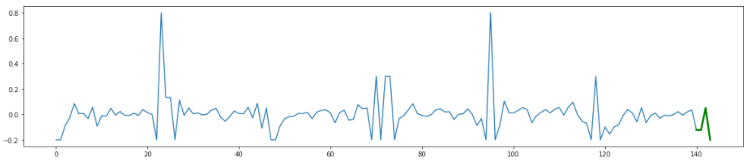
随着组织收集更大的数据集,并大概洞察业务活动,检测非常数据或这些数据集中的非常值对于发现效率低下、罕见事件、问题的根本原因或运营改进机会至关重要。但什么是非常以及为什么检测它很重要?
非常类型因企业和业务职能而异。非常检测仅仅意味着根据业务功能和目标定义“正常”模式和指标,并辨认不属于操作正常行为的数据点。例如,特定时期内网站或应用程序的流量高于平均水平大概表明存在网络安全威胁,在这种情况下,必要一个能够自动触发欺诈检测警报的系统。这也大概只是某个特定营销活动正在发挥作用的标志。非常现象本质上并不是坏事,但了解它们并利用数据将它们置于上下文中,对于理解和掩护您的业务至关重要。
从事数据科学工作的 IT 部门面临的挑战是如何理解不断扩展和不断厘革的数据点。我将先容如何利用人工智能支持的呆板学习技术通过三种差别的非常检测方法来检测非常行为:监督非常检测、无监督非常检测和半监督非常检测。
文章参考Anomaly detection in machine learning: Finding outliers for optimization of business functions - IBM Blog
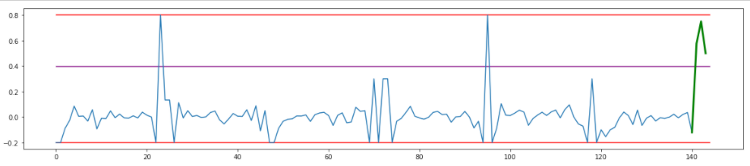
Dynamic threshold estimation for anomaly detection