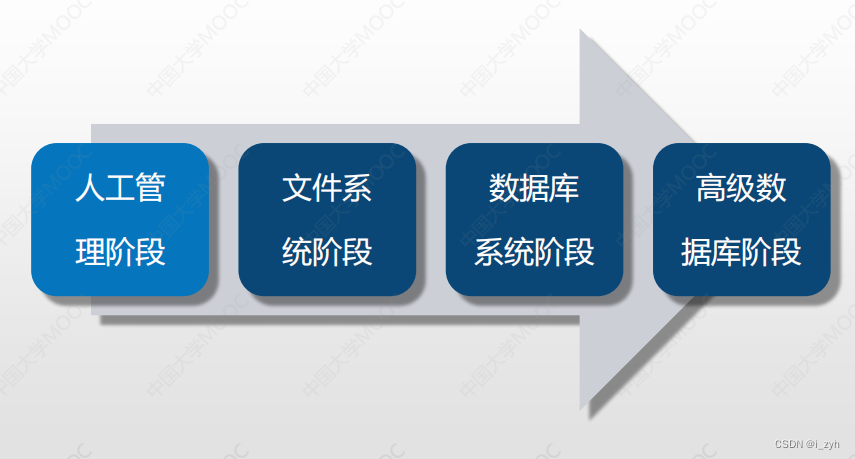
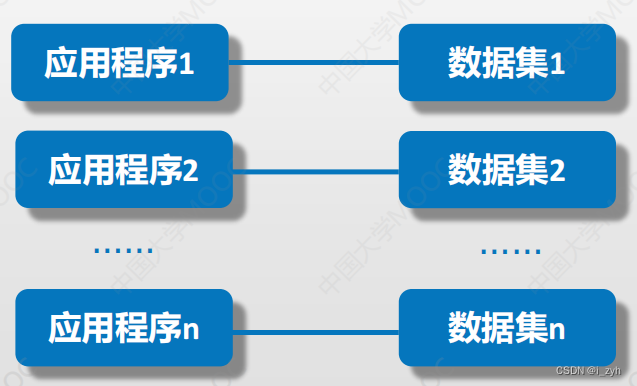
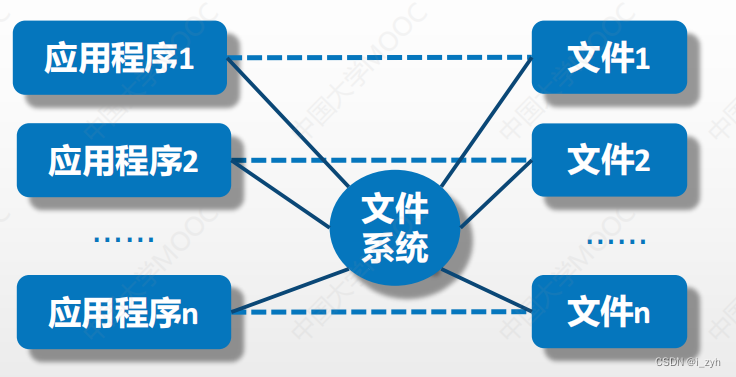
| 层次数据模型 | 第一代数据库系统 |
| 网状数据模型 | |
| 关系数据模型(二维表) | 第二代数据库系统 |
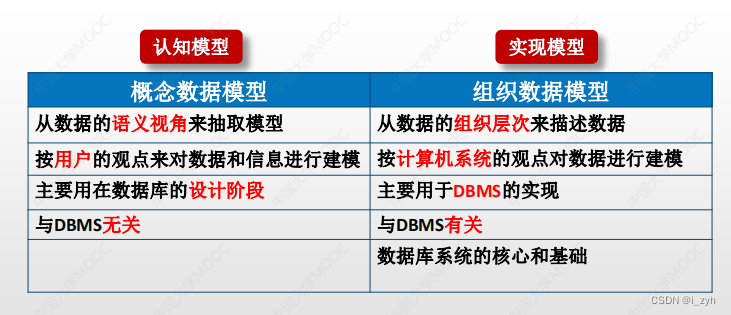
| 能比较真实地模拟现实世界 | 概念数据模型(认知模型) |
| 轻易被人们理解 | |
| 便于在计算机上实现 | 构造数据模型(实现模型) |
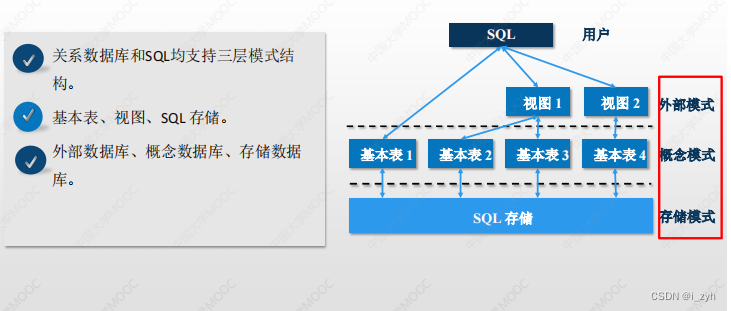
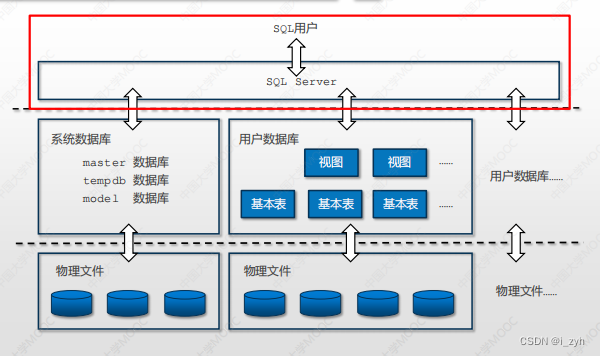
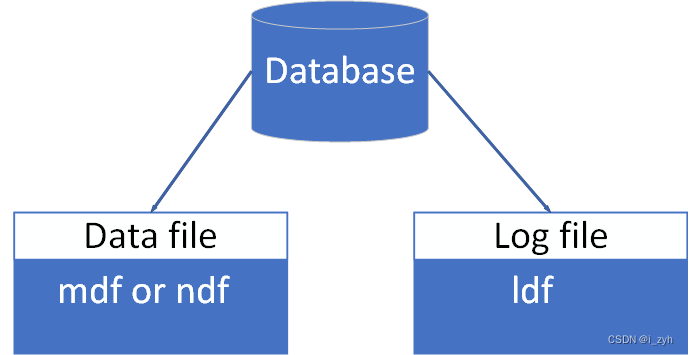
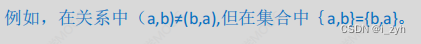
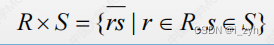
| SELECT | 选择运算 | 行筛选 | |
| PROJECT | 投影运算 | 列筛选 | |
 | JOIN | 连接运算(选择某些行形成新关系) | 自然连接(撤除重复) |
| ÷ | DIVISION | 除运算 |  |











