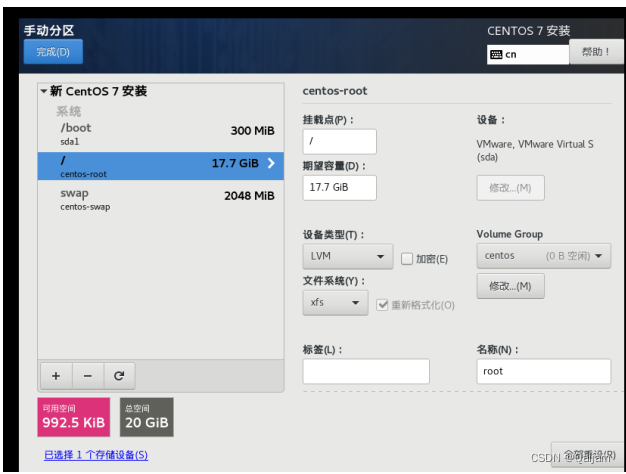
(4)为系统设置磁盘分区。
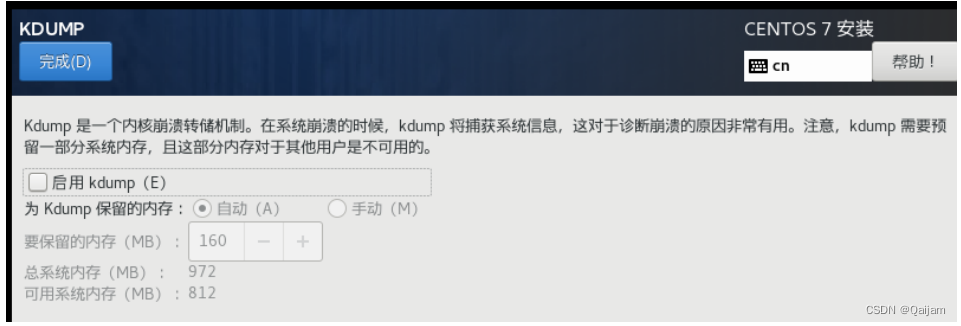
(5)禁用KDUMP。
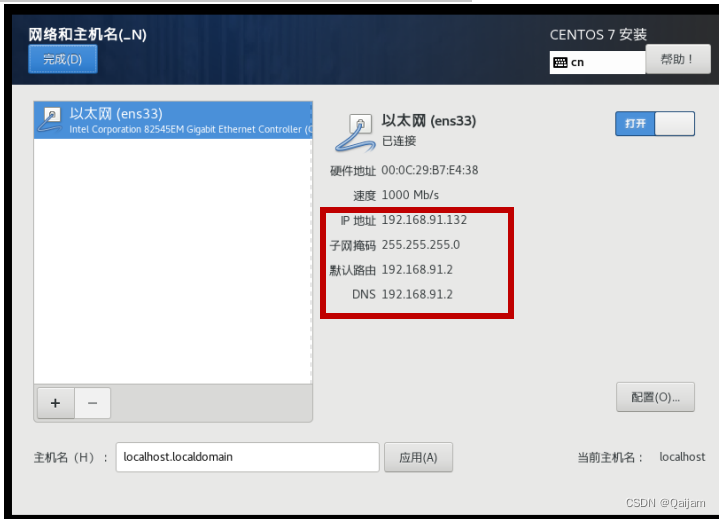
(6)设置网络,开启网络设置,IP地址系统自动分配,IP要记牢,可以在windows的cmd下ping一下这个ip,设置主机名,点击Done。
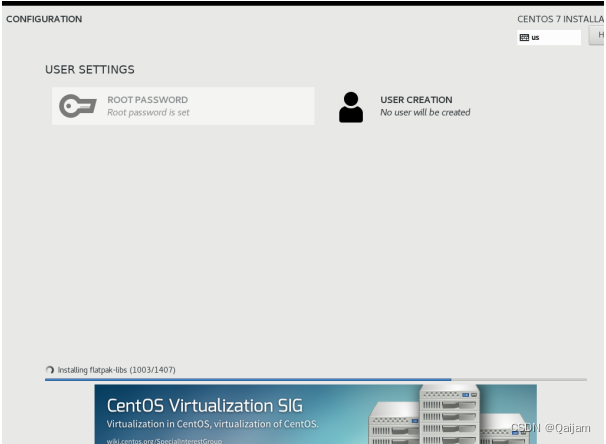
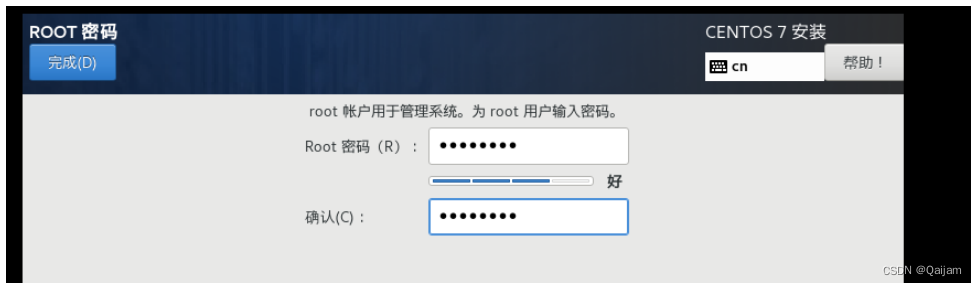
(7)点击Begin Installation开始举行安装,需要点击ROOT PASSWORD的三角感叹号那里,设置下超等管理员的用户名的密码。
2.2 设置网络
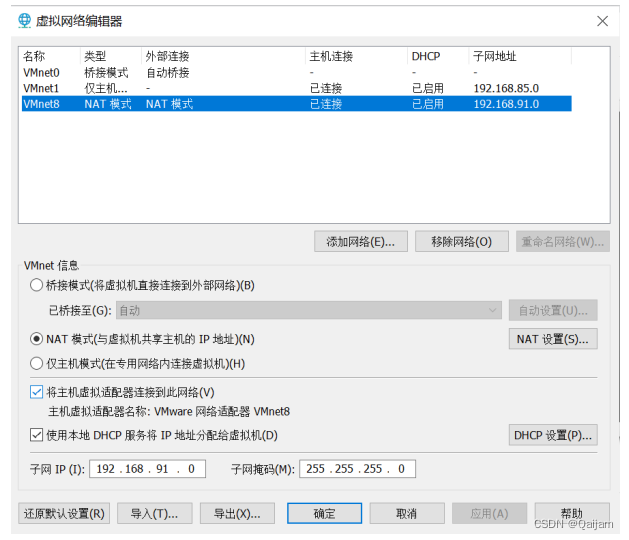
(1)设置虚拟机的网络,点击左上角编辑——虚拟网络编辑器,设置网络基础信息。
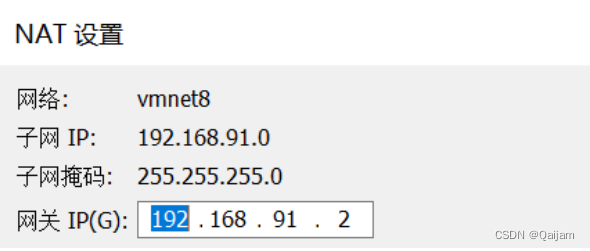
(2)设置网关。
