标题: 通用大模型研究重点之五:llama family [打印本页] 作者: 石小疯 时间: 2024-7-17 10:33 标题: 通用大模型研究重点之五:llama family LLAMA Family
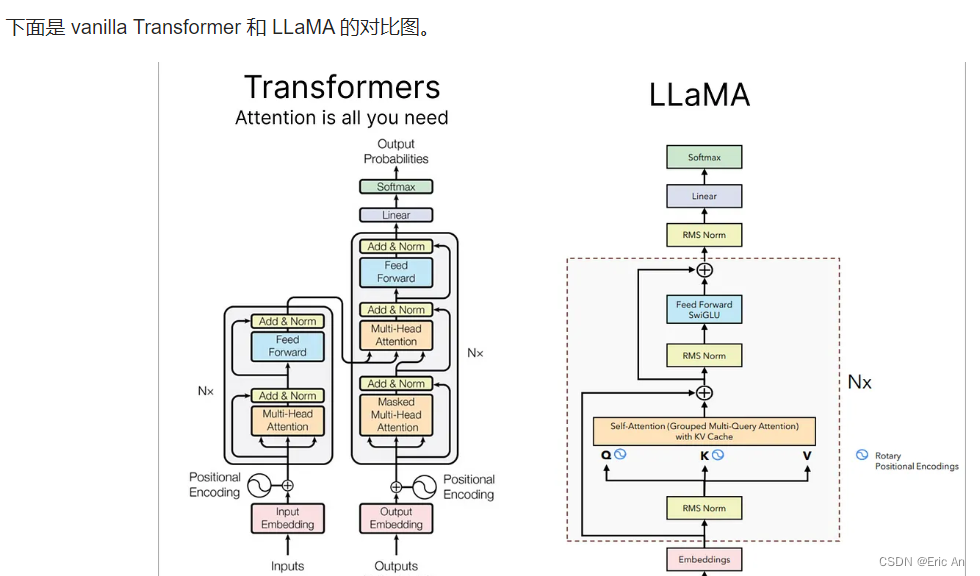
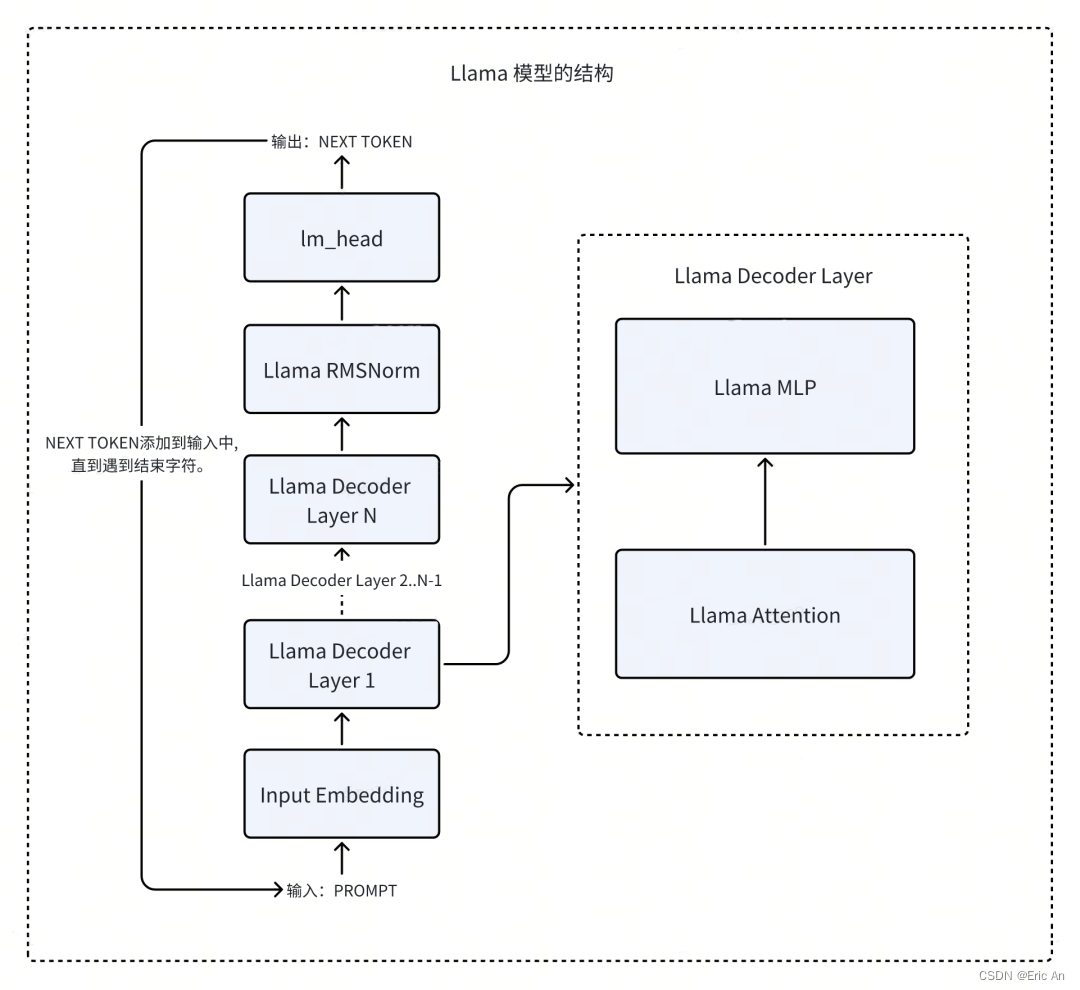
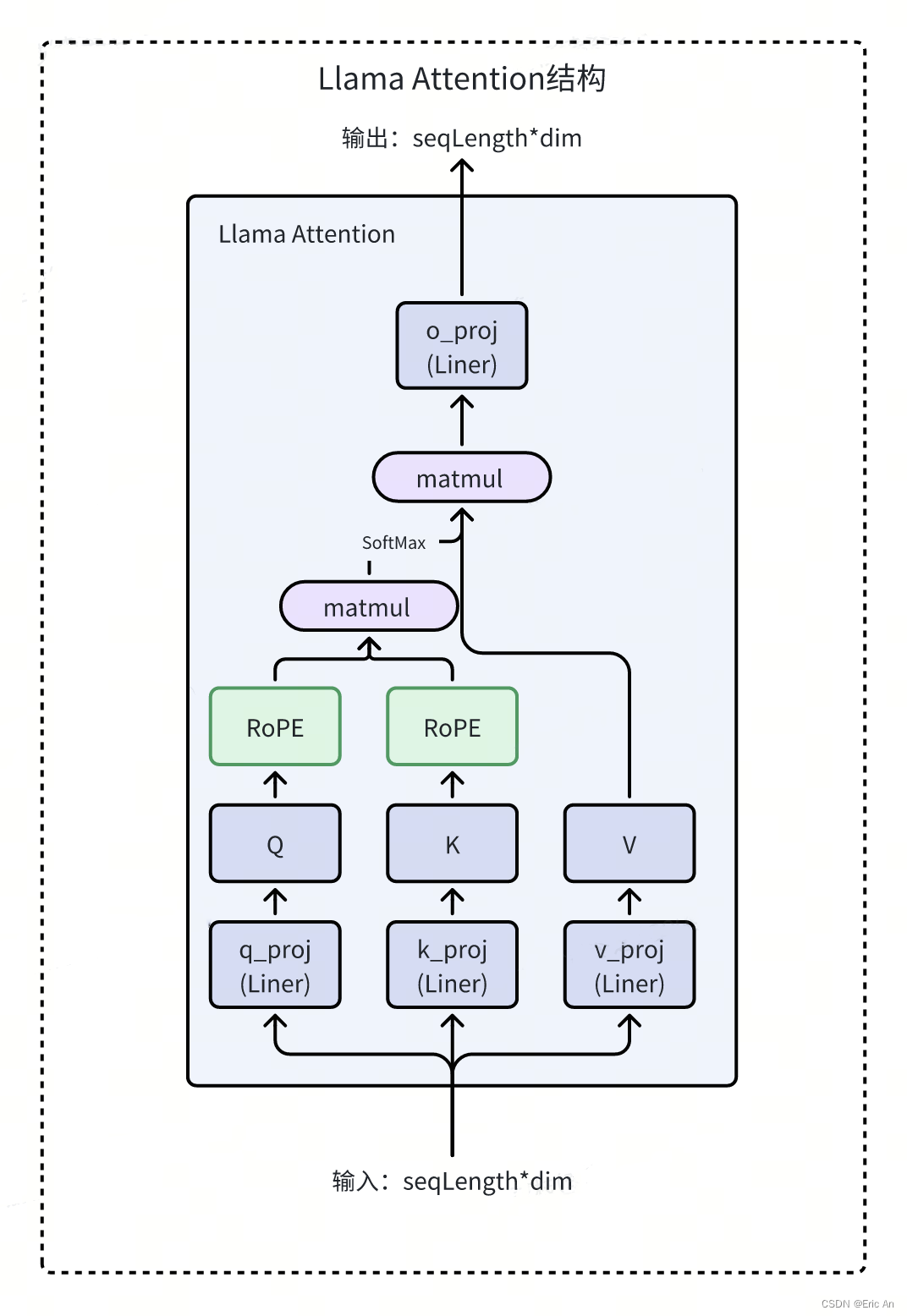
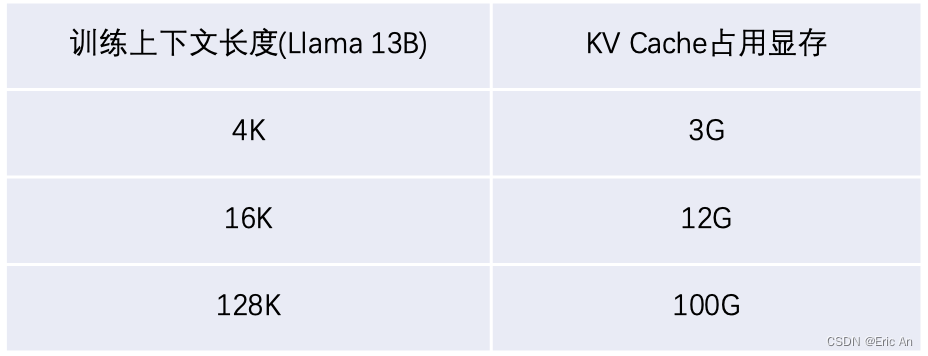
