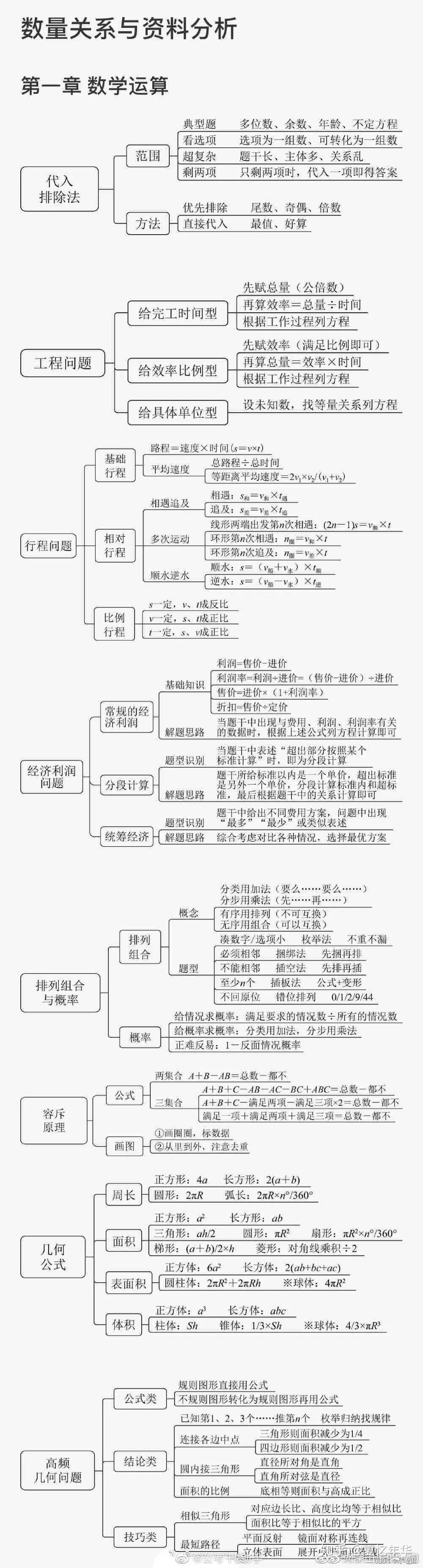
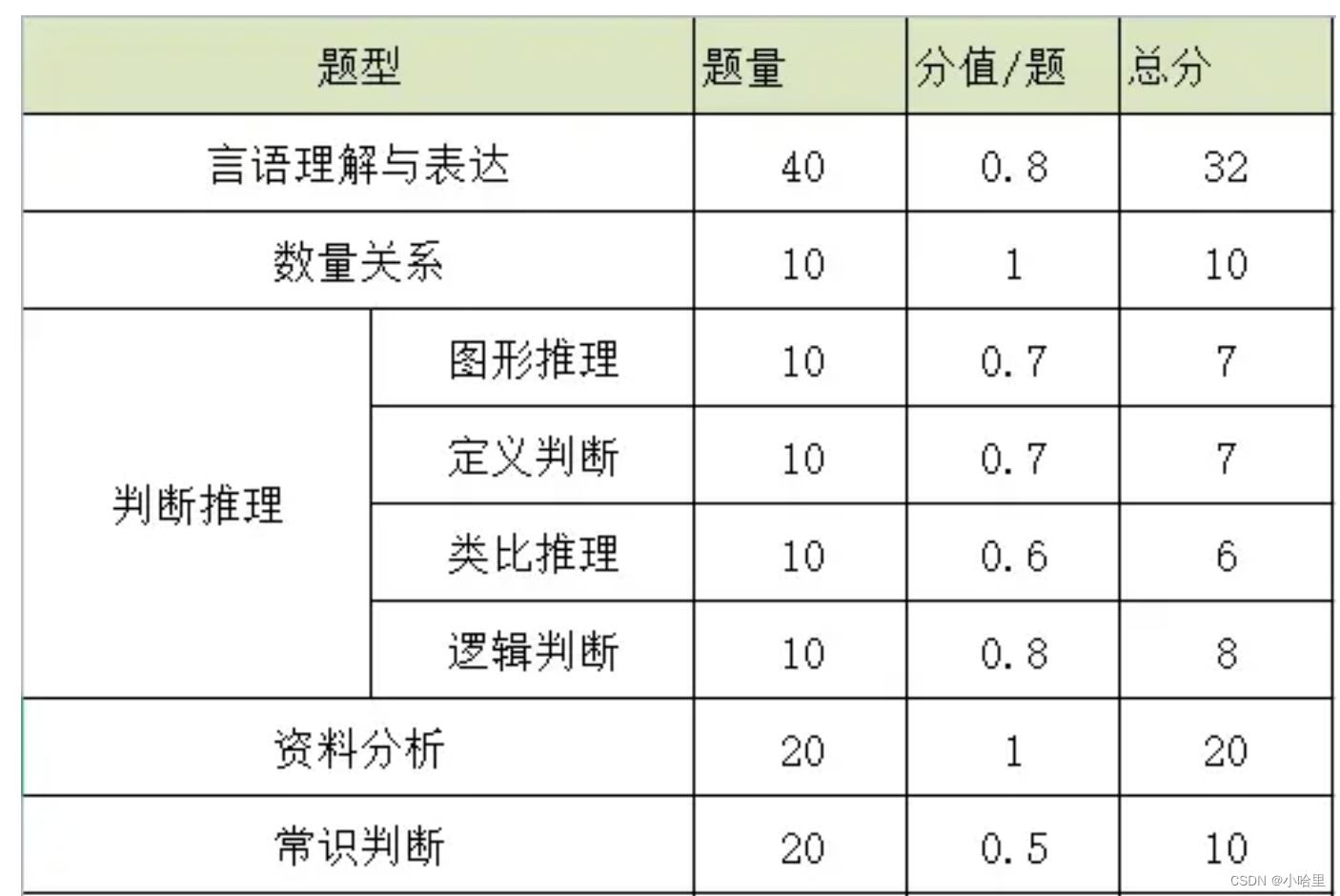
1、常识判断分值分布:考察政治、经济、法律、历史、地理、天然、科技等常识,总共20道题,每题分值在0.5至0.7分左右。
