IT评测·应用市场-qidao123.com
标题:
Hadoop学习心得
[打印本页]
作者:
大连密封材料
时间:
2024-7-16 02:42
标题:
Hadoop学习心得
自从我开始接触Hadoop,这个大数据处理的开源框架,我的学习之路就布满了挑衅与收获。Hadoop以其强盛的数据处理本领和高度的可扩展性,成为了大数据范畴的一颗璀璨明星。以下是我对Hadoop学习的一些心得和体会。
一、初识Hadoop
在开始学习Hadoop之前,我对大数据和分布式盘算的概念还相对模糊。但随着对Hadoop的深入了解,我渐渐熟悉到它的重要性。Hadoop不但仅是一个技能框架,更是一种处理大数据的思维方式。它通过将数据划分为多个小块,并在集群中的多个节点上并行处理,从而实现了对海量数据的快速处理。
二、学习过程中的挑衅
在学习Hadoop的过程中,我碰到了很多挑衅。首先,Hadoop的生态体系庞大而复杂,包括HDFS、MapReduce、YARN等多个组件,每个组件都有其独特的功能和用法。我需要花费大量的时间和精力去熟悉这些组件,并明白它们之间的相互作用。其次,Hadoop的配置和摆设也是一个复杂的过程,需要仔细配置各种参数和环境变量,以确保集群的稳固运行。此外,Hadoop的编程模型MapReduce也具有一定的学习难度,需要把握其编程范式和数据处理流程。
三、 hadoop的焦点构架
Hadoop 由很多元素构成。其最底部是 Hadoop Distributed File System(HDFS),它存储 Hadoop 集群中所有存储节点上的文件。HDFS的上一层是MapReduce 引擎,该引擎由 JobTrackers 和 TaskTrackers 构成。通过对Hadoop分布式盘算平台最焦点的分布式文件体系HDFS、MapReduce处理过程,以及数据仓库工具Hive和分布式数据库Hbase的介绍,根本涵盖了Hadoop分布式平台的所有技能焦点。
1.HDFS
对外部客户机而言,HDFS就像一个传统的分级文件体系。可以创建、删除、移动或重命名文件,等等。
2.NemeNode
NameNode 是一个通常在 HDFS 实例中的单独机器上运行的软件
3.DetaNode
DataNode 也是一个通常在 HDFS实例中的单独机器上运行的软件
四、MapReduce编程
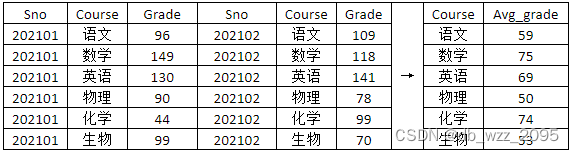
现有以下数据,现要求统计本次月考各科目平均结果
Map类
package task1;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class ScoreMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 将文本行拆分为字段
String[] fields = value.toString().split(",");
// 获取课程和分数
String course = fields[1];
int score = Integer.parseInt(fields[2]);
// 发送课程和分数到Reduce阶段
context.write(new Text(course), new IntWritable(score));
}
}
复制代码
Reduce类
package task1;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class ScoreReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
int count = 0;
// 遍历所有分数,求和并计数
for (IntWritable value : values) {
sum += value.get();
count++;
}
// 求平均数
int average = Math.round((float) sum / count); // 四舍五入到最接近的整数
// 输出键值对
context.write(key, new IntWritable(average));
}
}
复制代码
main方法
package task1;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class ScoreAverage {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Score Average");
job.setJarByClass(ScoreAverage.class);
job.setMapperClass(ScoreMapper.class);
job.setReducerClass(ScoreReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job,new Path("D:\\Hadoop课程\\代码\\begin\\Hadoop\\input\\subject_score.csv"));
FileOutputFormat.setOutputPath(job,new Path("D:\\Hadoop课程\\代码\\begin\\Hadoop\\output1\\avgcount"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
复制代码
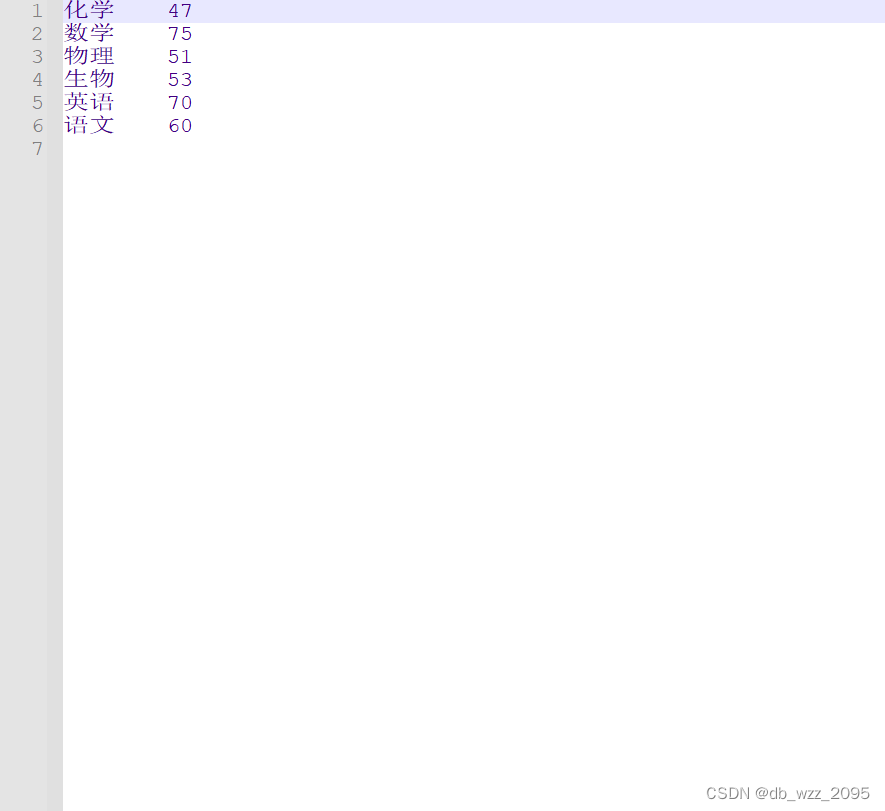
输出效果
五、总结 学习心得
通过这一个学期的学习,我对hadoop的明白也多了很多,学习了很多东西这里我就写了很少的一部分。
可以讲Hadoop的焦点内容看作是两个部分,一个是分布式存储,一个是分布式盘算。
对于分布式存储,Hadoop有自己的一套体系来处理叫Hadoop distribution file system。为什么分布式存储需要一个额外的体系来处理呢,而不是就把1TB以上的文件分开存放就好了呢。假如不采用新的体系,我们存放的东西没办进行一个统一的管理。存放在A电脑的东西只能在连接到A去找,存在B的又得单独去B找。繁琐且未便于管理。而这个分布式存储文件体系能把这些文件分开存储的过程透明化,用户看不到文件是怎么存储在不同电脑上,看到的只是一个统一的管理界面。如今的云盘就是很好的给用户这种体验。
对于分布式盘算。在对海量数据进行处理的时候,一台机器肯定也是不够用的。以是也需要思量将将数据分在不同的机器上并行的进行盘算,这样不经可以节省大量的硬件的I/O开销。也能够将加快盘算的速率。Hadoop对分布式盘算的体系为MapReduce。
Map即将数据分开存放进行盘算,Reduce将分布盘算的得到的效果进行整合,末了汇总得到一个最终的效果。这样对Hadoop的技能有一个清晰框架思绪。
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 IT评测·应用市场-qidao123.com (https://dis.qidao123.com/)
Powered by Discuz! X3.4