| 1 | 令 |
| 2 | |
| 3 | |
| 4 | 则F中左部为{A,B,C,D}的任意子集的函数依靠有:AB→C,B→D,C→E,AC→B |
| 5 | |
| 6 | 因为 |



| 1 | F中任一函数依靠的右部都仅含有一个属性; | √ |
| 2 | 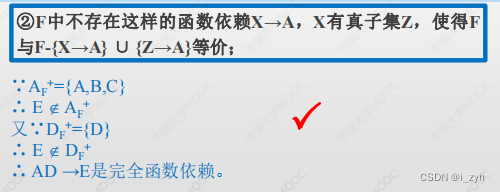 只用找左部个数大于1的就行 | √ |
| 3 |  | √ |
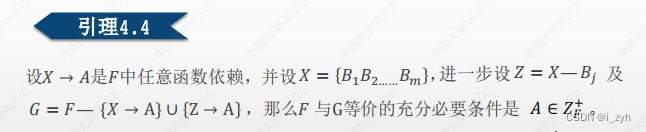


| 1 | 因为右部都是单一属性,以是不须要用分解规则化简; |
| 2 | 化简左侧使得每一个函数依靠的左部没有多余属性 等价变换后的函数依靠集为:{B→E,DE→B,B→C,C→E,E→A} |
| 3 | 令G=F-{B→E}={DE→B,B→C,C→E,E→A},则 |
| 4 | 令G=F-{DE→B}={B→C,C→E,E→A},则 |
| 5 | 令G=F-{B→C}={DE→B,C→E,E→A},则 |
| 6 | 同样,检验C→E,E→A都不是多余函数依靠,不能去除。 |








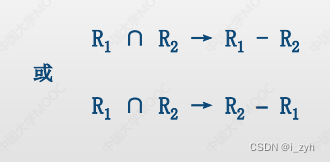

| 显然不满足函数依靠,都是Φ,无法推出F; ∵ R1∩R2=Φ ∴ 及不存在R1∩R2→R1-R2,也不存在R1 ∩ R2 → R2 – R1 ∴ ρ1不满足无损连接 |
| ∵ R1∩R2={职工号},R1-R2={仓库号} 又 ∵ 存在公共号→仓库号 ∴ 存在R1∩R2→R1-R2 ∴ 满足无损链连接; 由ρ2无法推导出仓库号→都会 ∴ ρ2不满足保持函数依靠 |
| ∵ R1∩R2={仓库号},R2-R1={都会} 又∵ 存在仓库号→都会 ∴ 存在R1∩R2→R2-R1 ∴ 满足无损连接; 由ρ3可以推导出职工号→仓库号,仓库号→都会 ∴ρ3还满足保持函数依靠。 |
| ∵ R1∩R2={B},R1-R2={A,C},R2-R1={D} 又∵ 存在B→D ∴ 存在R1∩R2→R2-R1 ∴ 满足无损连接; 由于ρ中,A、D、C三个并没有放在一个函数依靠中,因此AD→C丢失了 ∴ ρ不满足保持函数依靠 |
| ∵ R1∩R2=Φ,R1-R2={A,B},R2-R1={C,D} ∴ Φ 无法决定R1-R2或R2-R1 ∴ 不满足无损链接; 满足保持函数依靠。 |



| 0 | 先求候选关键字: 因为所有函数的依靠的右部都没有 AB,以是首先求 |
| 1 |  计算得到F={B→C} |
| 2 | 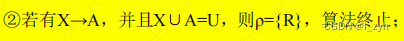 不绝止 |
| 3 |  R0({A},Φ),R1({B,C},{B→C}) |
| 4 |  不存在分组标题 |
| 5 |  ρ={R0 ({A},Φ),R1 ({B,C},{B→C}),U={B,C} |
| 6 |  X = {A,B},Rx({A,B},Φ) τ=ρ∪Rx (X,Fx ) ={R0 ({A},Φ),R1 ({B,C},{B→C}),Rx ({A,B},Φ) |
| 7 |  U0 |
| 8 |  |
| 0 | 关键字X={C,S} |
| 1 |  F={C→T,CS→G,S→N} |
| 2 |  不绝止 |
| 3 |  无R0 |
| 4 |  R1=({C,T},{C→T)} R2=({C,S,G},{CS→G}) R3=({S,N},{S→N}) |
| 5 | ρ=(R1,R2,R3) ={({C,T}, {C→T} ) , ({C,S,G}, {CS→G}) , ({S,N}, {S→N})} |
| 6 |  Rx({C,S},{Φ}) τ=ρ∪({C,S} ,{Φ}) ={({C,S} , Φ), ({C,T}, {C→T}) , ({C,S,G}, {CS→G}) , ({S,N}, {S→N})} |
| 7 |  X 即τ={({C,T}, {C→T}) , ({C,S,G}, {CS→G}) , ({S,N}, {S→N})} |
| 8 |  最终的τ就是分解效果 |












| %(百分号) | 匹配0或多个字符 |
| _(下划线) | 匹配1个字符 |
| [] | 匹配括号中的字符,如[a-f]=[abcdef] |
| [^] | 不匹配括号中的字符 |



























