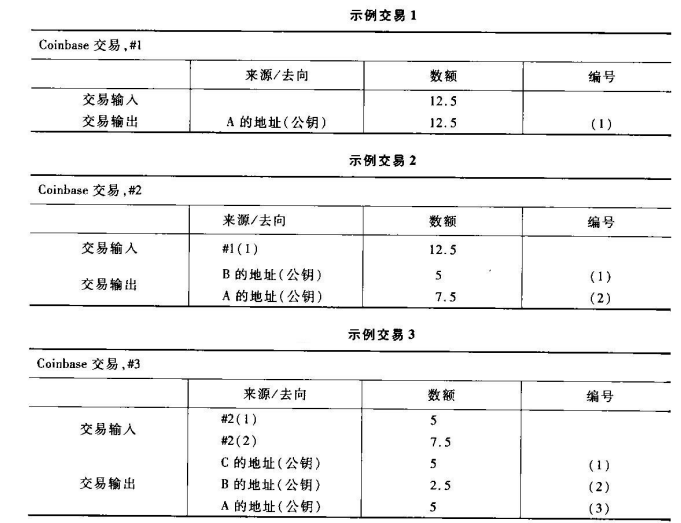
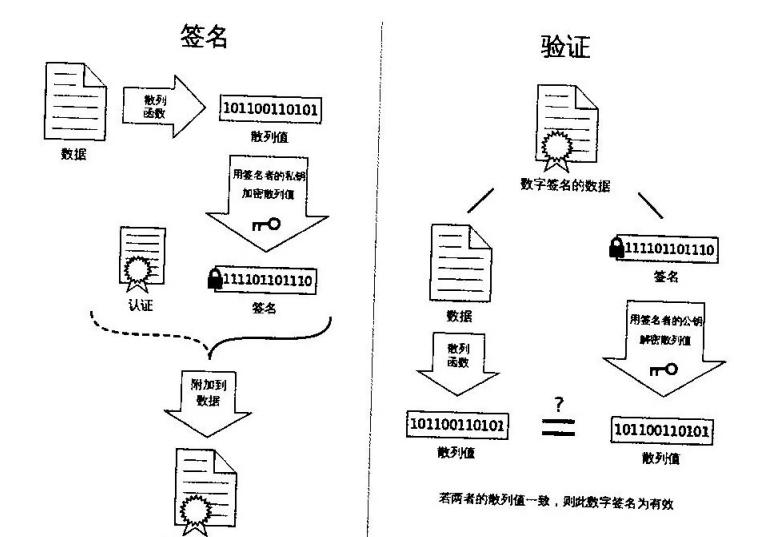
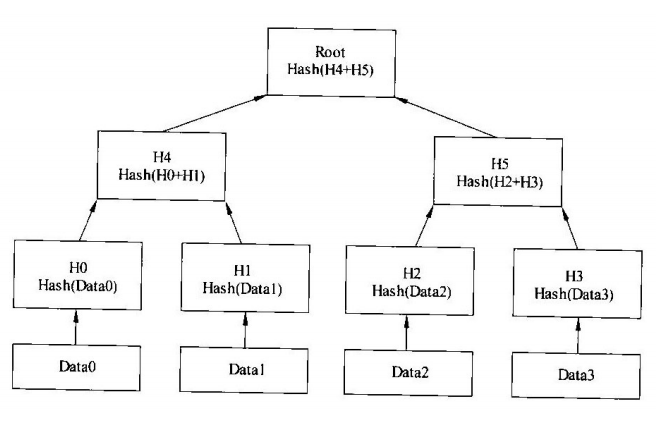
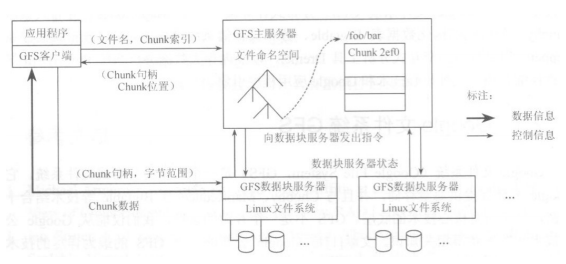
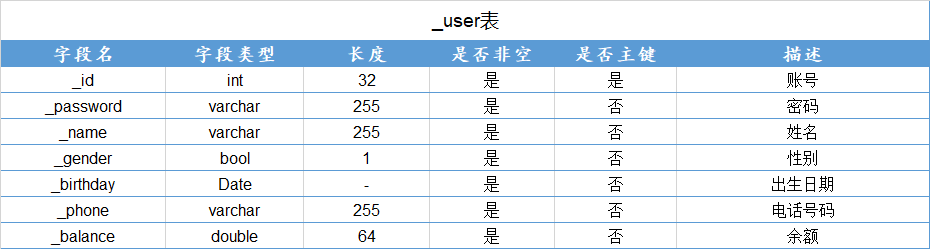
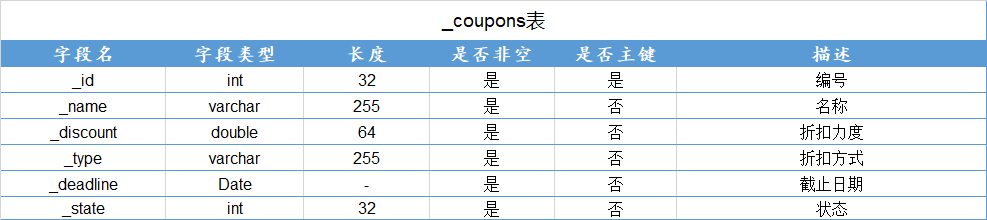
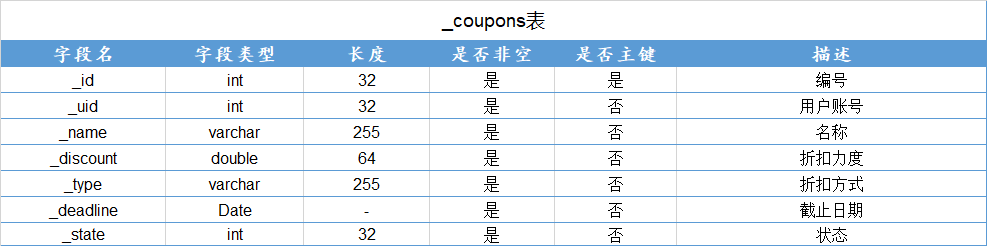
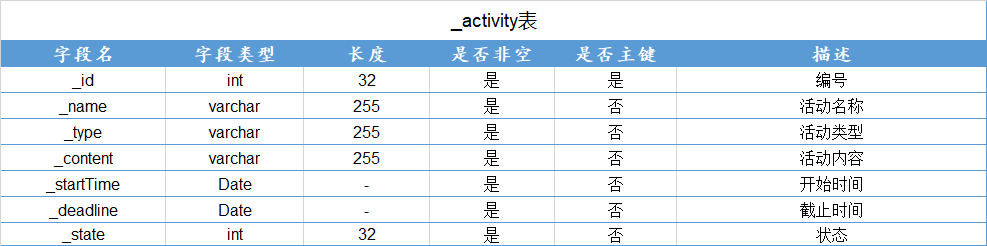
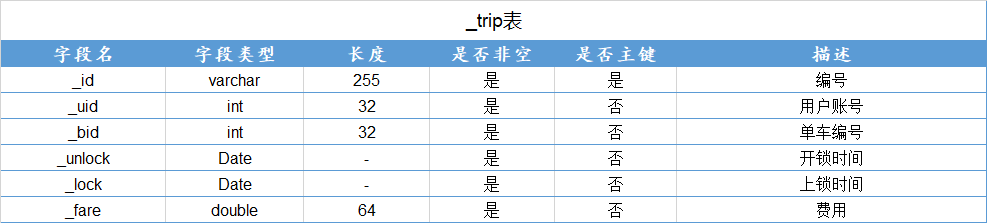
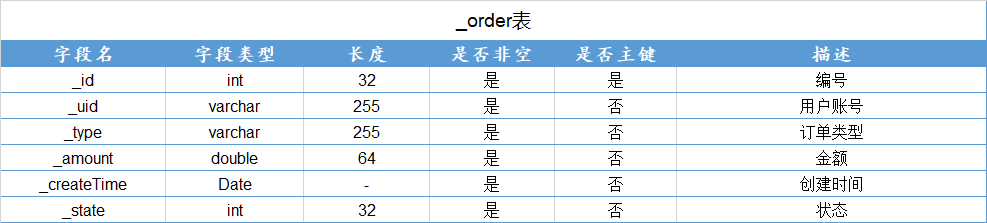
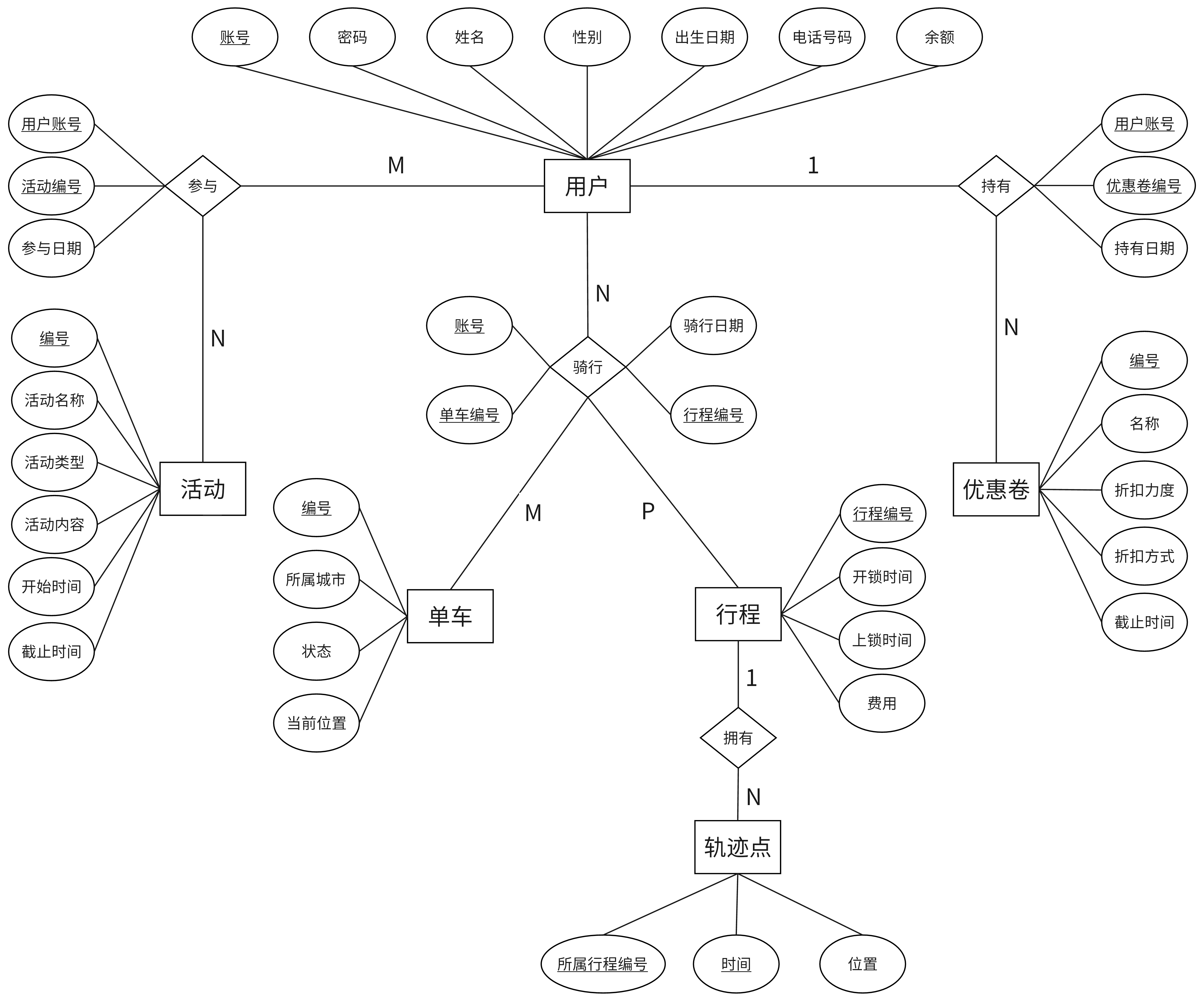
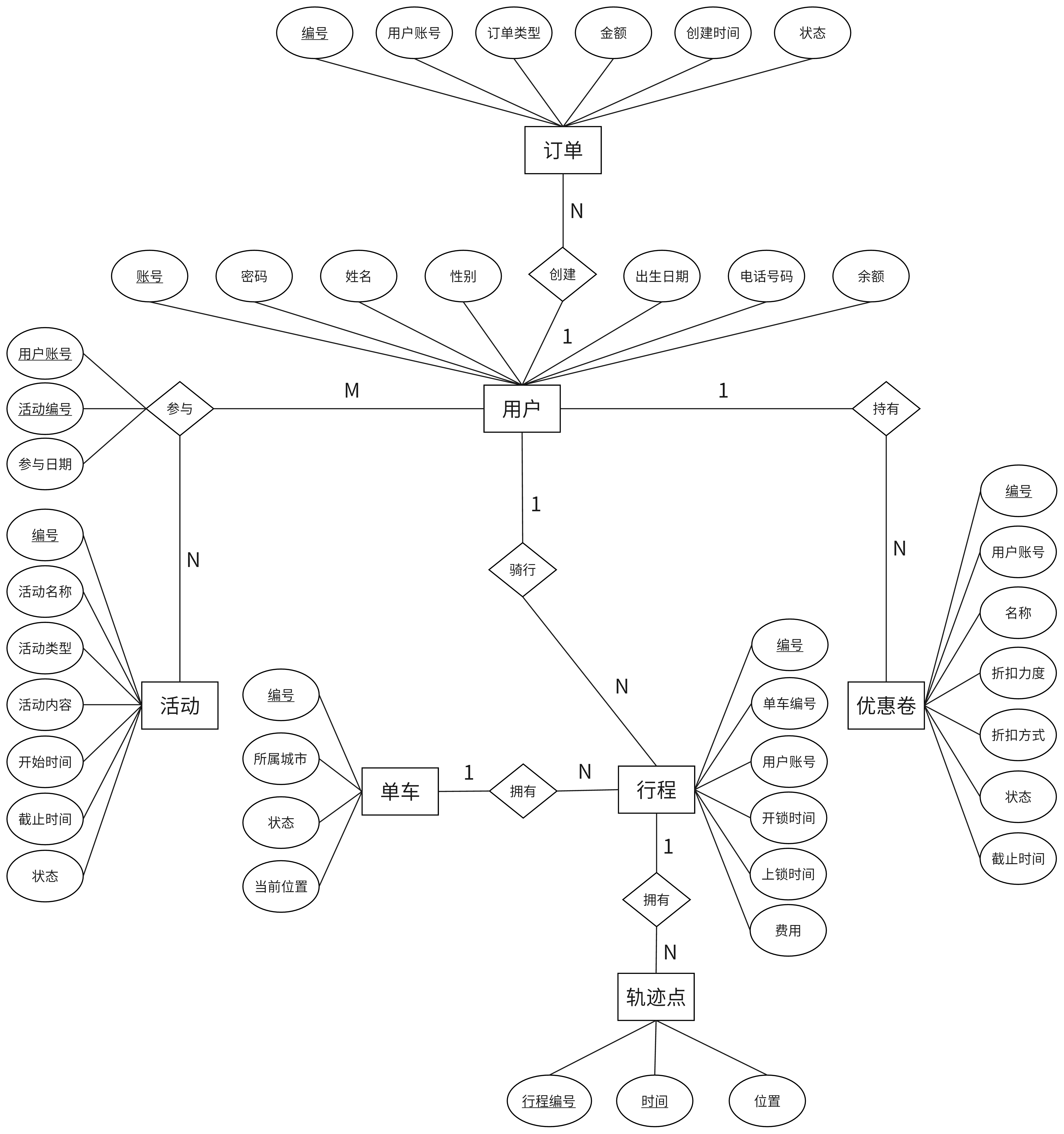
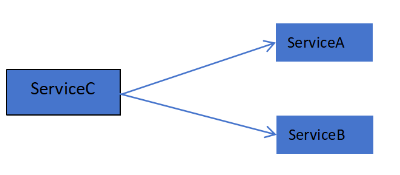
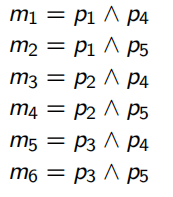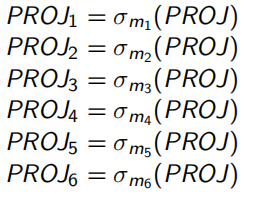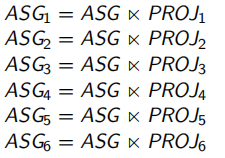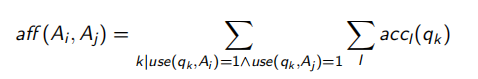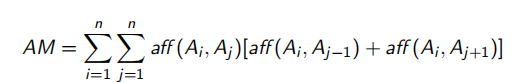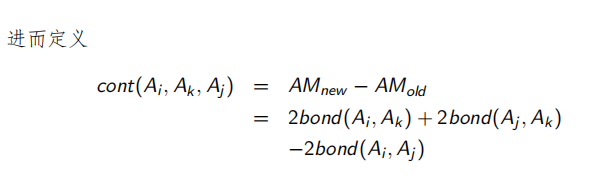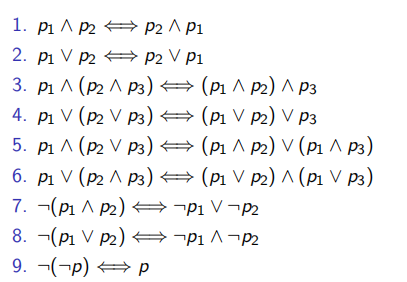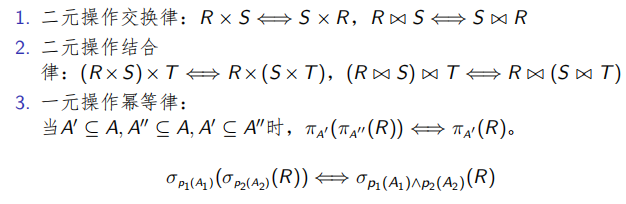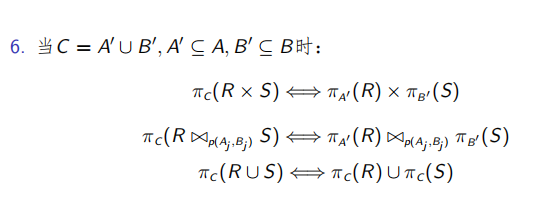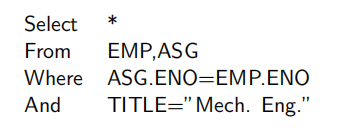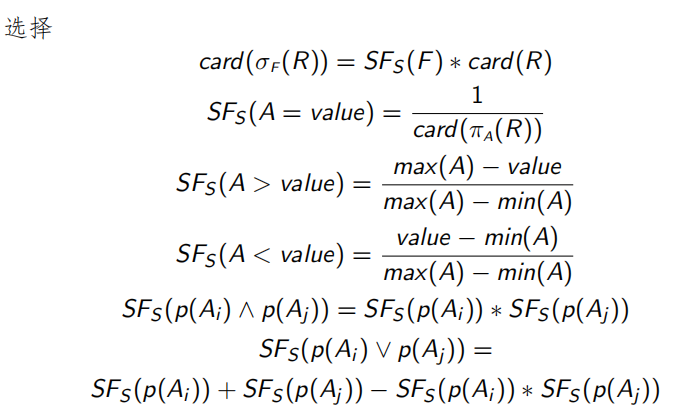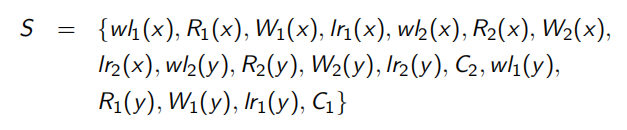查询学号为112的学生年龄
π s a g e ( σ s i d = ′ 11 2 ′ ( S t u 1 ) ) \pi_{sage}(\sigma_{sid='112'}(Stu1)) πsage(σsid=′112′(Stu1))
查询学号为112或者212的学生性别
