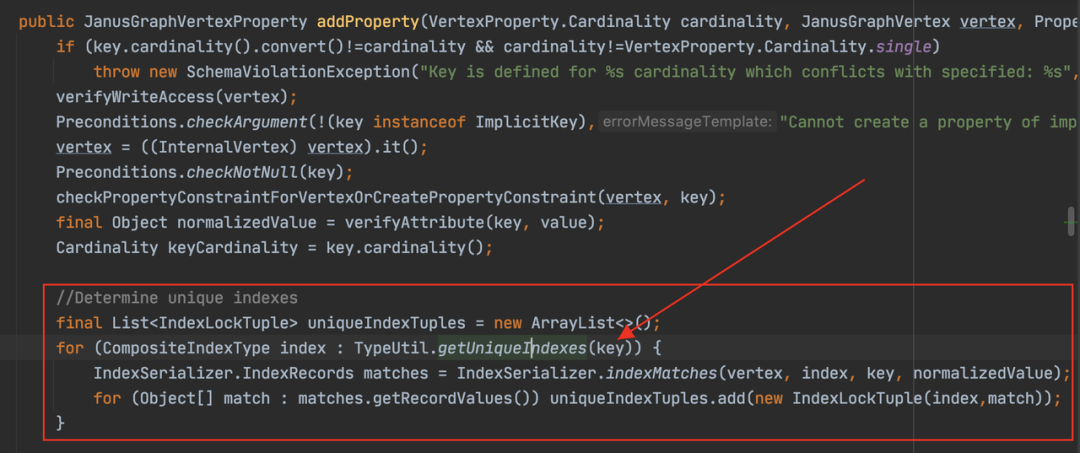
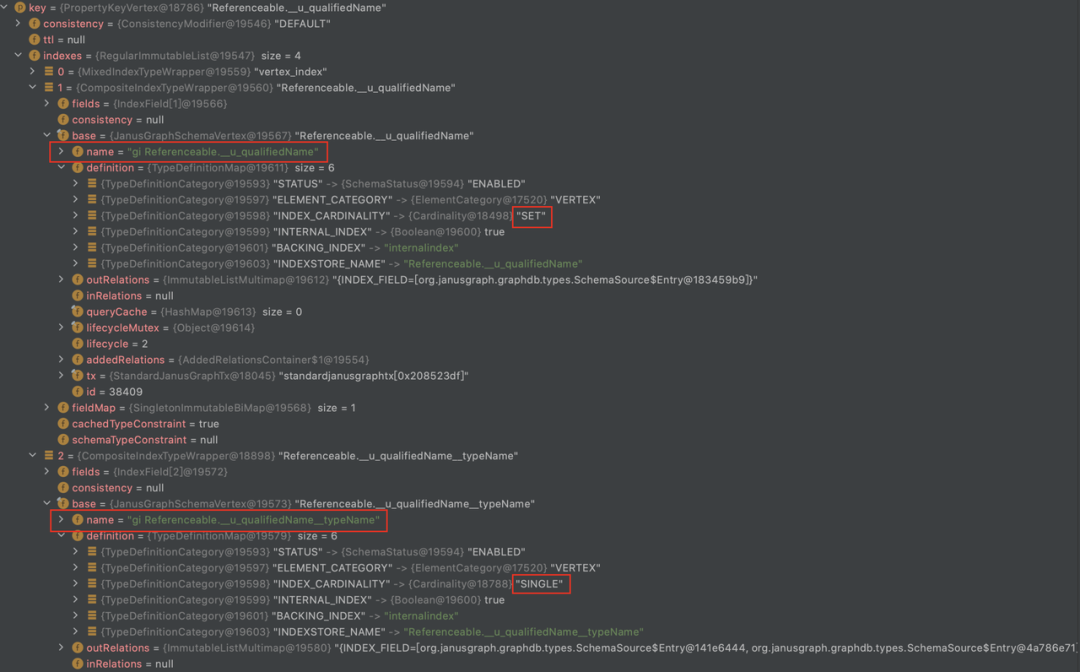
过度优化:与引擎类系统不同,业务系统通常不需要跑分或者与其他系统产出性能对比报表,实际工作中更多的是贴合业务场景做优化。比如用户直接访问前端界面的系统,通常不需要将响应时间优化到 ms 以下,几十毫秒和几百毫秒,已经是满足要求的了。
优化范围选择
对于一个业务类 Web 服务来说,特别是重构阶段,优化范围比较容易圈定,主要是找出与之前系统相比,明显变慢的那部分 API,比如可以通过以下方式收集需要优化的部分:
• 通过前端的慢查询捕捉工具或者后端的监控系统,筛选出 P90 大于 2s 的 API