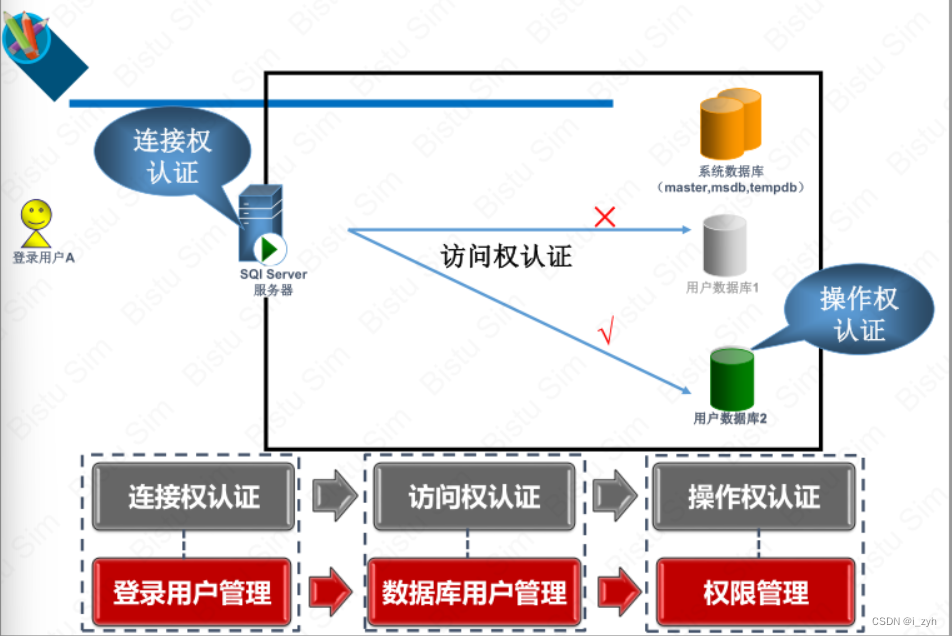
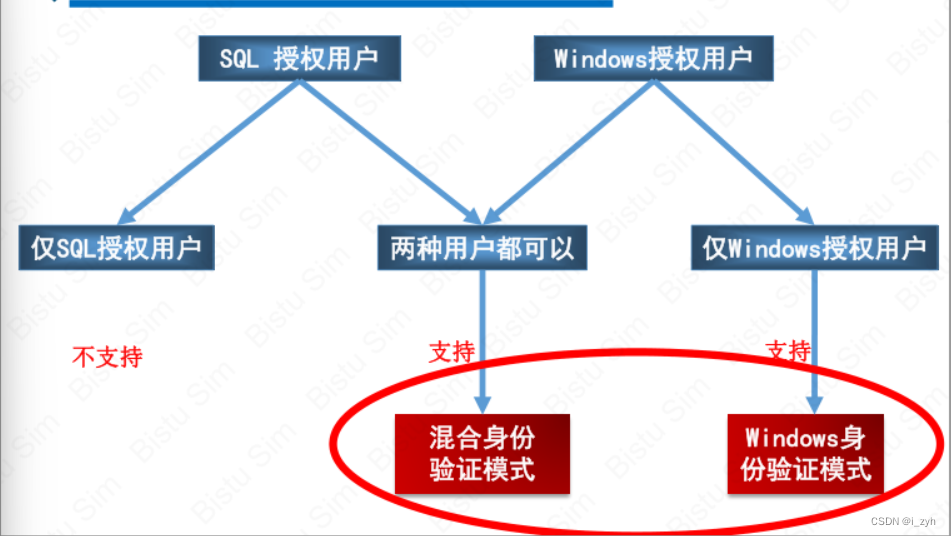
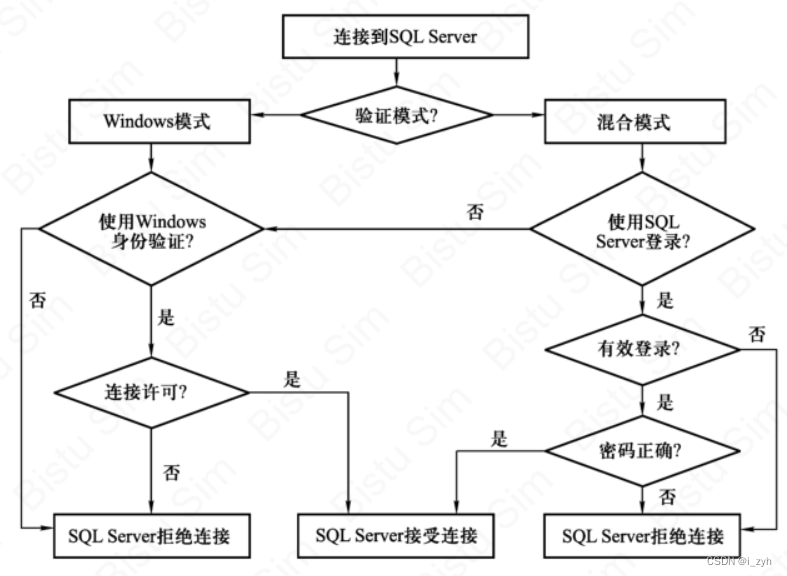





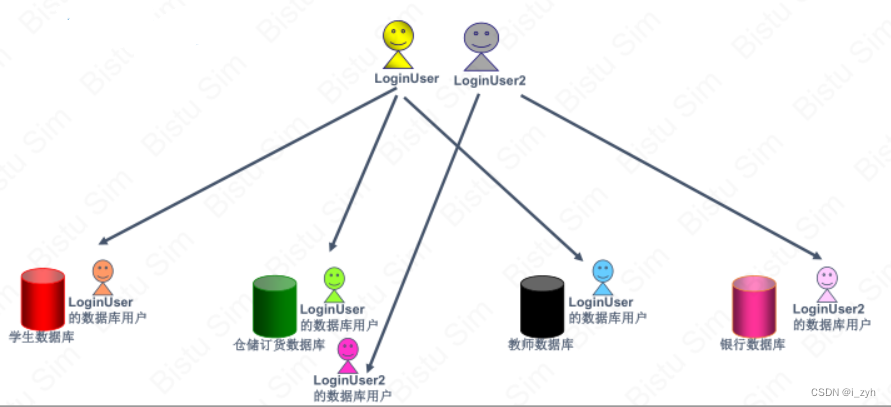
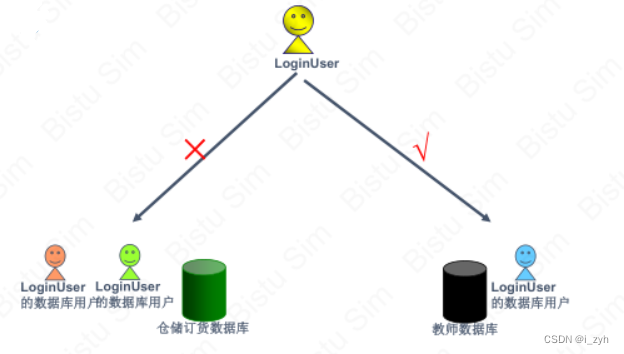