π s g e n d e r ( σ s i d = ′ 11 2 ′ ∨ s i d = ′ 21 2 ′ ( S t u 1 ∪ S t u 2 ) ) \pi_{sgender}(\sigma_{sid='112' \vee sid='212'}(Stu1\cup Stu2)) πsgender(σsid=′112′∨sid=′212′(Stu1∪Stu2))
查询同时出如今两个学生关系中的学生学号和姓名
π s i d , s n a m e ( S t u 1 ∩ S t u 2 ) \pi_{sid, sname}(Stu1\cap Stu2) πsid,sname(Stu1∩Stu2)
查询出如今学生关系1且不在学生关系2中的学生学号和姓名
π s i d , s n a m e ( S t u 1 − S t u 2 ) \pi_{sid, sname}(Stu1-Stu2) πsid,sname(Stu1−Stu2)
查询学号为112的学生的数据库课程结果
π g r a d e ( σ s i d = ′ 11 2 ′ ∧ c n a m e = ′ 数据 库 ′ ( C o u ⋈ C o u . c i d = S C . c i d S C ) ) \pi_{grade}(\sigma_{sid='112'\wedge cname='数据库' }(Cou\Join_{Cou.cid=SC.cid} SC)) πgrade(σsid=′112′∧cname=′数据库′(Cou⋈Cou.cid=SC.cidSC))
查询学生关系1中选过课的学生学号和姓名
π s i d , s n a m e ( S t u 1 ⋉ S t u 1. s i d = S C . s i d S C ) \pi_{sid, sname}(Stu1\ltimes_{Stu1.sid=SC.sid} SC) πsid,sname(Stu1⋉Stu1.sid=SC.sidSC)
【注:半毗连返回左表中与右表至少匹配一次的数据行,通常表现为 EXISTS 或者 IN 子查询】
查询学号为112的学生年龄
π s a g e ( σ s i d = ′ 11 2 ′ ( S t u 1 ) ) \pi_{sage}(\sigma_{sid='112'}(Stu1)) πsage(σsid=′112′(Stu1))
查询学号为112或者212的学生性别