(3)设置本地网络,点击控制面板,进入网络适配器界面,选择 vm8右击,选择属性,修改 ipv4。需要和虚拟机中设置的网络信息保持一致。
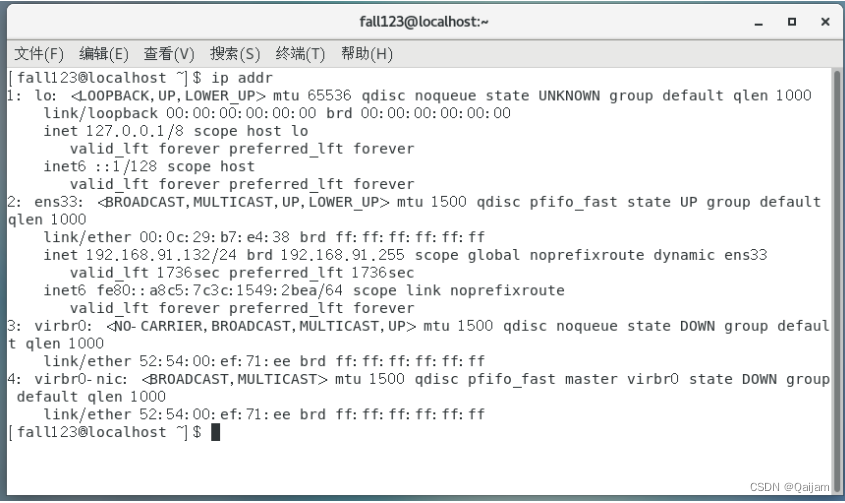
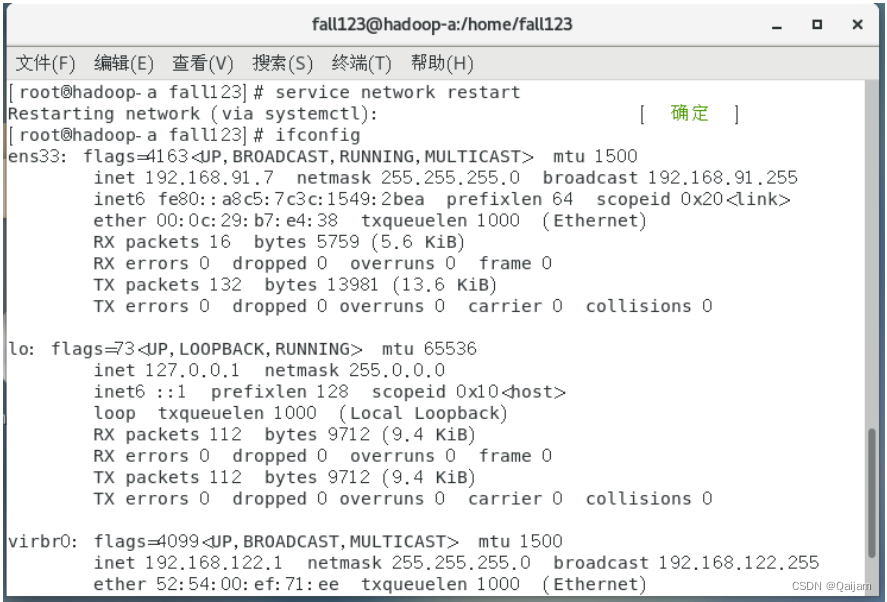
(4)新安装好的系统重新启动后,第一件事情,配置网络。首先,查看当前网络情况,使用:ip addr。
默认网络配置如下:
图中第1项 lo:是本地环回接口的意思;ip只能是“127.0.0.1”。
上图中ens33:本地未设置的网络装备名,默认情况下,该网络还未被设定ip地址和启用。它对应着一个配置文件ifcfg-ens33.此文件在/etc/sysconfig/network-scripts/ifcfg-ens33,编辑这个文件即可配置ip。
(5)编辑的网络配置文件:
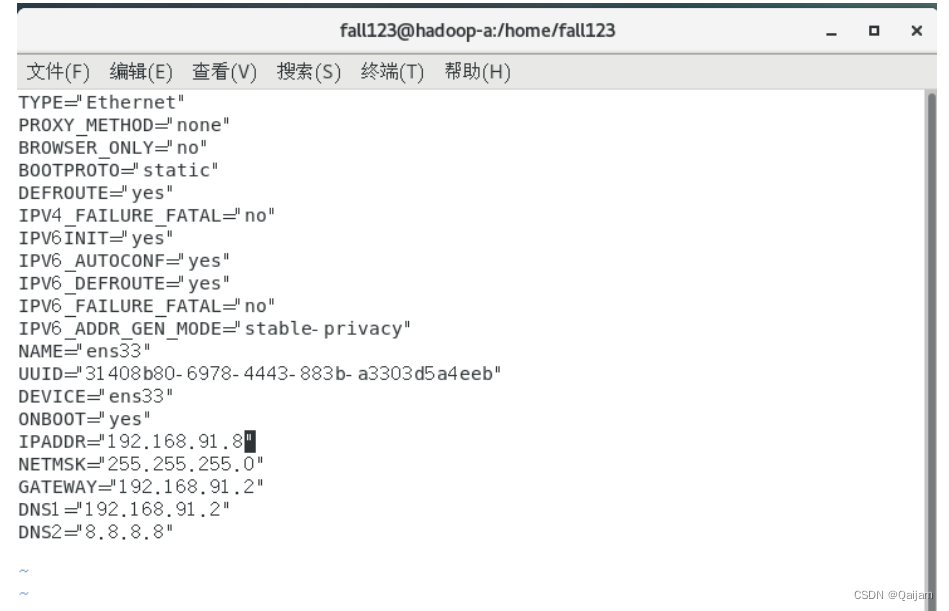
vi /etc/sysconfig/network-scripts/ifcfg-ens33
复制代码
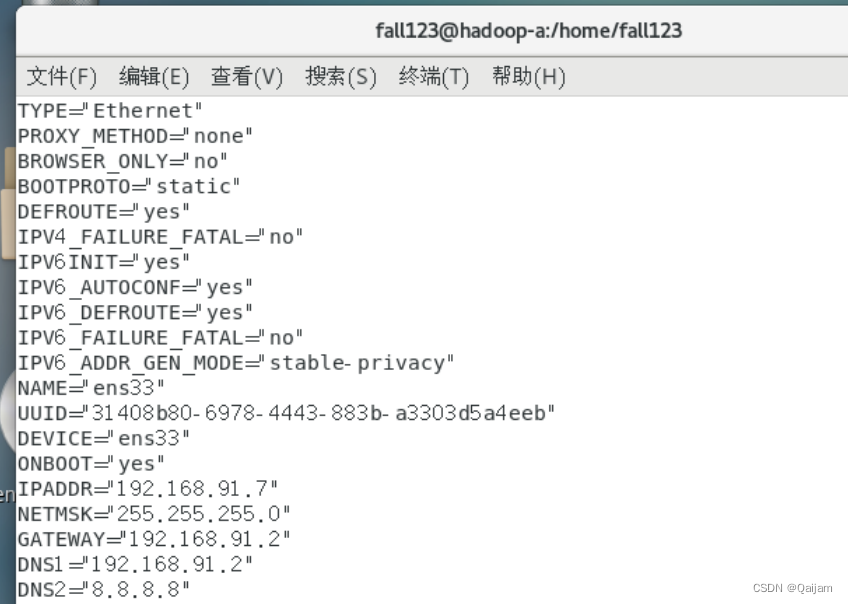
修改内容如下:
BOOTPROTO=static #静态ip;不用复制直接改