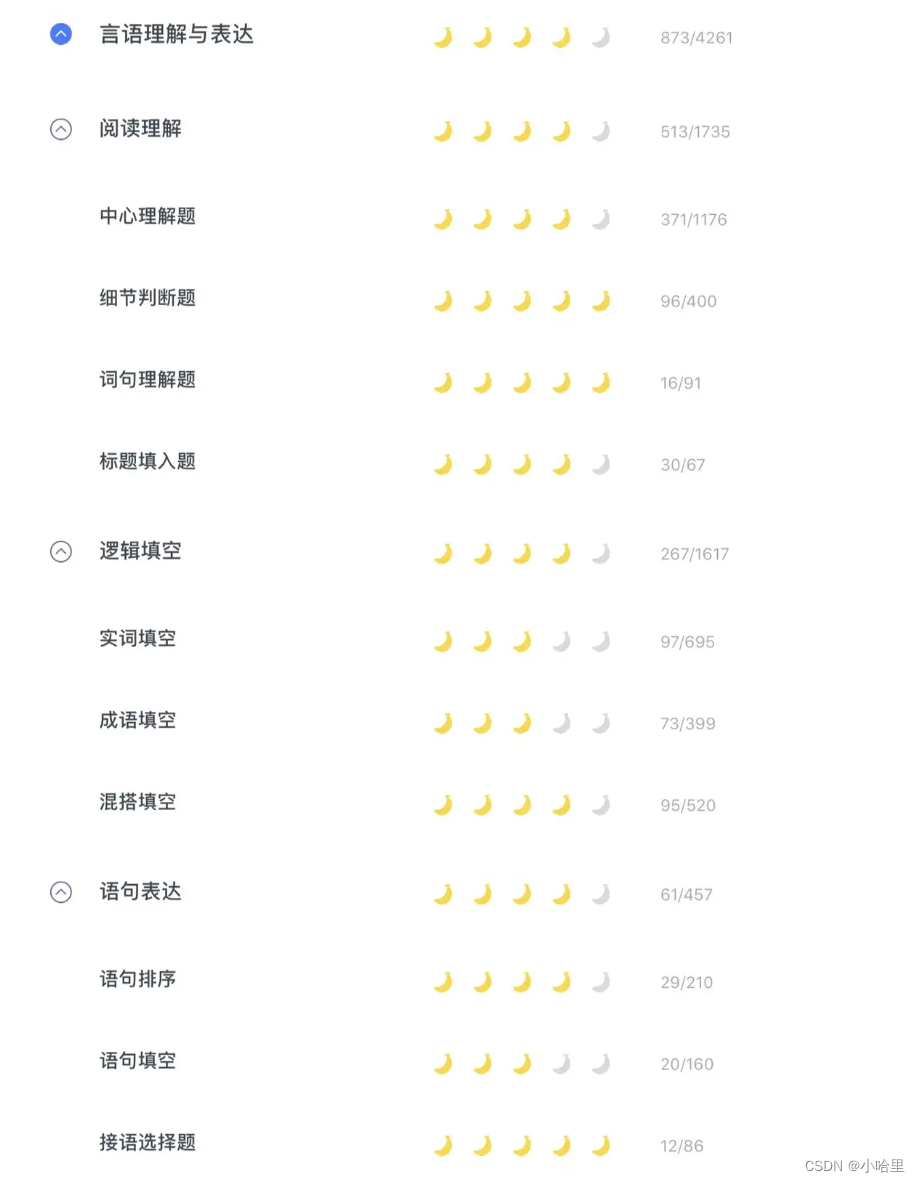
2、言语明白分值分布:选词填空20道题,片断阅读20道题,总共40道题。每题分数在0.6至0.8分左右。