π s g e n d e r ( σ s i d = ′ 11 2 ′ ∨ s i d = ′ 21 2 ′ ( S t u 1 ∪ S t u 2 ) ) \pi_{sgender}(\sigma_{sid='112' \vee sid='212'}(Stu1\cup Stu2)) πsgender(σsid=′112′∨sid=′212′(Stu1∪Stu2))
查询同时出如今两个学生关系中的学生学号和姓名
π s i d , s n a m e ( S t u 1 ∩ S t u 2 ) \pi_{sid, sname}(Stu1\cap Stu2) πsid,sname(Stu1∩Stu2)
查询出如今学生关系1且不在学生关系2中的学生学号和姓名
π s i d , s n a m e ( S t u 1 − S t u 2 ) \pi_{sid, sname}(Stu1-Stu2) πsid,sname(Stu1−Stu2)
查询学号为112的学生的数据库课程结果
π g r a d e ( σ s i d = ′ 11 2 ′ ∧ c n a m e = ′ 数据 库 ′ ( C o u ⋈ C o u . c i d = S C . c i d S C ) ) \pi_{grade}(\sigma_{sid='112'\wedge cname='数据库' }(Cou\Join_{Cou.cid=SC.cid} SC)) πgrade(σsid=′112′∧cname=′数据库′(Cou⋈Cou.cid=SC.cidSC))
查询学生关系1中选过课的学生学号和姓名
π s i d , s n a m e ( S t u 1 ⋉ S t u 1. s i d = S C . s i d S C ) \pi_{sid, sname}(Stu1\ltimes_{Stu1.sid=SC.sid} SC) πsid,sname(Stu1⋉Stu1.sid=SC.sidSC)
谓词: P i : A i θ V a l u e θ ∈ { = , < , > , ≠ , ≤ , ≥ } P_i: A_i \;\theta\; Value\;\;\; \theta \in \{=,<,>,\not=,\le,\ge\} Pi:AiθValueθ∈{=,<,>,=,≤,≥}
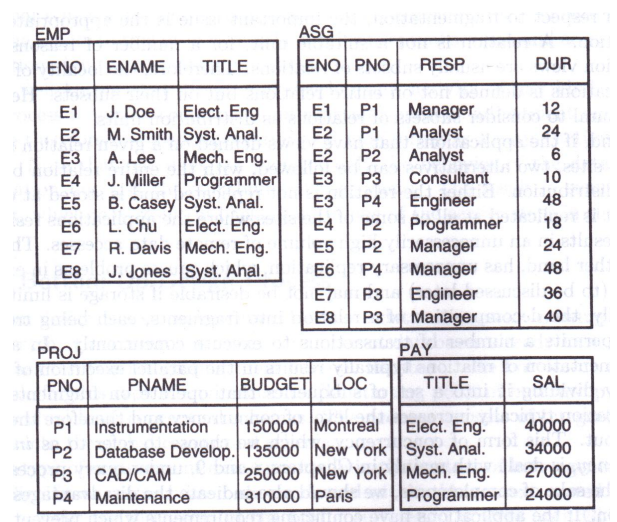
例如: P 1 : L O C = " M o n t r e a l " P_1OC\; = \; "Montreal" P1OC="Montreal"
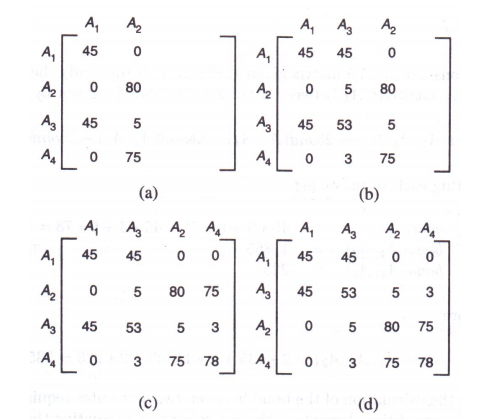
P r i = { p i 1 , P i 2 , . . . , p i m } P_{ri} = \{p_{i1}, P_{i2},. . ., p_{im}\} Pri={pi1,Pi2,...,pim} 是针对关系 r i r_i ri 收集的简朴谓词集合。
P r i P_{ri} Pri 经算法COM-MIN处理后得到 P r i ′ P'_{ri} Pri′。对于关系 r i r_i ri , P r i ′ P'_{ri} Pri′ 是满足分布设计要求的最小简朴谓词集合。
例如,针对关系PROJ得到了 P ′ = { p 1 , P 2 , P 3 , P 4 , P 5 } P'= \{p1, P2, P3, P4, P5\} P′={p1,P2,P3,P4,P5}
p1:LOC = “Montreal”
p2:LOC = “New York”
p3:LOC = "aris’
p4:DUDGET ≤200000
p5:DUDGET > 200000
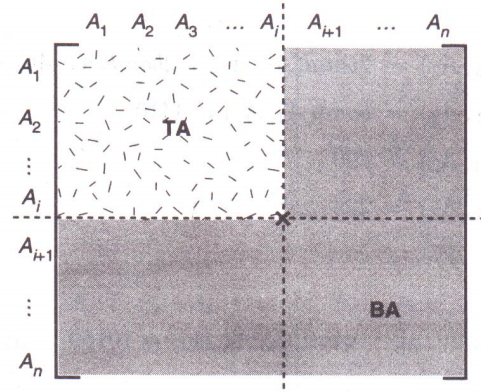
2.3.3 最小谓词集合处理
M i = { m i j ∣ m j j = ∧ p i k ∗ , 1 < j < z , p i k ∗ = p i k ∣ ¬ p i k , p i k ∈ P r i ′ } M_i = \{m_{ij}|m_{jj} = \wedge p^*_{ik}, \; 1<j<z, \;p^*_{ik}=p_{ik}|\neg p_{ik},\; p_{ik}∈P'_{ri} \} Mi={mij∣mjj=∧pik∗,1<j<z,pik∗=pik∣¬pik,pik∈Pri′} M i M_i Mi是关于关系 r i r_i ri最小项谓词集合从 P r i ′ P'_{ri} Pri′中得到,是进行水中分片的依据。
例如,由 P ′ = { p 1 , p 2 , p 3 , p 4 , p 5 } 可得 M = { m j } ( 1 ≤ j ≤ 2 5 ) P'=\{p_1,p_2,p_3, p_4, p_5\}可得M=\{m_j\}\;(1≤j≤2^5) P′={p1,p2,p3,p4,p5}可得M={mj}(1≤j≤25)。然而,谓词间隐含着一些语意。
i 1 : p 1 ⇒ ¬ p 2 ∧ ¬ p 3 i_1:\; p1\Rightarrow \neg p2 \wedge \neg p_3 i1:p1⇒¬p2∧¬p3
i 2 : p 2 ⇒ ¬ p 1 ∧ ¬ p 3 i_2:\; p2\Rightarrow \neg p1 \wedge \neg p_3 i2:p2⇒¬p1∧¬p3
i 3 : p 3 ⇒ ¬ p 1 ∧ ¬ p 2 i_3:\; p3\Rightarrow \neg p1 \wedge \neg p_2 i3:p3⇒¬p1∧¬p2
i 4 : p 4 ⇒ ¬ p 5 i_4:\; p4\Rightarrow \neg p5 i4:p4⇒¬p5
i 5 : p 5 ⇒ ¬ p 4 i_5:\; p5\Rightarrow \neg p4 i5:p5⇒¬p4
i 6 : ¬ p 4 ⇒ p 5 i_6:\; \neg p4\Rightarrow p5 i6:¬p4⇒p5
i 7 : ¬ p 5 ⇒ p 4 i_7:\; \neg p5\Rightarrow p4 i7:¬p5⇒p4
由 i 1 − 7 i_{1-7} i1−7可知, p 1 − 3 p_{1-3} p1−3不可能同时存在, p 4 − 5 p_{4-5} p4−5不可能同时存在,删除非法和重复的最小谓词项后,得到 M = { m i , 1 ≤ i ≤ 6 } M=\{m_i, 1 \le i \le 6\} M={mi,1≤i≤6}
最后根据最小谓词集合M进行水中分片:
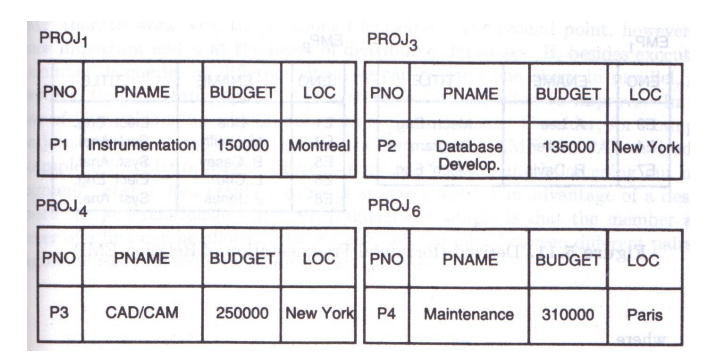
分片结果如下:
其中 P R O J 2 , P R O J 5 PROJ_2, PROJ_5 PROJ2,PROJ5为空,那是由PROJ的当前值决定的,数据库是动态的,PROJ的值也是动态的。
2.3.4 诱导分片
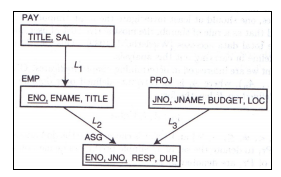
A 1 = P N O , A 2 = P N A M E , A 3 = B U D G E T , A 4 = L O C A_1=PNO, A_2=PNAME, A_3=BUDGET, A4=LOC A1=PNO,A2=PNAME,A3=BUDGET,A4=LOC
u s e ( q i , A j ) = ( 1 0 1 0 0 1 1 0 0 1 0 1 0 0 1 1 ) use(q_i,A_j)= \begin{pmatrix} 1 & 0 & 1 & 0 \\ 0 & 1 & 1 & 0 \\ 0 & 1 & 0 & 1 \\ 0 & 0 & 1 & 1 \end{pmatrix} use(qi,Aj)= 1000011011010011
2.4.2 密切矩阵
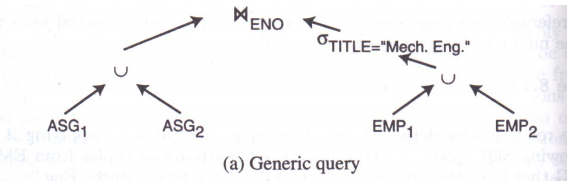
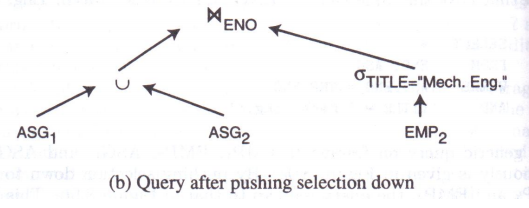
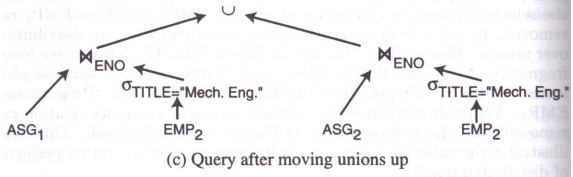
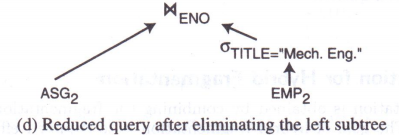
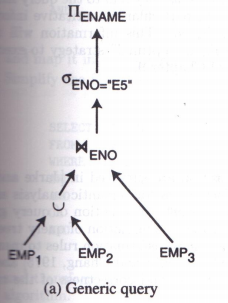
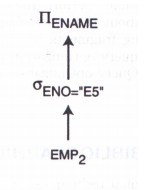
对于查询2:
S E L E T E ∗ F R O M E M P , A S G W H E R E E M P . E N O = A S G . E N O \begin{align} & SELETE\; * \\ & FROM \; EMP,ASG \\ & WHERE \; EMP.ENO=ASG.ENO \end{align} SELETE∗FROMEMP,ASGWHEREEMP.ENO=ASG.ENO
查询的代价可以是查询所斲丧的总时间,也可以是查询的响应时间。总时间指实行查询的各个操纵所斲丧的时间总和,响应时间指查询开始到查询完成所经历的时间。
无论是总时间照旧响应时间,都需通过数据库的统计数据来估算。 常用的统计量
关系R的属性集为 A = { A 1 , A 2 , … , A n } A= \{A_1,A_2,…,A_n\} A={A1,A2,…,An},被分片为 R 1 , R 2 , … , R n R_1,R_2,…,R_n R1,R2,…,Rn
例如,有以下变乱及其之上的调度:
T 1 = { R 1 ( x ) , W 1 ( x ) , G 1 } T_1=\{R_1(x), W_1(x),G_1\} T1={R1(x),W1(x),G1}
T 2 = { W 2 ( x ) , W 2 ( y ) , R 2 ( z ) , C 2 } T2= \{W_2(x),W_2(y), R_2(z),C_2\} T2={W2(x),W2(y),R2(z),C2}
T 3 = { R 3 ( x ) , R 3 ( y ) , R 3 ( z ) , C 3 } T3=\{R_3(x),R_3(y),R_3(z),C_3\} T3={R3(x),R3(y),R3(z),C3}
S = { W 2 ( x ) , W 2 ( y ) , R 2 ( z ) , C 2 , R 1 ( x ) , W 1 ( x ) , C 1 , R 3 ( x ) , R 3 ( y ) , R 3 ( z ) , C 3 } S=\{W_2(x), W_2(y),R_2(z),C_2,R_1(x), W_1(x),C_1, R_3(x), R_3(y),R_3(z),C_3\} S={W2(x),W2(y),R2(z),C2,R1(x),W1(x),C1,R3(x),R3(y),R3(z),C3}
S是对变乱T1,T2,T3的一个调度。s是一个串行调度,实行的次序是T2→T1→T3。串行调度可以包管变乱的隔离性和同等性,串行调度是正确的调度。但是串行调度完全排挤变乱的并发性,服从太低,不可担当。
串行化理论提供了判断并发调度等价于串行调度的方法,把等价于串行调度的调度称为可串行化调度。
4.1.1 集中式可串行化
对同一数据项的读写操纵、写写操纵被称为冲突操纵。例如 W 2 ( x ) , W 1 ( x ) W_2(x),W_1(x) W2(x),W1(x)是一对冲突操纵, W 2 ( y ) , R 3 ( y ) W_2(y),R_3(y) W2(y),R3(y)是另一对冲突操纵。冲突操纵 W 2 ( x ) , W 1 ( x ) W_2(x),W_1(x) W2(x),W1(x)中 W 2 ( x ) W_2(x) W2(x)先于 W 1 ( x ) W_1(x) W1(x),记为 W 2 ( x ) ≺ W 1 ( x ) W_2(x)\prec W_1(x) W2(x)≺W1(x)。同样地, W 2 ( y ) ≺ R 3 ( y ) W_2(y)\prec R_3(y) W2(y)≺R3(y)。根据调度冲突关系绘制调度冲突图,图中无环则为可串行化调度,否则不能判定为可串行化调度
串行化理论扩展到分布式情况上才气解决分布式数据库中的调度标题。
假设调度S’中与x数据项有关的操纵以及C1操纵发生在园地x上,与y数据项有关的操纵以及C2操纵发生在园地y上,与z数据项有关的操纵以及C3操纵发生在园地z上,则S’可改写成:
S x ′ = { W 2 ( x ) , R 1 ( x ) , W 1 ( × ) , C 1 , R 3 ( x ) } S'_x=\{W_2(x),R_1(x), W_1(×),C_1, R_3(x)\} Sx′={W2(x),R1(x),W1(×),C1,R3(x)}
S y ′ = { W 2 ( y ) , R 3 ( y ) , C 2 } S'_y = \{ W_2(y),R_3(y),C_2\} Sy′={W2(y),R3(y),C2}
S z ′ = { R 2 ( z ) , R 3 ( z ) , C 3 } S'_z=\{R_2(z),R_3(z),C_3\} Sz′={R2(z),R3(z),C3}
可分别为 S x ′ , S y ′ , S z ′ S'_x ,S'_y,S'_z Sx′,Sy′,Sz′ 绘制冲突调度图,然后合并为一张图,若无环则为可串行化调度,否则不能作出此判断。
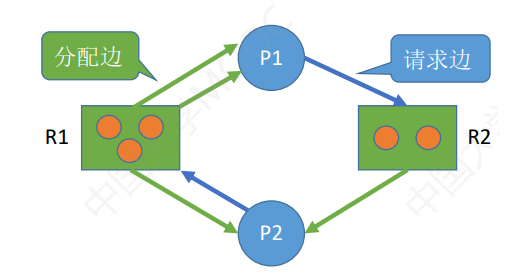
R L i ( x ) RL_i(x) RLi(x) W L i ( x ) WL_i(x) WLi(x) R L j ( x ) RL_j(x) RLj(x)兼容互斥 W L j ( x ) WL_j(x) WLj(x)互斥互斥 WL为写锁,RL为读锁。在对数据项进行操纵前要上锁,如果没有遇到不兼容的锁,上锁成功才气进行现实操纵,否则只有等拥有该锁的变乱释放该锁时才会有时机上锁成功。
例如:
S是关于变乱T1,T2的一个基于锁的调度,其中 l r i ( z ) lr_i(z) lri(z)表示释放变乱 T i T_i Ti对数据项z的锁。
变乱由一组有序的读写操纵构成,变乱 T i T_i Ti写的数据被变乱 T j T_j Tj读取使用后,变乱 T i T_i Ti被回滚了,变乱 T i T_i Ti要怎么办?
答:变乱 T j T_j Tj也只能被回滚。变乱之间存在依赖关系,一个变乱被回滚,依赖它的一系列变乱都要被回滚。级联依赖将导致级联回滚。
变乱 T i T_i Ti写的数据被变乱 T j T_j Tj读取使用后,变乱 T j T_j Tj先实行至commit,变乱 T j T_j Tj可以先提交吗?
答:不能。变乱 T i T_i Ti在没有提交前都有可能回滚,如果变乱 T j T_j Tj先提交了,当 T i T_i Ti被回滚时,就无法回滚 T j T_j Tj了。而在这种情况下,是必须回滚 T j T_j Tj的。变乱 T j T_j Tj必须等待变乱 T i T_i Ti提交之后才气提交。级联依赖关系也会导致变乱提交的级联等待。
MVCC导致数据版本不停累积,是否有必要保存所有的数据版本。
答:没必要。过多的数据版本也会浪费存储资源。数据库系统每隔一段时间运行垃圾处理步调删除无用的数据版本。判定无用的规则:在写时间印小于系统当前最老变乱的时间印的数据版本中,WTS( O i O_i Oi)最大,保存 O i O_i Oi,写时间印小于WTS( O i O_i Oi)的数据版本均无用。
其中,plan_type = 1、2、3 分别表示 Local 、Remote 、Distribute 实行计划。一样寻常来讲,0 代表无 plan 的 SQL 语句,比如:set autocommit=0/1,commit 等。
非 Local 计划的请求(0除外),大概率会导致变乱跨机,相对于单机变乱,性能会有一定的影响。可按照以下几种情况进行检查,Primary Zone 为单 Zone & 单 Unit,Primary Zone 为单 Zone & 多 Unit 和 Primary Zone 为 RANDOM。







 OC\; = \; "Montreal" P1
OC\; = \; "Montreal" P1 aris’
aris’