ONBOOT=yes #系统启动时,自动启用网络。不用复制直接改
IPADDR=”192.168.91.7”
NETMSK=”255.255.255.0”
GATEWAY=”192.168.91.2”
DNS1=”192.168.91.2”
DNS2=”8.8.8.8”
复制代码
本领:利用VMware编辑菜单的粘贴,可以复制笔墨。编辑好上面的内容,然后复制,可以很快速准确的完成ip地址的设定,
注意不能有中文
。
(6)重启网络服务:
service network restart
复制代码
重新启动网络后,配置才会生效,此时也可以通过ping命令测试下网络的连通情况。
网络配置生效后,推荐在本地使用连接工具,连接虚拟机举行后续配置,本文使用MobaXterm举行远程连接。
2.3 配置主机Hadoop-A
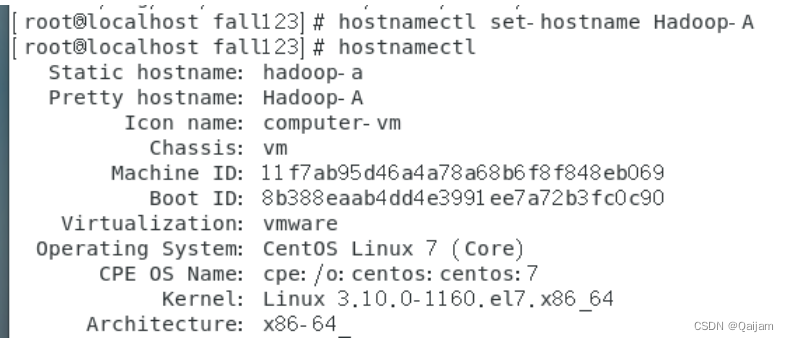
(1)修改主机名,将本机主机名修改为Hadoop-A
hostnamectl set-hostname Hadoop-A #修改主机名
hostnamectl #查看系统信息
复制代码
注意,修改后,无需重启系统,重新启动连接客户端即可。
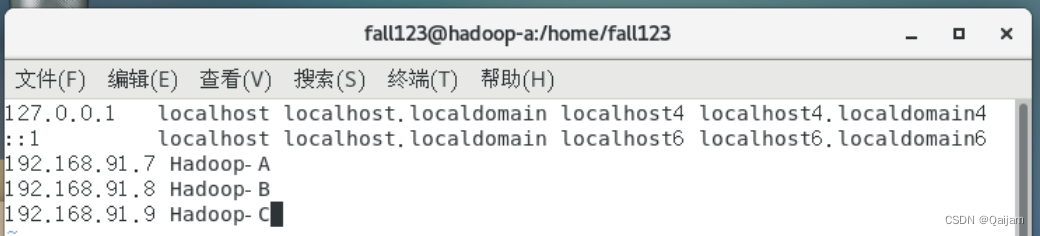
(2)修改主机名,重启连接后,还需要修改主机名与ip地址的映射,否则启动hadoop时报错。通过修改/etc/hosts文件,添加如下内容,ip地址与主机名的映射,可以参看前面的集群规划。
修改后如下图所示:
hosts文件内容修改完成后,可以通过如下命令,测试是否乐成:
ping Hadoop-A
复制代码
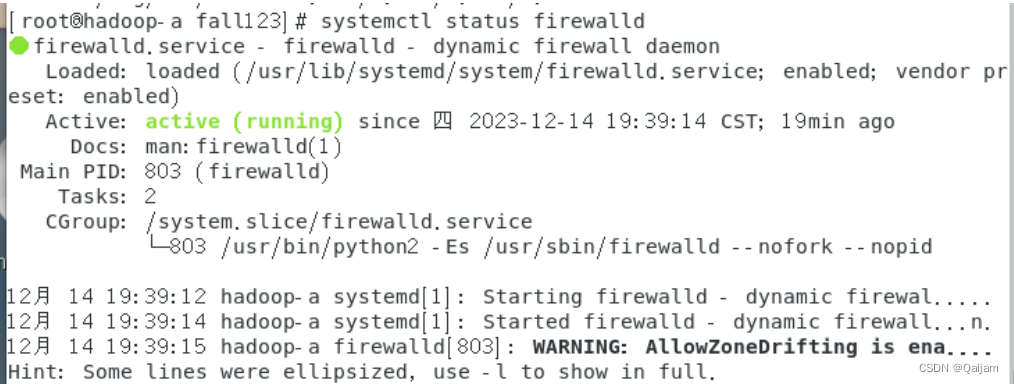
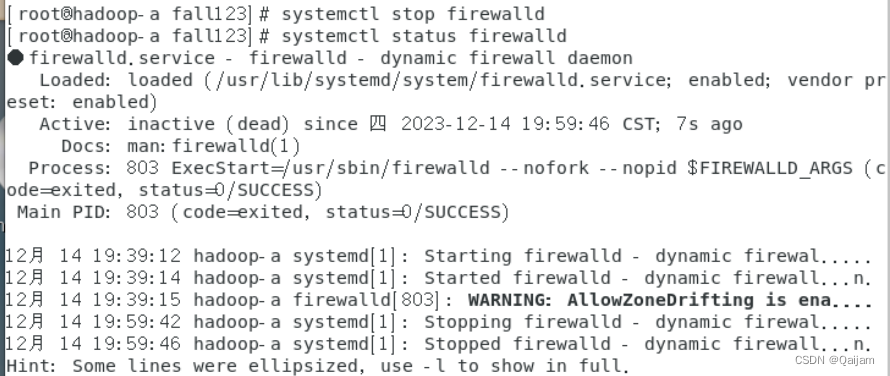
2.4 关闭防火墙
如果不关闭防火墙,那么,需要依次放行,Hadoop运行过程中的网络服务端口,比力麻烦。
命令如下:
systemctl status firewalld #查看防火墙状态
复制代码
systemctl stop firewalld #停止防火墙
复制代码
systemctl disable firewalld #禁用防火墙
复制代码
2.5 安装相关软件
(1)安装下载库
yum install -y epel-release
复制代码
(2)安装JDK
根据官方文档可知,JDK具有较好的兼容性,所以,
本文选用JDK8版本
安装。
注意!先查询自己JDK版本,若为8则跳过本步骤!!
否则,先卸载原生 JDK:
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
复制代码
到Oracle官网下载JDK8安装包,上传至虚拟机的/root/soft目录,并解压。涉及到的主要命令如下:
mkdir soft #创建目录
cd soft #进入目录
复制代码
上传下载好的JDK8安装包后,实验:
tar -zxvf jdk-8u392-linux-x64.tar.gz #解压JDK
复制代码
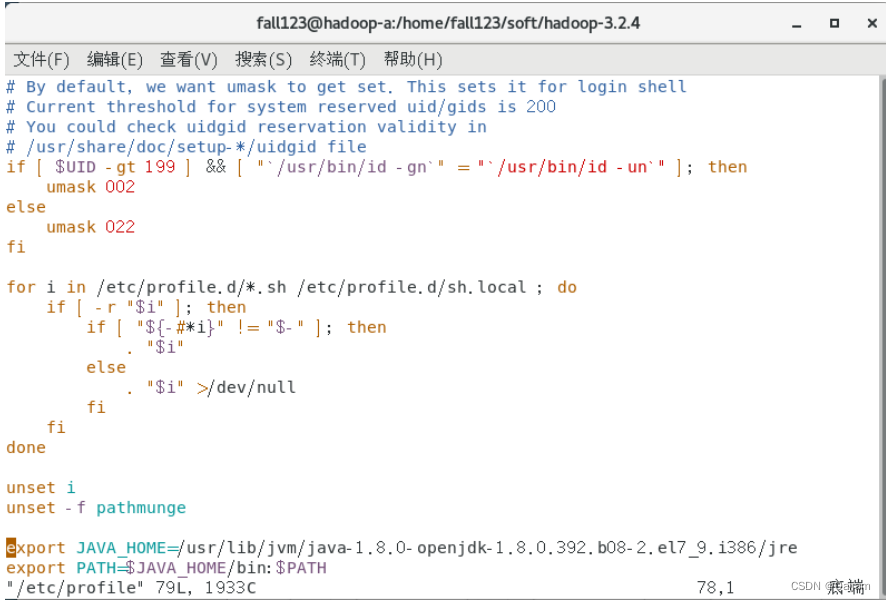
编辑profile文件,配置环境变量:
vim /etc/profile
复制代码
添加内容:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.392.b08-2.el7_9.i386/jre
export PATH=$JAVA_HOME/bin:$PATH
复制代码
末了内容如下图:
(3)环境变量修改后,革新环境变量,使配置生效:
source /etc/profile #更新环境变量
java -version #查看修改后的Java版本
复制代码
2.6 配置Hadoop
(1)到官网下载所需要的Hadoop 版本,本文选用的是hadoop3.2.4,上传至虚拟机后,对其解压:
tar -zxvf hadoop-3.2.4.tar.gz
复制代码
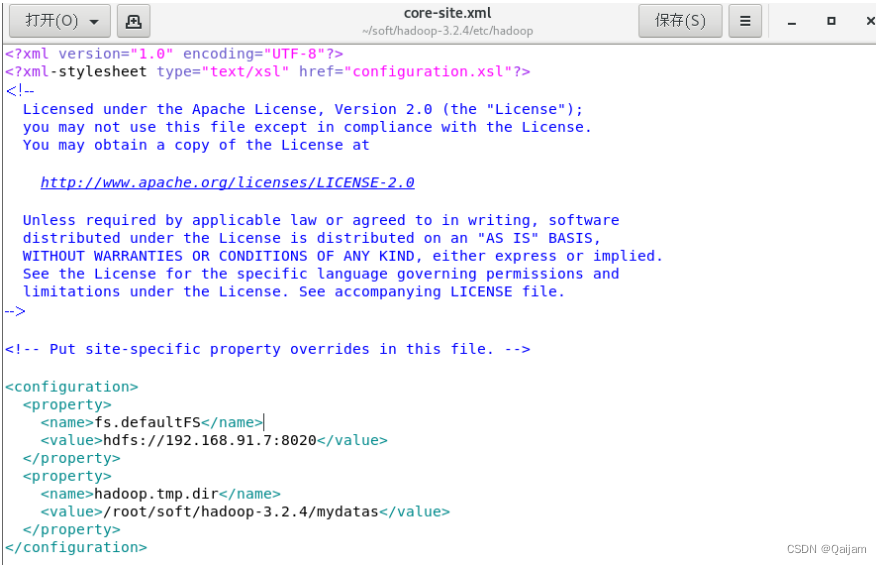
(2)配置core-site.xml(核心站点)
此文件位于hadoop安装目录下,etc/hadoop/文件夹。
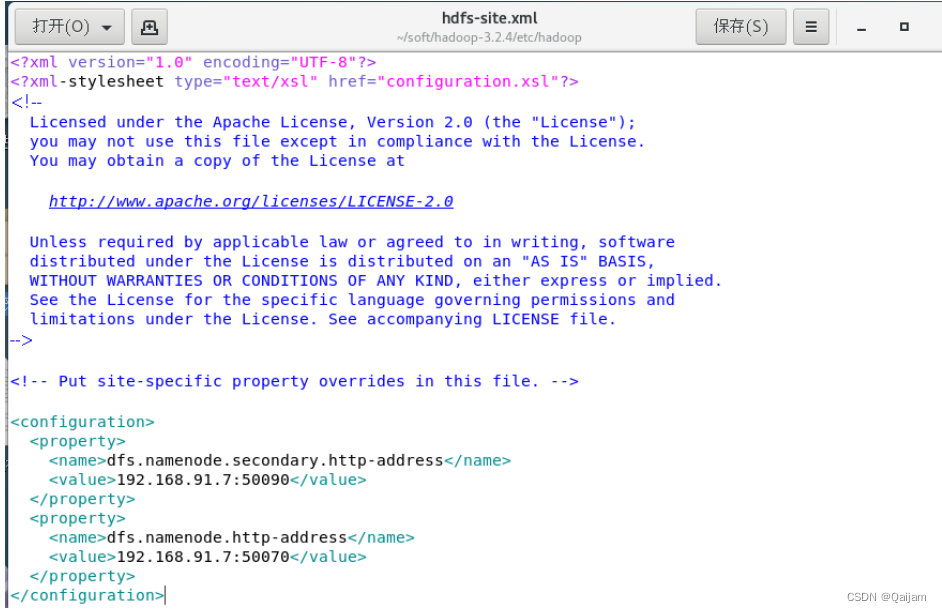
(3)修改hdfs-site.xml,主要设定namenode(主节点)和secondarynamenode(辅助节点)的站点地址。
(4)修改hadoop-env.sh
此文件位于hadoop安装目录下,etc/hadoop/文件夹,在第54行左右找到export JAVA_HOME,根据JDK的安装路径,配置此部分。
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.392.b08-2.el7_9.i386/jre
复制代码
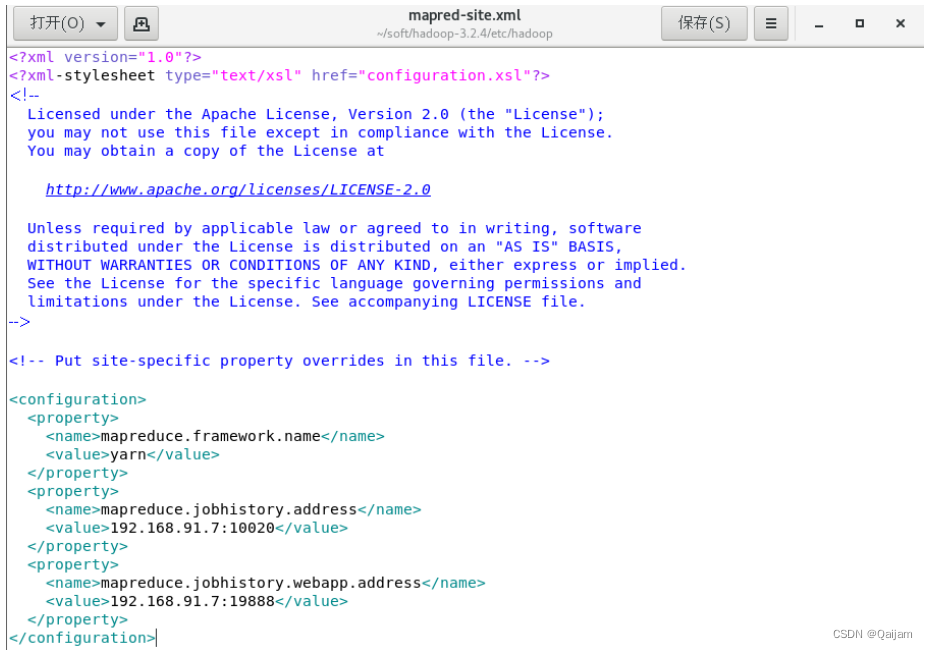
(5)修改mapred-site.xml
此文件主要配置了,以下三方面内容:设定分布式资源管理方案为yarn,默认是local;设置历史任务服务器地址;设置历史服务器web应用地址。
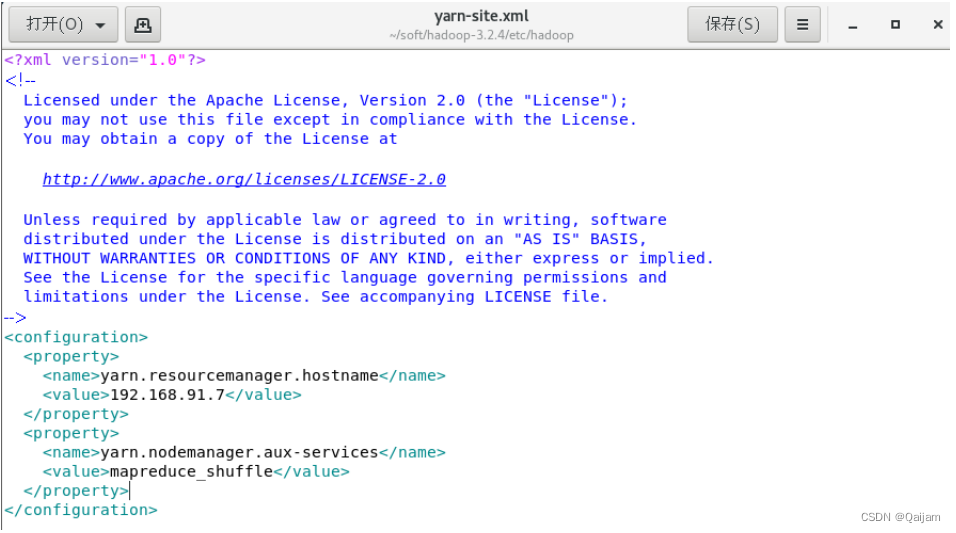
(6)修改yarn-site.xml
此文件主要配置了,以下两方面内容:设置ResourceManager主机名;NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序。
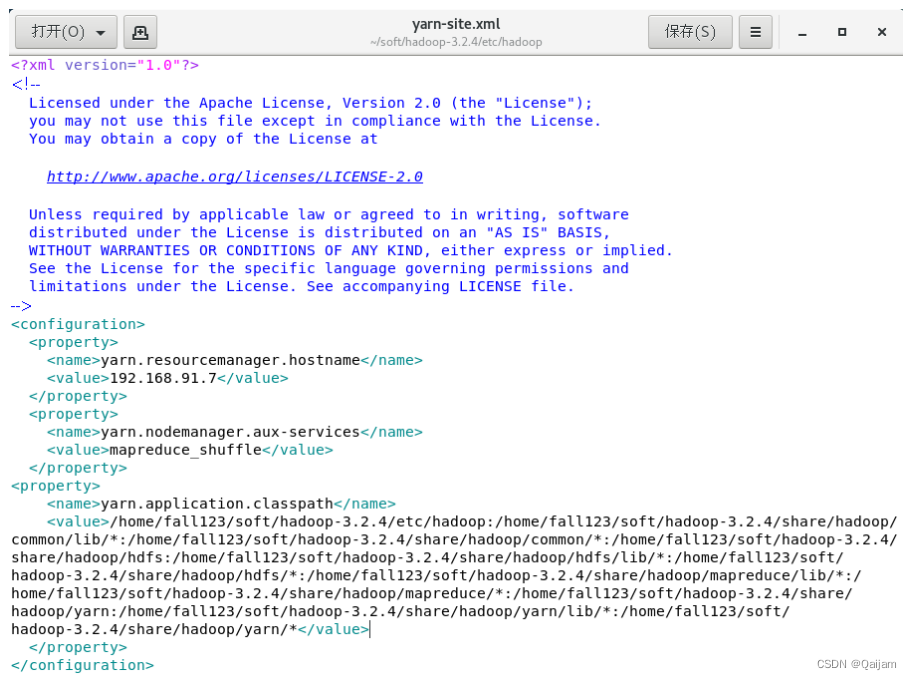
(7)Hadoop3.1.3以上版本安装后,实验MapReduce操作出现包辩论错误:找不到或无法加载主类org.apache.hadoop.mapreduce.v2.app.MRAppMaster。
办理办法:实验如下命令,返回hadoop的classpath值,并把这些值复制了:
bin/hadoop classpath
复制代码
编辑yarn-site.xml,添加yarn.application.classpath属性,值为上面命令的值,如下图所示:
(8)配置etc/hadoop/workers
192.168.91.7
192.168.91.8
192.168.91.9
复制代码
配置从节点列表,此文件中列出每个从节点的hostname 或ip。
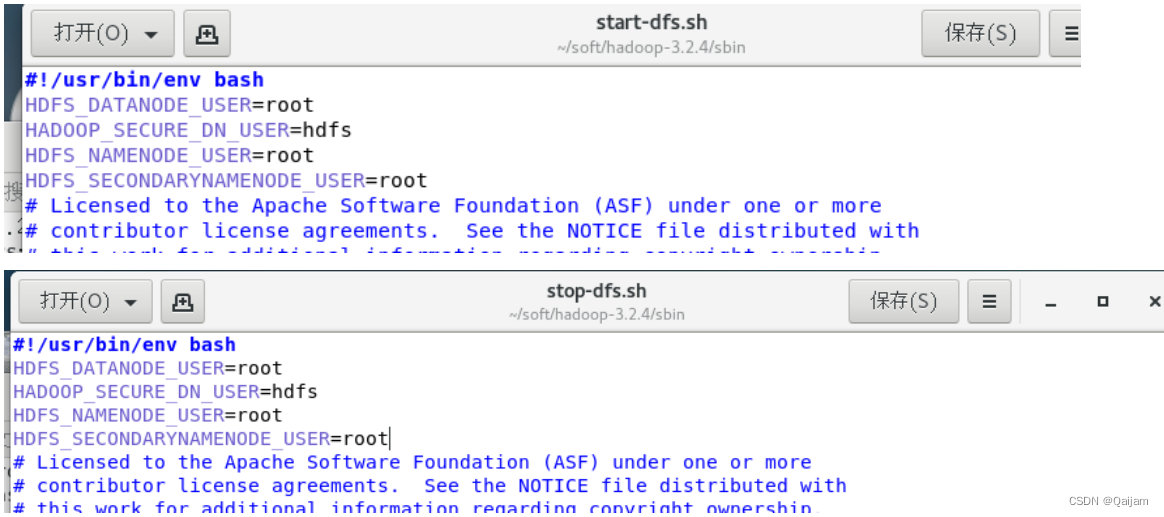
(9)定义hdfs和yarn用户
在/hadoop/sbin路径下: 将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数:
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
复制代码
(10)配置hadoop的环境变量
使用 vi /etc/profile或连接工具的文本编辑器,在profile文件中添加如下内容:
export HADOOP_HOME=/root/soft/hadoop-3.2.4
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
复制代码
然后,更新并测试:
source /etc/profile #更新环境变量文件
hadoop #测试环境变量配置是否成功
复制代码
2.7 复制并配置另外两个节点的虚拟机
(1)关闭虚拟机
shutdown -h now #关闭虚拟机
复制代码
完全关闭后,复制虚拟机硬盘,然后文件夹文本改名。
(2)复制后修改虚拟机的名字为Hadoop-B,然后启动。
启动时选择,我已经复制该虚拟机:
(3)修改IP地址为:192.168.91.8
vi /etc/sysconfig/network-scripts/ifcfg-ens33
复制代码
(4)重启网络服务:
service network restart
复制代码
修改主机名:
hostnamectl set-hostname Hadoop-B
复制代码
(5)配置Hadoop-C,按照以下步骤配置Hadoop-C:
双击node3文件夹里的虚拟机;
修改虚拟机名为Hadoop-C;
启动虚拟机,选择【我已经复制该虚拟机】
修改IP地址为:192.168.91.9
(6)修改主机名为Hadoop-C
2.8 启动集群
要启动 Hadoop 集群,需要启动 HDFS 和 YARN 两个模块。 注意: 首次启动 HDFS 时,必须对其举行格式化操作。 第一台呆板实验以下命令,如果设置了环境变量,不需要加目录。
hdfs namenode -format #只执行一次,重复执行了,要选N或删除临时目录
start-dfs.sh #启动HDFS服务
start-yarn.sh #启动YARN服务
mr-jobhistory-daemon.sh start historyserver #启动历史服务
jps #查看已启动的服务
复制代码
注意,如果重复格式化了,要选N,如果选了Y,有可能出现如下错误:
Re-format filesystem in Storage Directory /tmp/hadoop-root/dfs/name ? (Y or N)
办理办法:
可以删除core.site.xml的hadoop.tmp.dir所定义的目录里的内容。
三、总结
本次实验中,我们乐成搭建了Hadoop环境,并对CentOS虚拟机举行了相关配置。这一过程不但让我们掌握了Hadoop的安装步骤,还深化了对其功能和应用的熟悉。我们了解到,Hadoop能够简化分布式程序的开辟,让开辟者在不关注底层细节的情况下,也能利用集群资源举行高效的数据处理和存储。此外,Hadoop在处理大规模网页数据存储和索引盘算方面也显示出其强大的本领。总的来说,这次实验让我们对Hadoop的强大功能有了更直观的体验,为我们日后在大数据处理领域的学习和实践打下了坚固的基础。
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/)
Powered by Discuz! X3.4