decoder-only类型
LLaMA(Large Language Model AI)在4月18日公布旗下最大模型LLAMA3,参数高达4000亿。现在meta已经开源了80亿和700亿版本模型,重要升级是多模态、长文本方面工作。
模型特点:采用尺度的decoder-only,tokennizer的分词表128k,24K的GPU集群,15T的公开数据,非英占5%,包括30种语言。训练数据增加7倍,代码量增加2倍。
个人理解:按照Sacling low的研究,当参数一定条件下,增加数据量可以明显提示模型的表达能力。而且研究发展在一定条件下增加数据比增加参数在知识表现方面效果更加显著。固然在Scaling low研究中openai和google的观点从文献上看是对立的,这种对立统一大概帮助我们在计划模型时给出一个指导,数据不敷可以通过参加参数提拔效果,数据充足情况下可以通过模型学习SFT,LORA、MOE三种学习范式提拔效果。
LLaMA模型3:
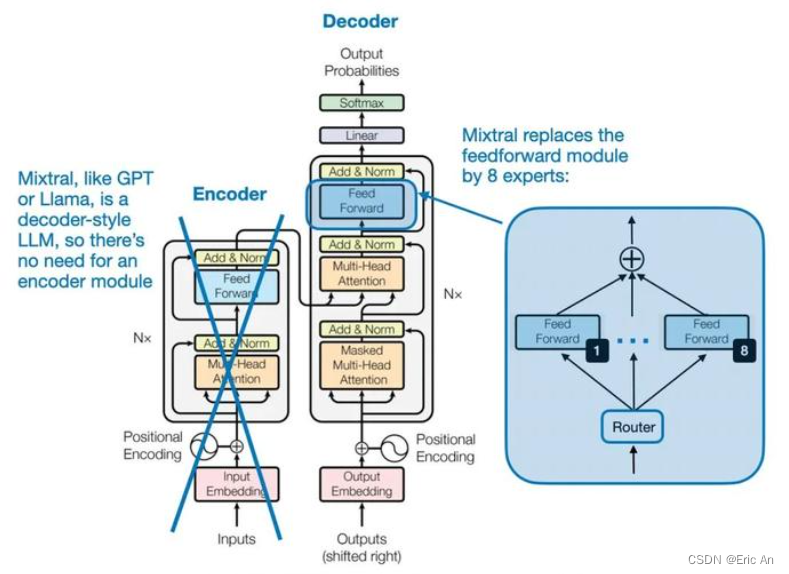
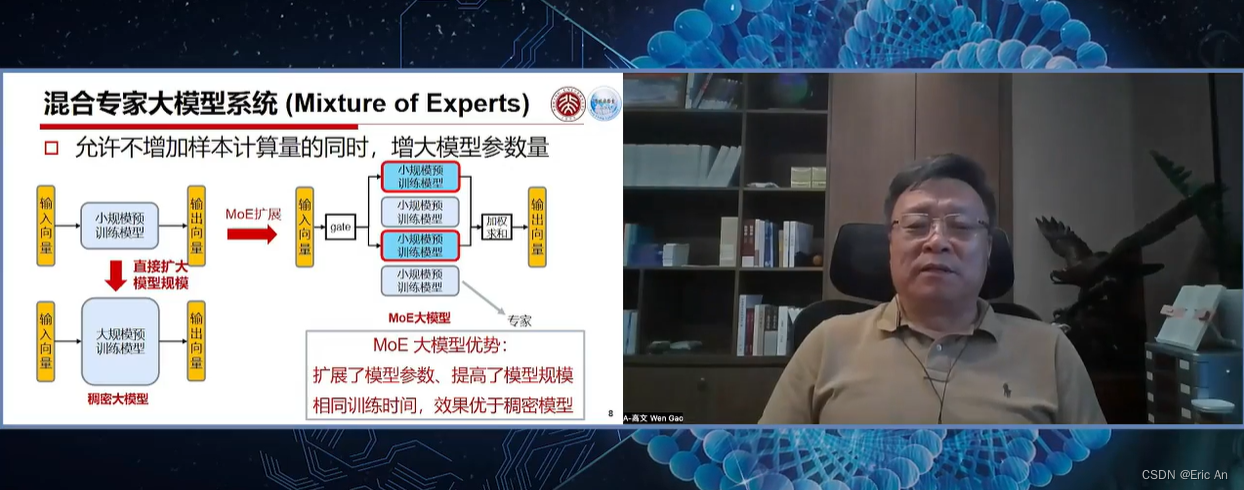