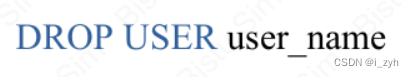
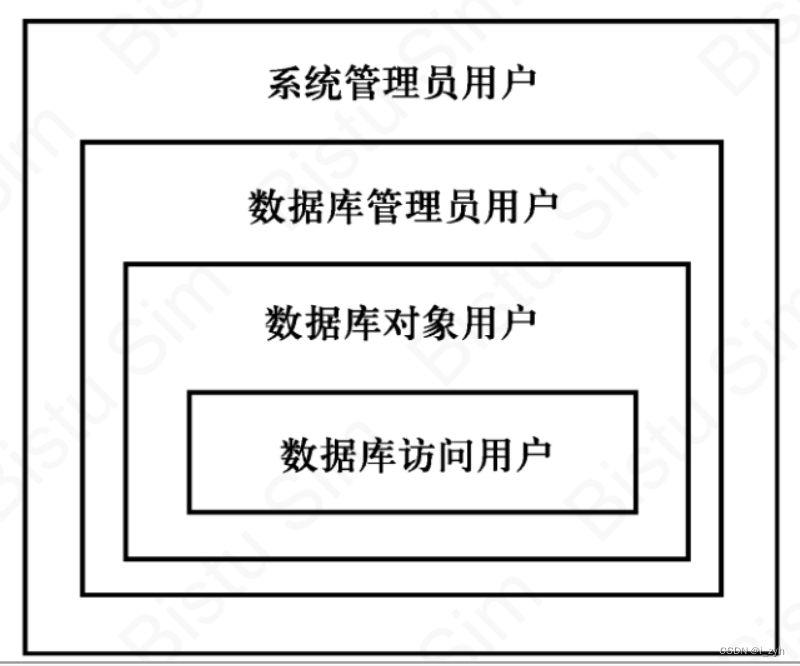





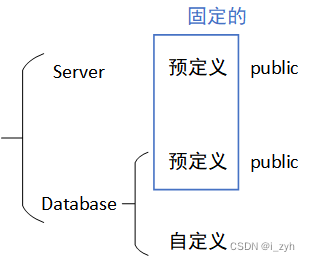














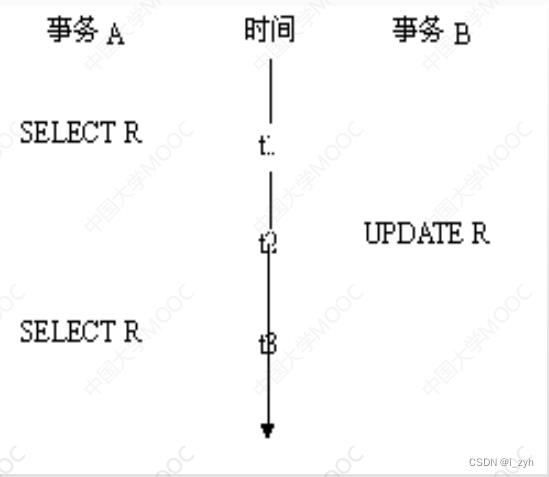
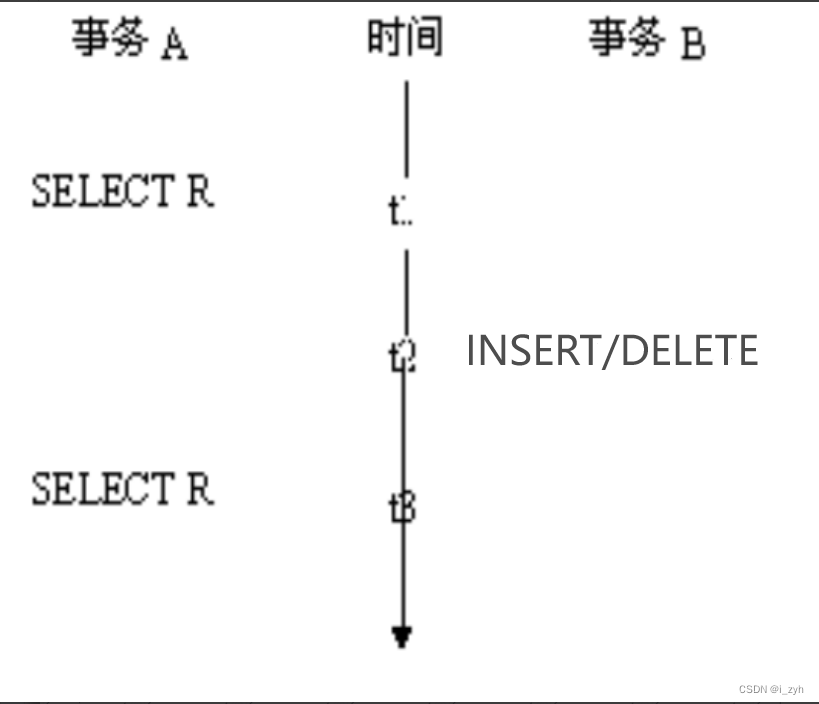
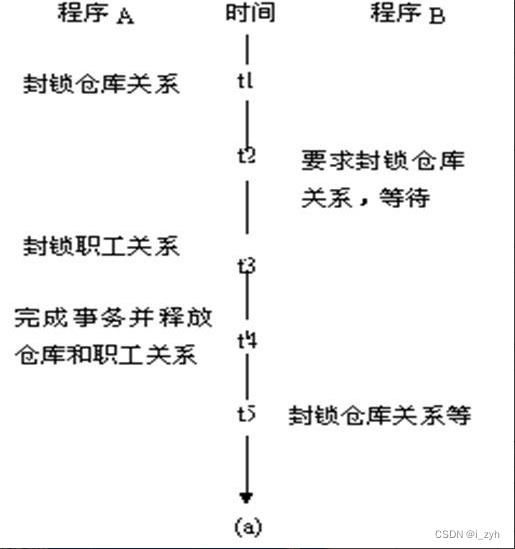
| TABLOCK | 对表共享封锁,读完立刻释放 | 可以避免脏读,但不具有可重复读 |
| HOLDLOCK | 与TABLOCK一起用,将共享锁持续到事务结束 | 包管可重复读 |
| NOLOCK | 不举行封锁,仅应用于SELECT | 大概会读取未提交的数据,导致脏读 |
| TABLOCKX | 实施独占封锁 | |
| UPDLOCK | 实施更新封锁 | 可以对其他记录实施共享封锁,但是不允许对表实施共享封锁和独占封锁 |
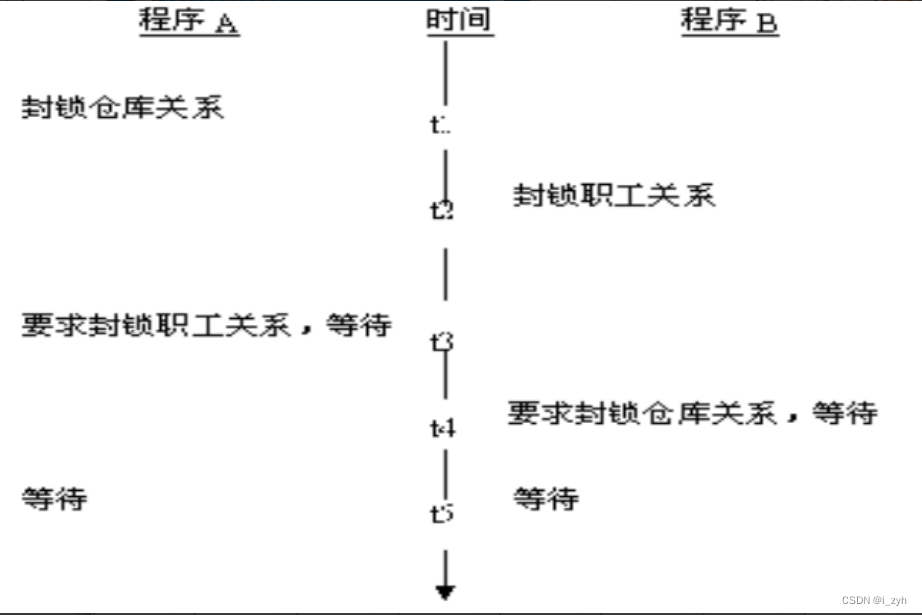
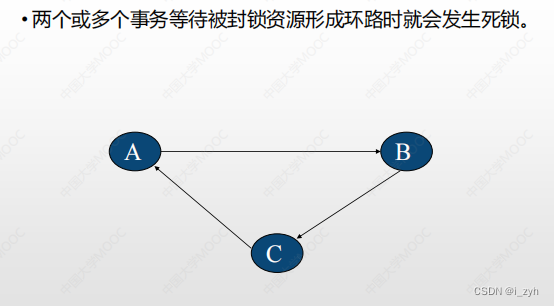



| 隔离级别 | 封锁 | 脏读 | 不可重复读 | 幻象 | 丢失更新 |
| 未提交读(READ UNCOMMITTED) | NOLOCK | 是 | 是 | 是 | 是 |
| 提交读(READ COMMITTED) | TABLOCK | 否 | 是 | 是 | 是 |
| 可重复读(REPEATABLE READ) | TABLOCK+HOLDLOCK | 否 | 否 | 否 | 是 |
| 可串行化(SERIALIZABLE) | TABLOCKX 或UPDLOCK | 否 | 否 | 否 | 否 |




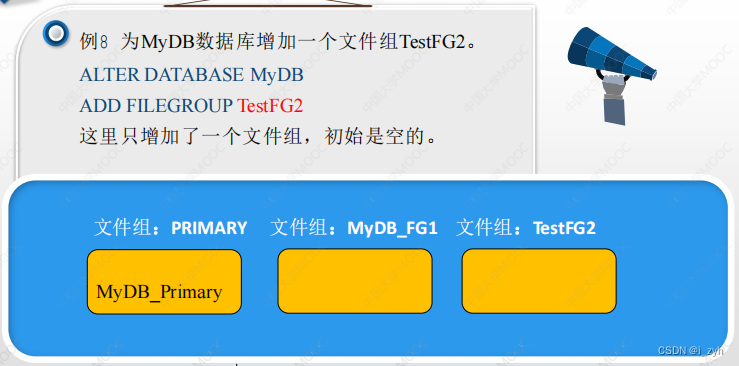
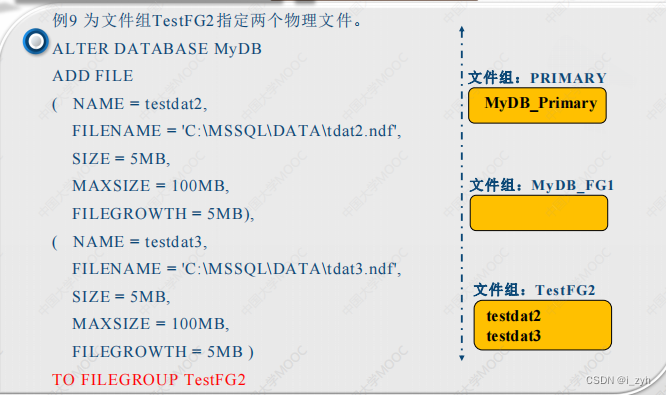
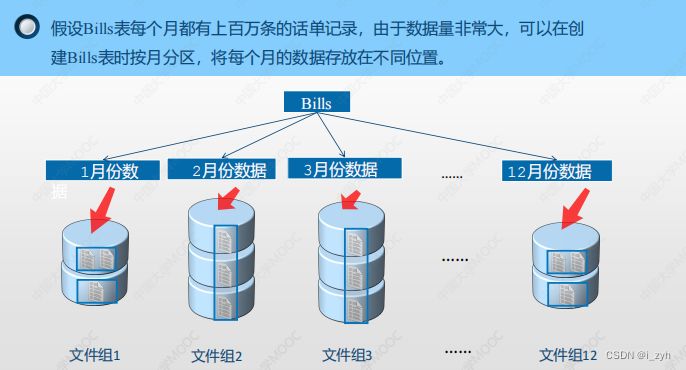







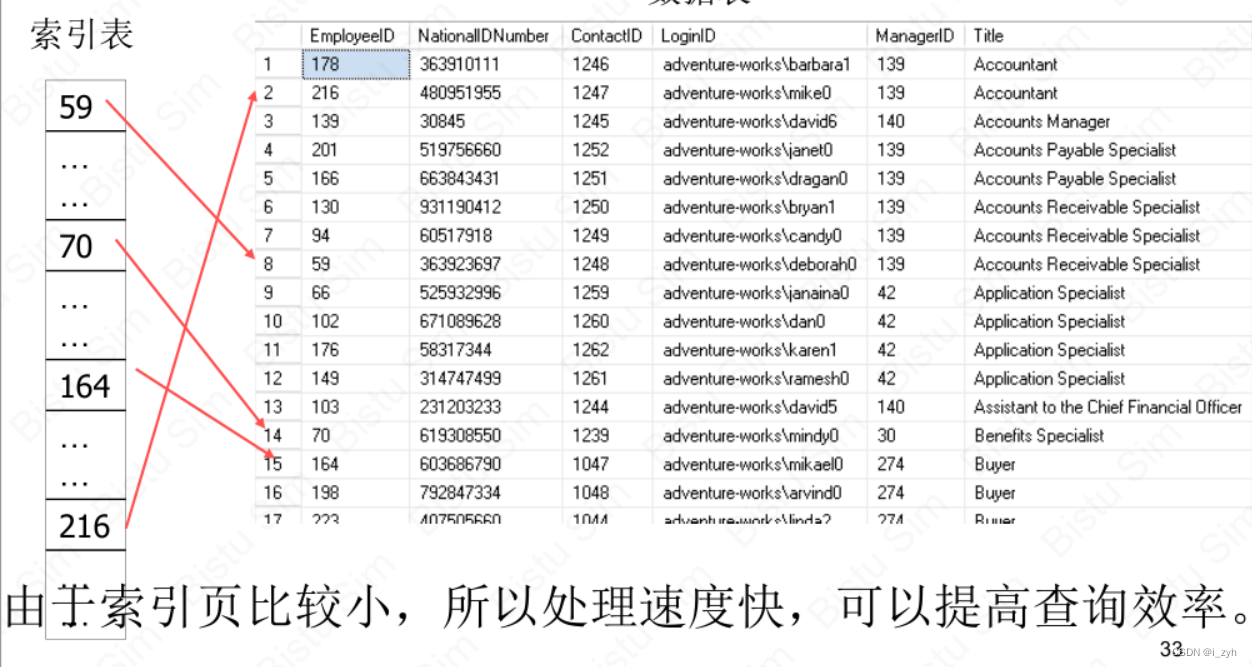









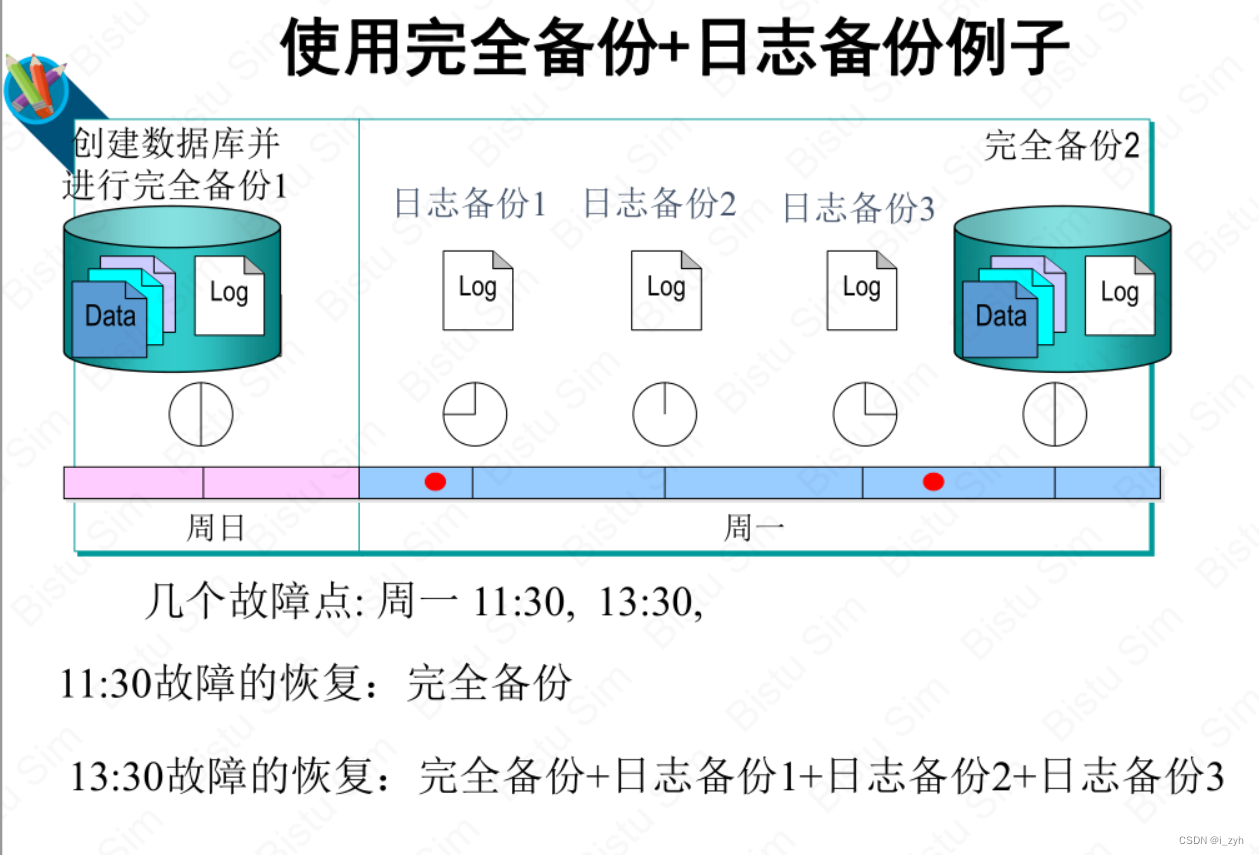





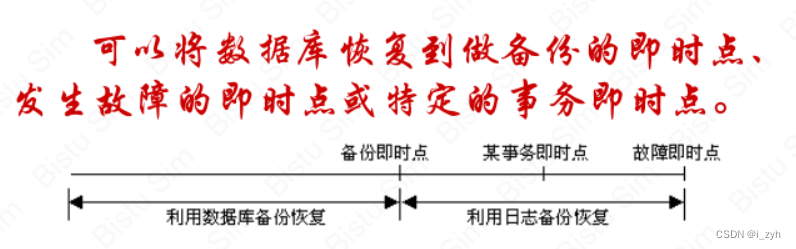






| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |