ToB企服应用市场:ToB评测及商务社交产业平台
标题:
云计算-Spark部分复习(自用)
[打印本页]
作者:
祗疼妳一个
时间:
2024-7-13 02:50
标题:
云计算-Spark部分复习(自用)
SPARK(有操作):
1. spark作业
2. spark-RDD(必考编程:常用算子 map groupby key flatmap-单词统计、单词排序)
3. spark-sql(和hive相似,大概有捆绑,如何操作*考的不深,不肯定编程 必须相识操作 判断选择题)
4. spark-streaming(看包、做作业,标题有变换)
一、Spark的代码特点:简洁易懂
二、Spark与Hadoop的对比
三、Spark架构
Spark的基本组件有Excutor,SparkContext和Task
四、Spark的运行基本流程
五、Yarn-cluster和yarn-client
Yarn-cluster适用于生产环境, Yarn-client适用于交互和调试
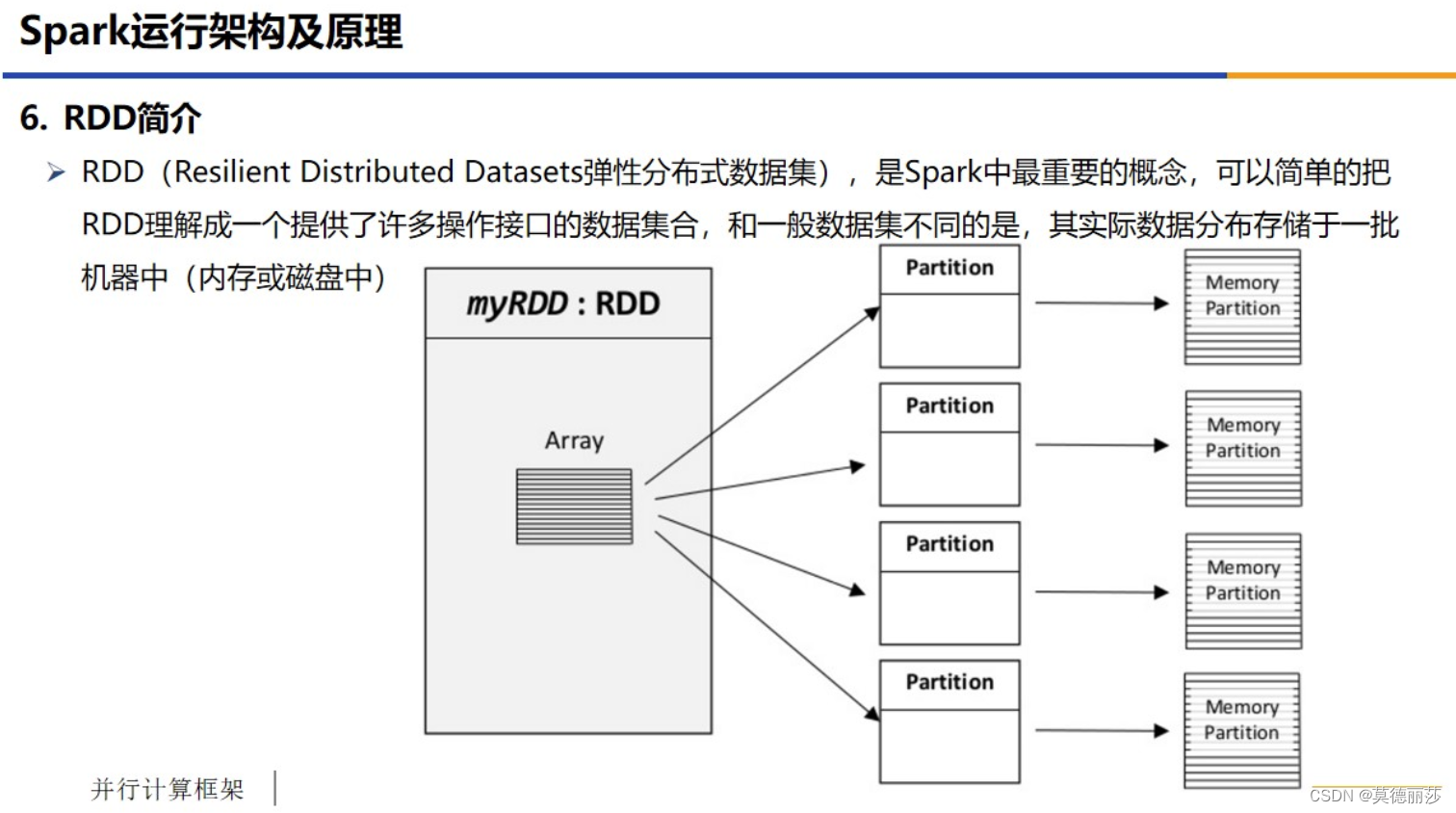
六、RDD简介
七、RDD的特点
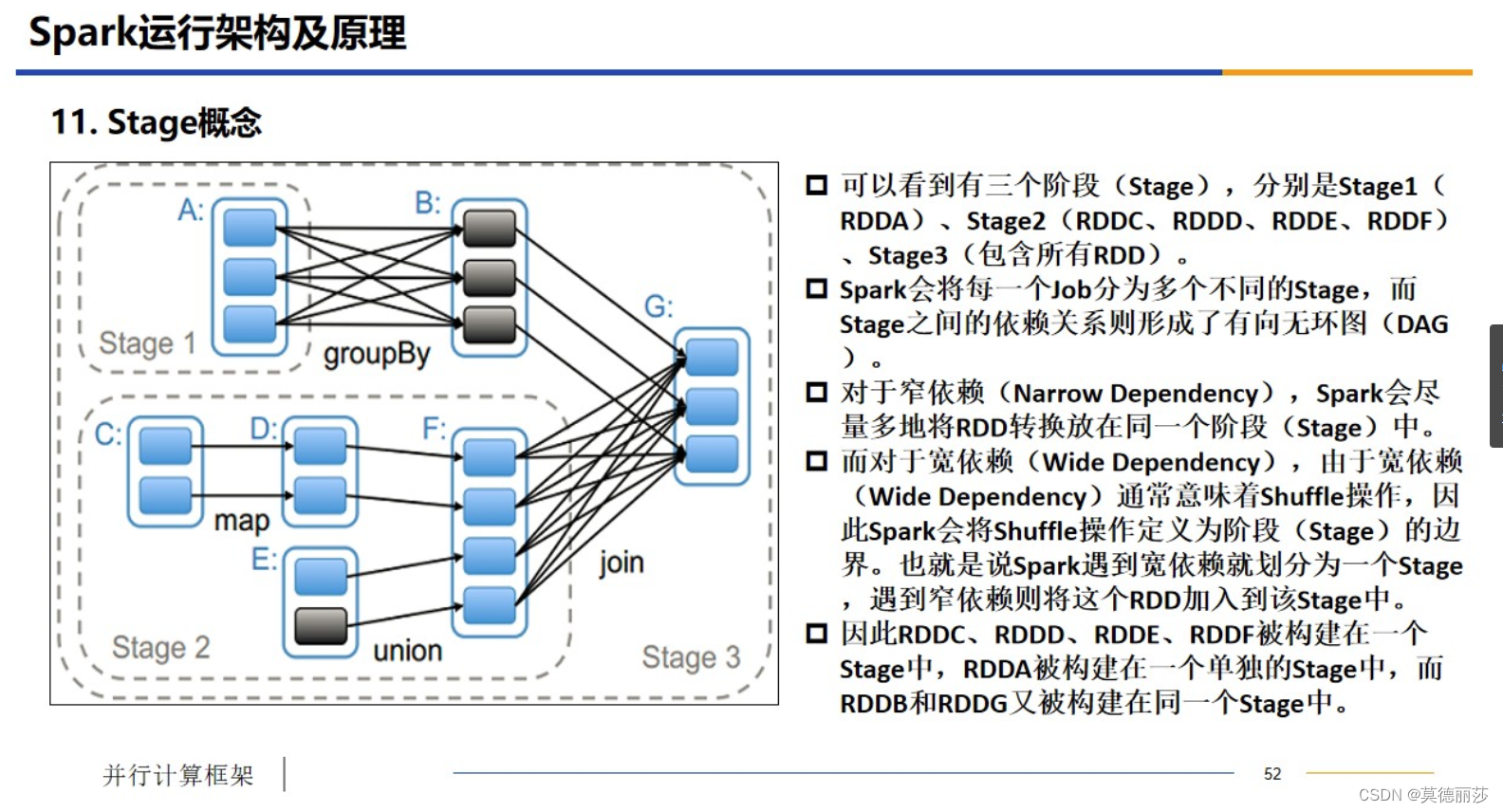
八、Stage的概念
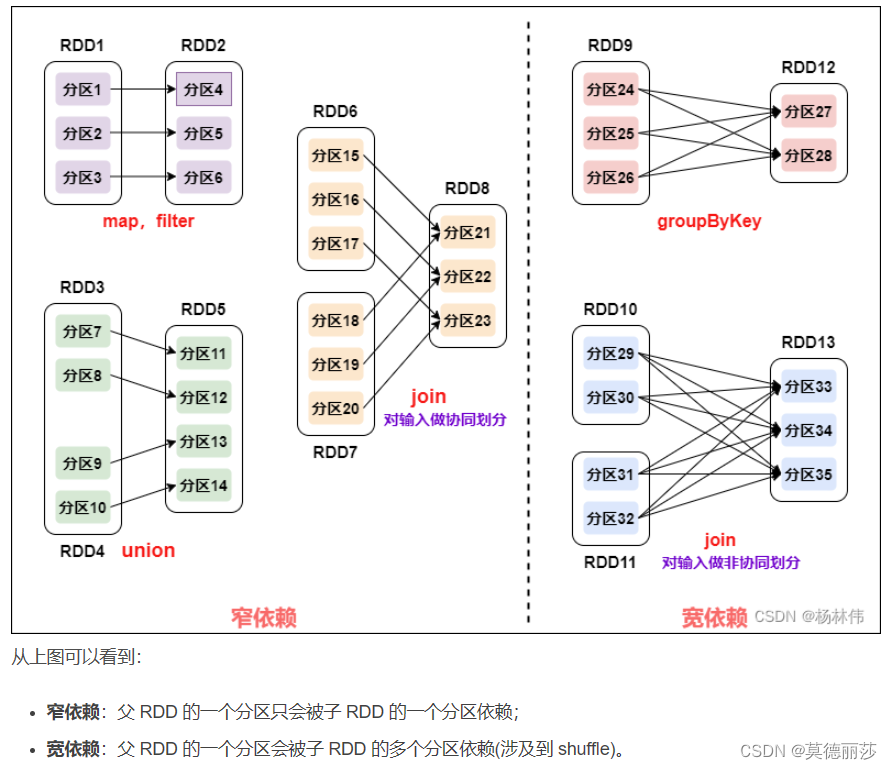
RDD有两种依靠,分别为
宽依靠(wide dependency/shuffle dependency)
和
窄依靠(narrow dependency)
这里借用一下CSDN中杨林伟博主的介绍
1.窄依靠:父RDD的一个分区只会被子RDD的一个分区依靠
2.宽依靠:父RDD的一个分区会被子RDD的多个分区依靠(涉及到Shuffle)
九、Spark的核心原理
1.用户代码(如rdd1.join...)转换为有向无环图(DAG)后,交给DAGScheduler
2.有DAGScheduler把RDD的有向无环图分割成各个Stage的有向无环图形成TaskSet,再提交给TaskScheduler
3.有TaskScheduler把任务(Task)提交给每个Worker上的Executor执行据以的Task
4.在TaskScheduler中,是不知道各个Stage的存在的,运行的只有Task
十、Stage的概念
十一、RDD的转换与操作(门生的平均成绩计算)
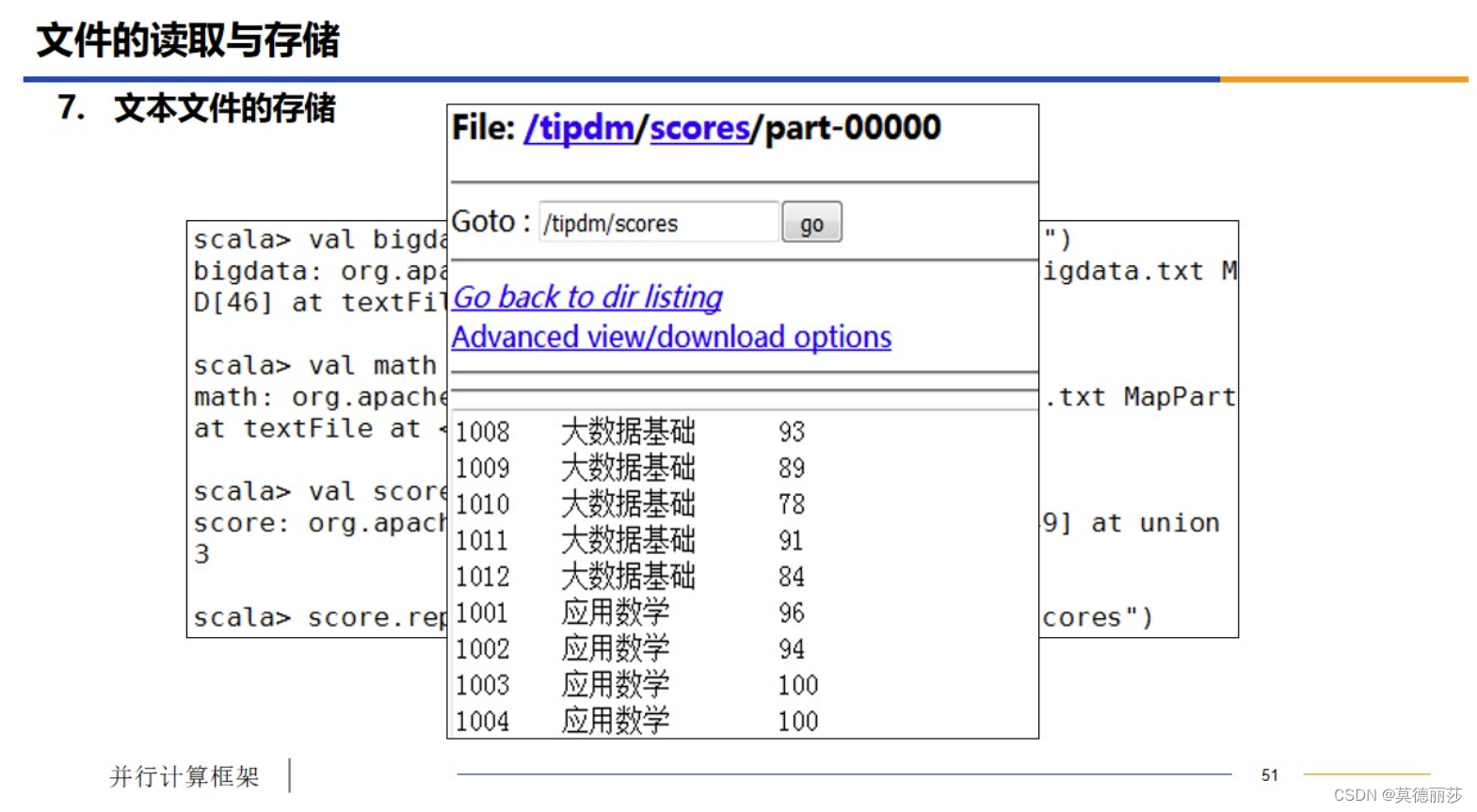
十一、Spark中文件的读取与存储
详细步骤如下
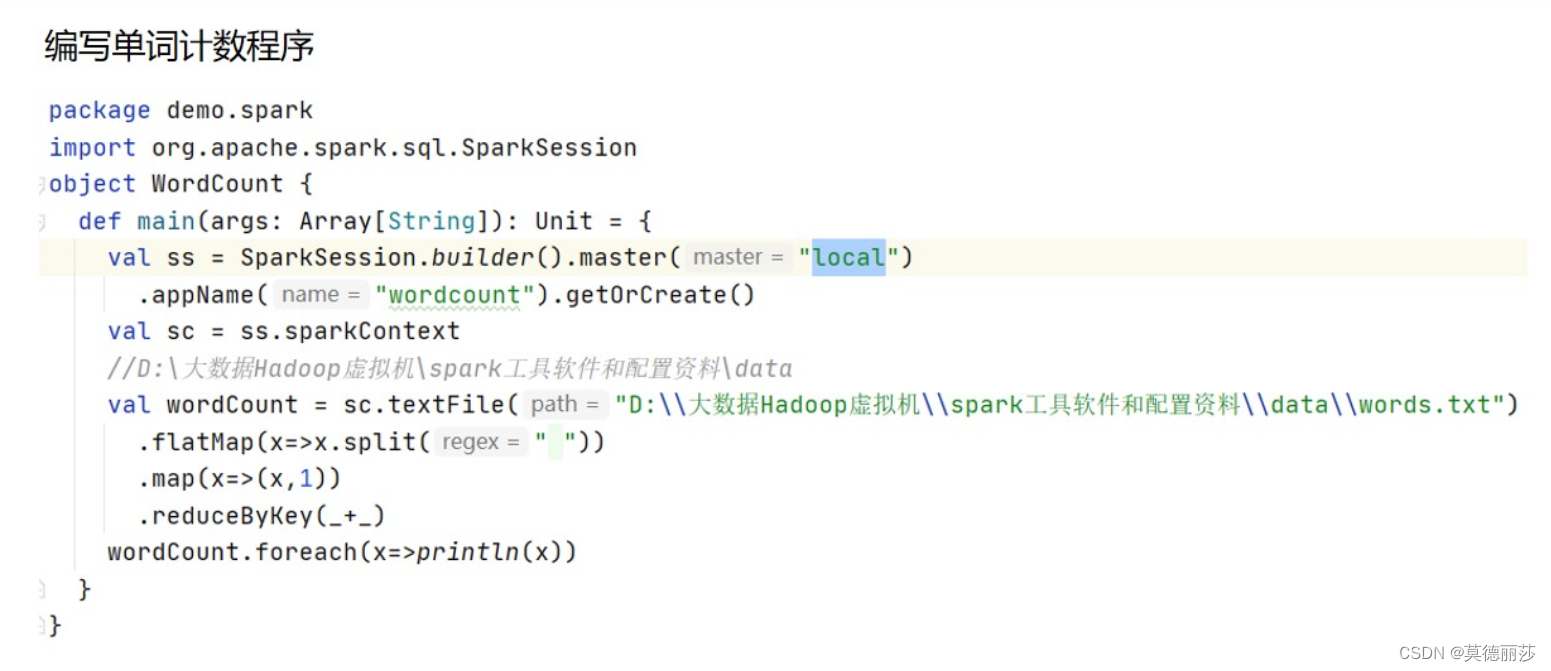
十二、编写SparkWordCount(单词计数步伐)
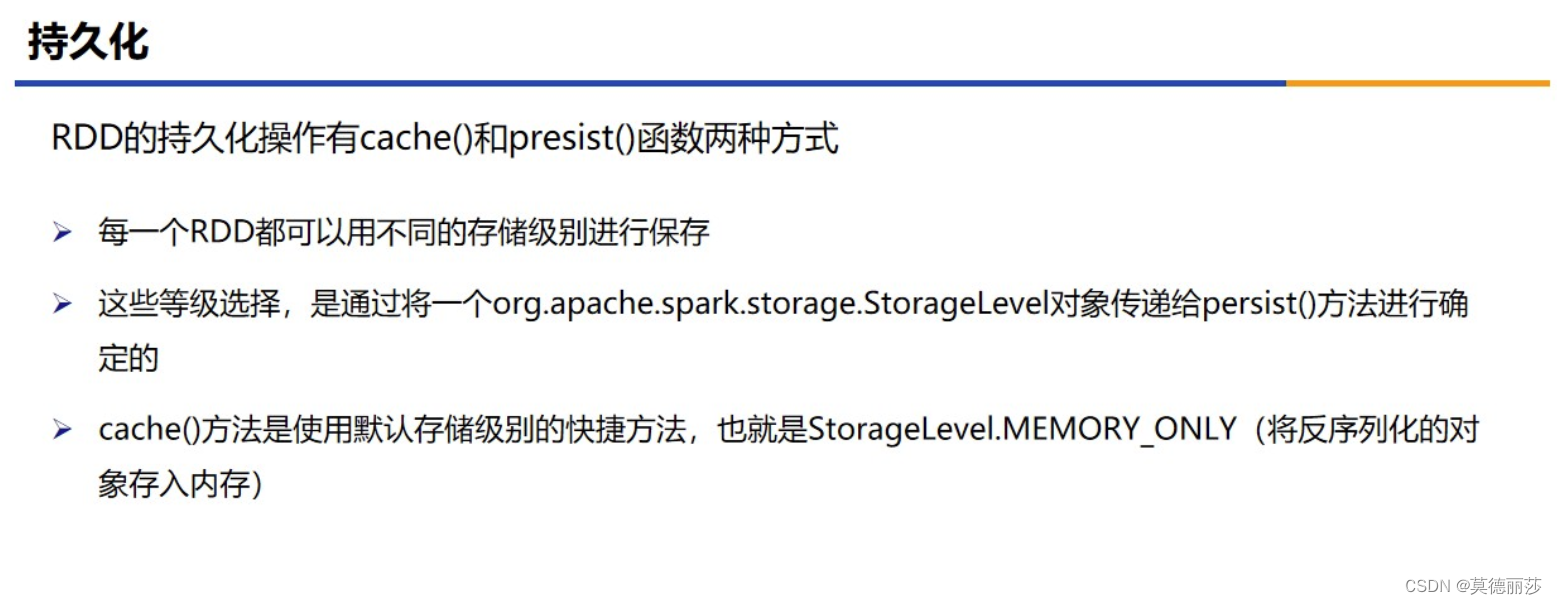
十三、持久化
十四、Spark DataFrame基本操作
① DataFrame
:DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库的二维表格,带有 Schema 元信息(可以理解为数据库的列名和范例)。
DataFrame = RDD + 泛型 + SQL 的操作 + 优化
② DataSet
:DataSet是DataFrame的进一步发展,它比RDD生存了更多的形貌信息,概念上等同于关系型数据库中的二维表,它生存了范例信息,是强范例的,提供了编译时范例检查。调用 Dataset 的方法先会生成逻辑计划,然后被 spark 的优化器进行优化,终极生成物理计划,然后提交到集群中运行!DataFrame = Dateset[Row]
DataFrame = RDD - 泛型 + Schema + SQL + 优化
DataSet = DataFrame + 泛型
DataSet = RDD + Schema + SQL + 优化
DataFrame是一种不可变的分布式数据集,被组织成指定的列,类似于关系数据库中的表
数据集的每一列都带闻名称和范例,对于数据的内部结构又很强的形貌性
RDD是分布式的Java对象的聚集,DataDrame是分布式的Row对象的聚集
十五、读取mysql数据库test的student表
十六、从Hive中的表创建DataFrame
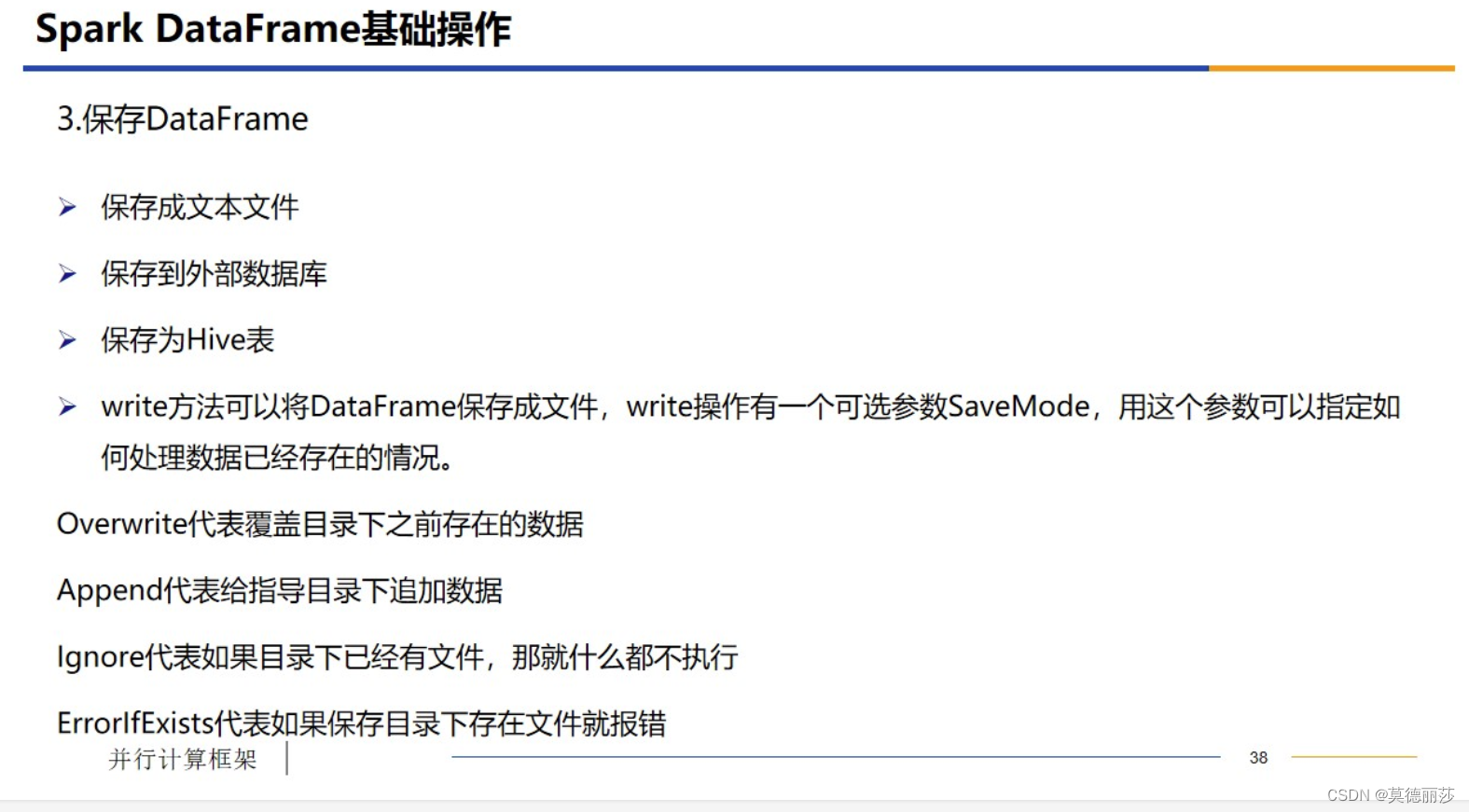
十七、生存DataFrame
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/)
Powered by Discuz! X3.4