• 页面测试过程中,研发和测试同学陆续反馈的 API
• 数据导入过程中,研发发现的写入慢的 API 等
优化目标确立
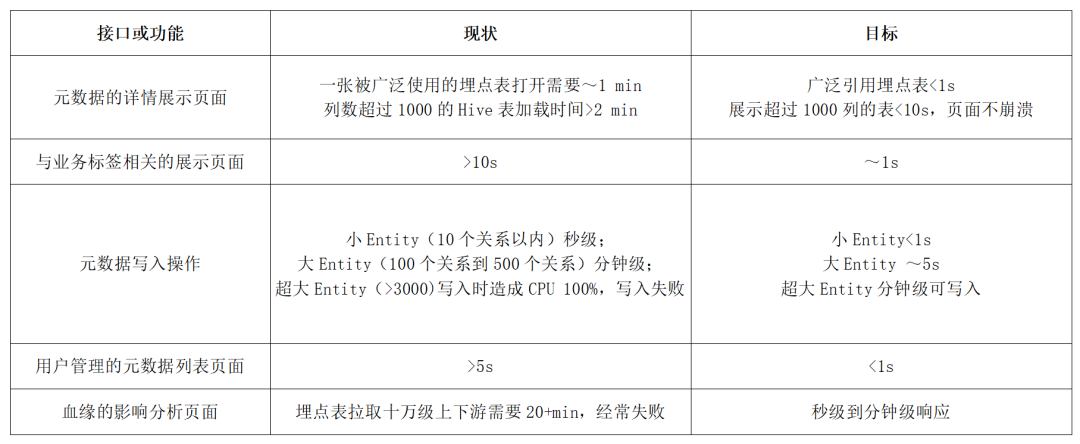
针对不同的业务功能和场景,定义尽可能细致的优化目标,以 Data Catalog 系统为例:
定位性能瓶颈手段
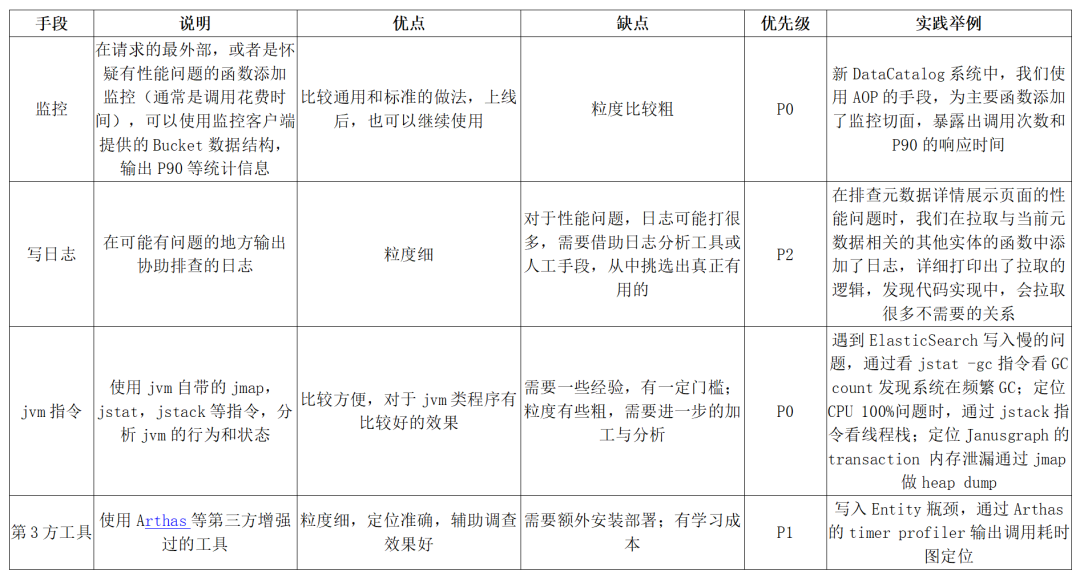
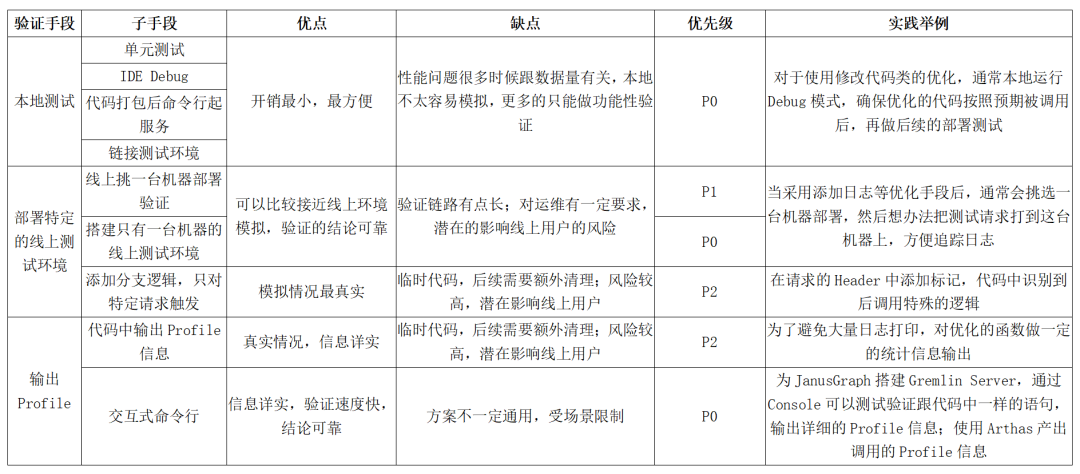
系统复杂到一定程度时,一次简单的接口调用,都可能牵扯出底层广泛的调用,在优化某个具体的 API 时,如何准确找出造成性能问题的瓶颈,是后续其他步骤的关键。下面的表格是我们总结的常用瓶颈排查手段。
优化策略