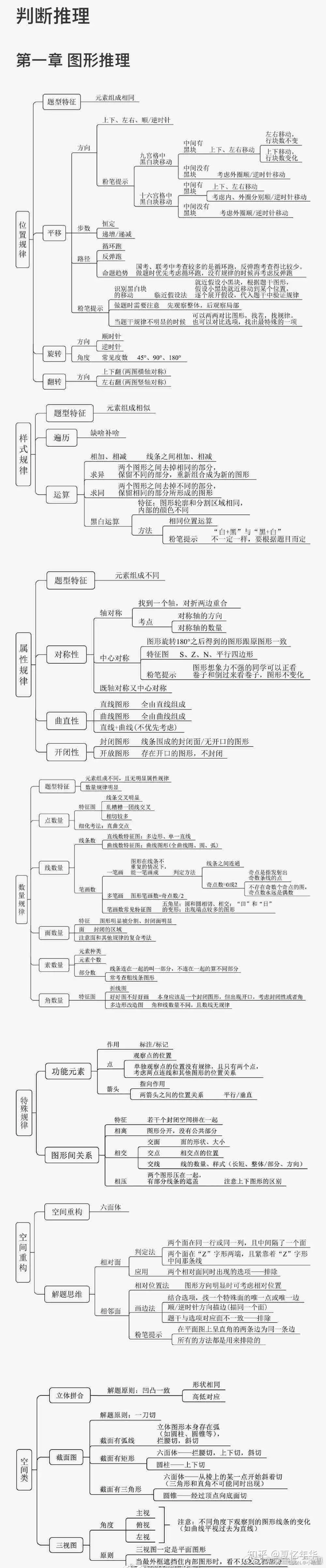
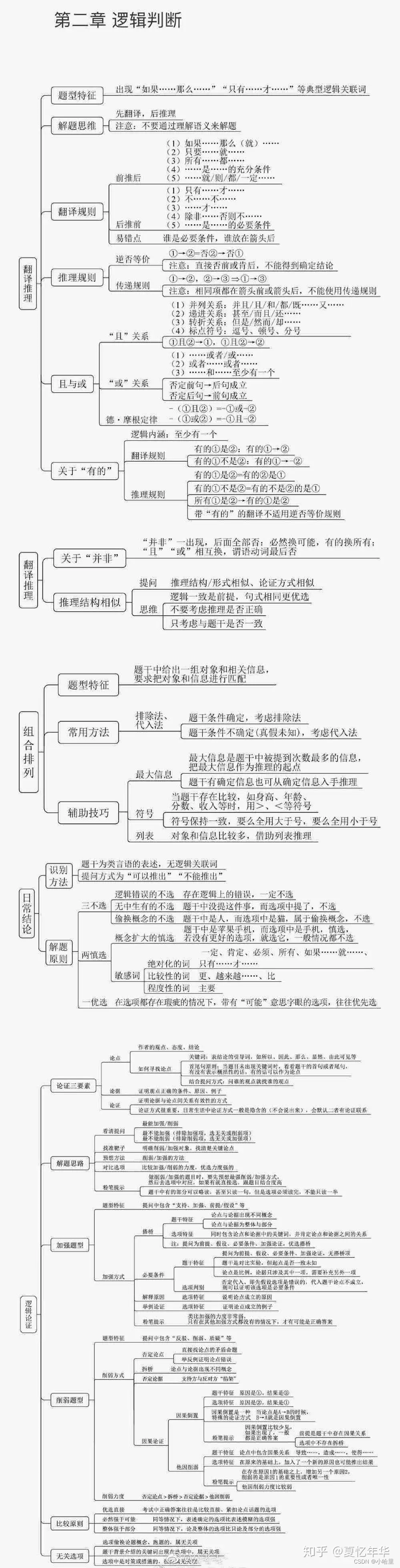
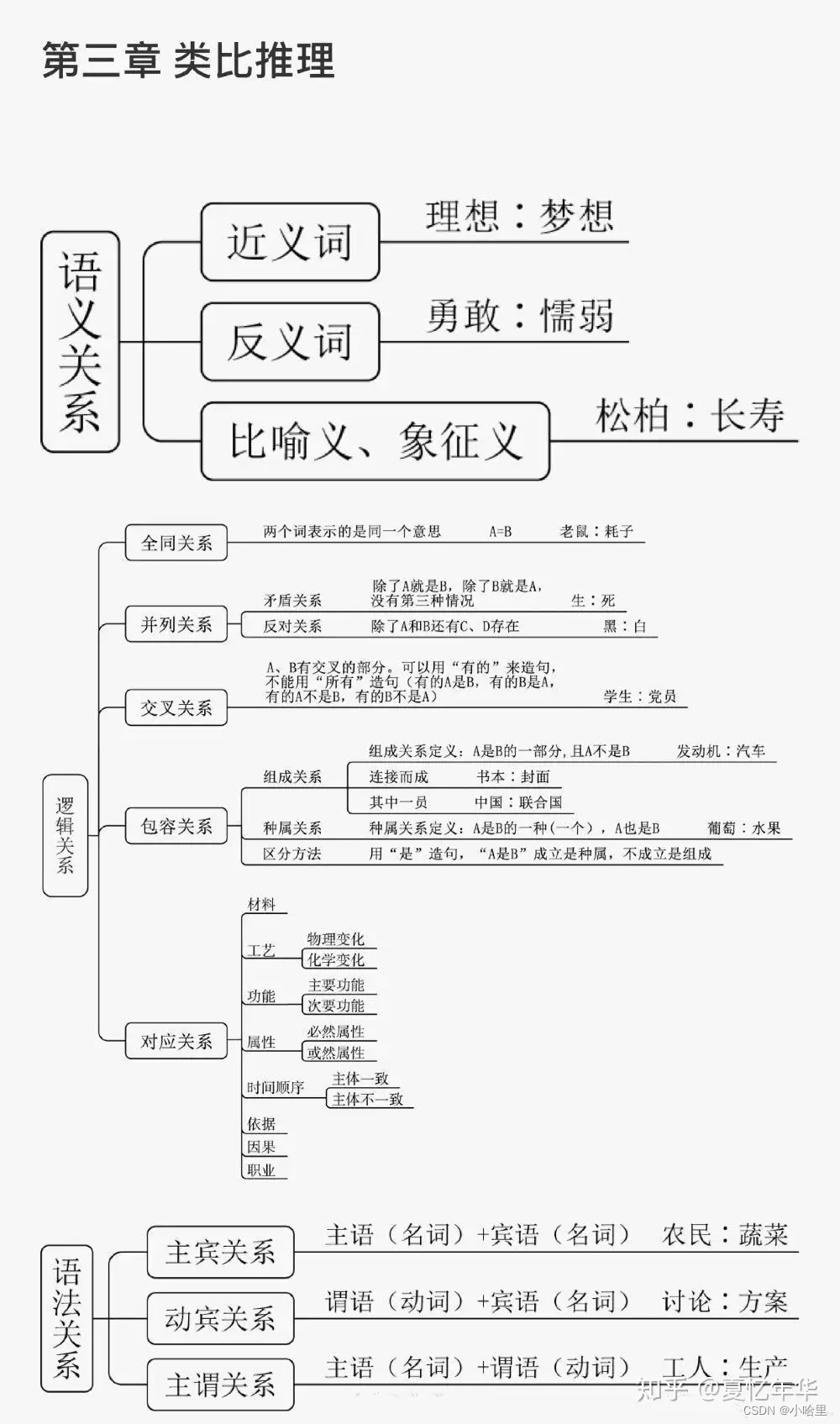
3、判断推理分值分布:界说判断10道题,图形推理10道题,类比推理10道题,逻辑判断10道题,总共40道题。每题分数在0.6至0.8分左右。
4、数学运算分值分布:总共15道题【副省级15题,地市级10题】。每题分值在1分左右。
5、资料分析分值分布:资料分析20题,每题分值在1分左右。
刷题可以刷一刷粉笔