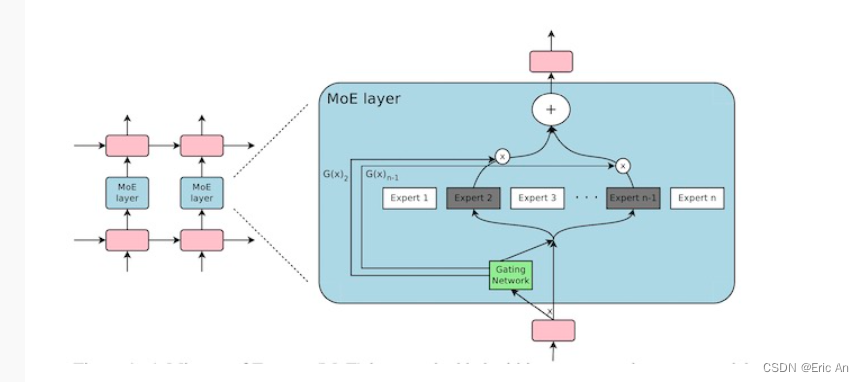
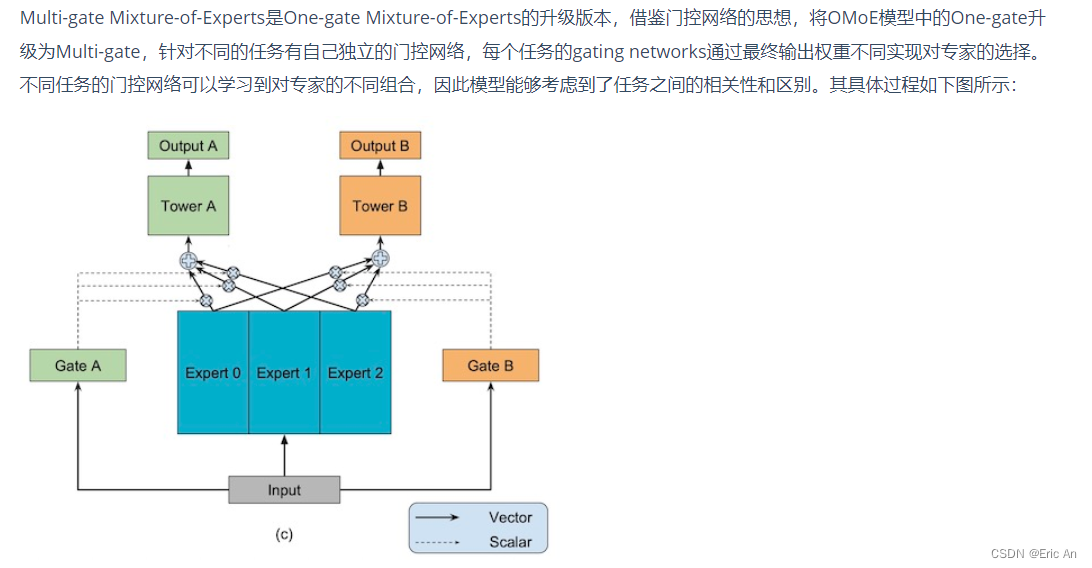
MoE,即Mixture of Experts它允许模型在不同的任务和数据集上进行训练和微调。MoE结构是一种将多个专家网络结合起来,以便处理各种输入的技术。每个专家网络可以专门处理一种类型的任务或数据,而主网络则负责将输入分配给最合适的专家网络。MoE结构的代码简化的MoE结构的概念性伪代码示例原理: