val file = env.readTextFile("/data").withParameters(parameters)
复制代码
4. readTextFile:读取压缩文件
对于以下压缩范例,不需要指定任何额外的 inputformat 方法,flink 可以自动辨认而且解压。但是,压缩文件可能不会并行读取,可能是顺序读取的,这样可能会影响作业的可伸缩性。
DEFLATE
.deflate
no
GZip
.gz .gzip
no
Bzip2
.bz2
no
XZ
.xz
no
val tuple = in.reduce((x, y) => (x._1, x._2 + y._2))
out.collect(tuple)
}
result.print()
复制代码
7. minBy 和 maxBy
选择具有最小值或最大值的元素
case class User(name: String, id: String)
val text: DataSet[User] = textDataSet.mapPartition(line => {
line.map(index => User(index._1, index._2))
})
val result = text
.groupBy(0)
.minBy(1)
复制代码
8. Aggregate
在数据集上进行聚合求最值(最大值、最小值)
val data = new mutable.MutableList[(Int, String, Double)]
data.+=((1, "yuwen", 89.0))
data.+=((2, "shuxue", 92.2))
data.+=((3, "yuwen", 89.99))
val input: DataSet[(Int, String, Double)] = env.fromCollection(data)
val value = input.groupBy(1)
.aggregate(Aggregations.MAX, 2)
value.print()
复制代码
Aggregate 只能作用于元组上
留意: 要使用 aggregate,只能使用字段索引名或索引名称来进行分组 groupBy(0) ,否则会报一下错误: Exception in thread “main” java.lang.UnsupportedOperationException: Aggregate does not support grouping with KeySelector functions, yet. 9. distinct
去除重复的数据
val value: DataSet[(Int, String, Double)] = input.distinct(1)
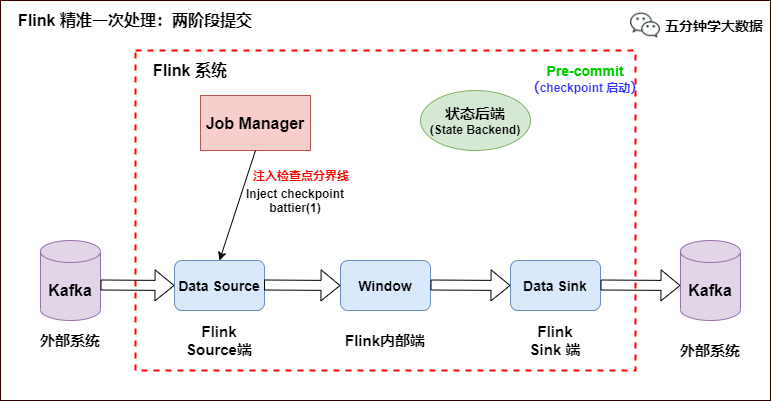
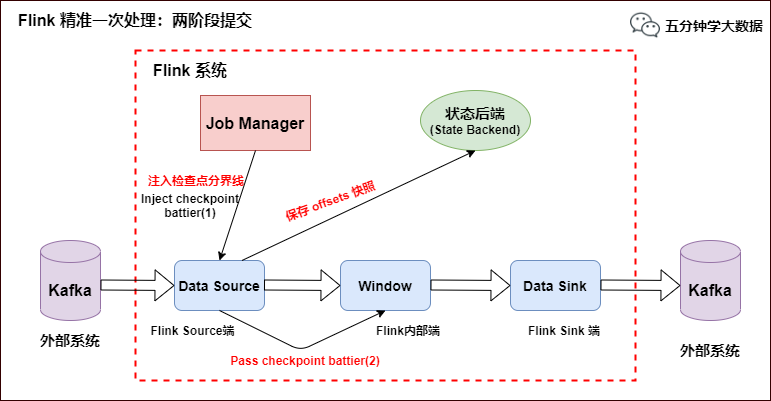
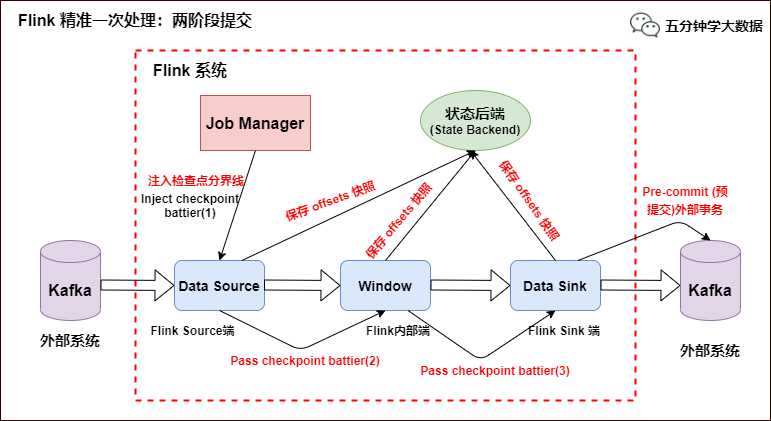
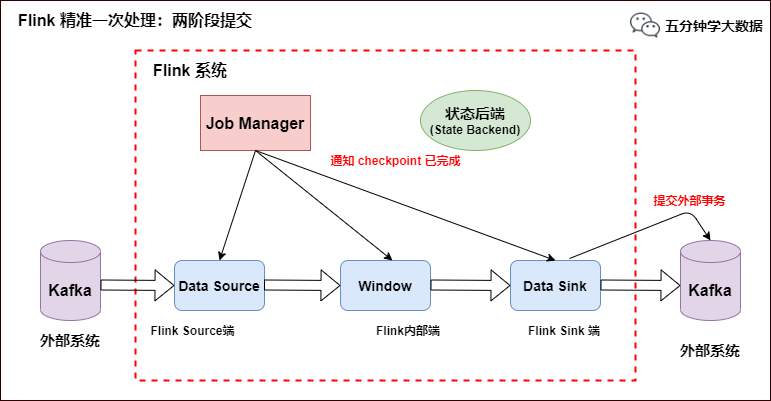
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1) env.getCheckpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION) val text = env.socketTextStream("node01", 9001, '\n') val topic = "test" val prop = new Properties() prop.setProperty("bootstrap.servers", "node01:9092") prop.setProperty("transaction.timeout.ms",60000*15+""); val myProducer = new FlinkKafkaProducer011[String](topic, new KeyedSerializationSchemaWrapper[String](new SimpleStringSchema), prop, FlinkKafkaProducer011.Semantic.EXACTLY_ONCE); text.addSink(myProducer) env.execute("StreamingKafkaSinkScala") }}
复制代码
Redis 实现 End-to-End Exactly-Once 语义:
代码开发步骤:
获取流处理惩罚实行环境
设置查抄点机制
界说 kafkaConsumer
数据转换:分组,求和
数据写入 redis
触发实行
object ExactlyRedisSink { def main(args: Array[String]): Unit = { val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment env.setParallelism(1) env.enableCheckpointing(5000) env.setStateBackend(new FsStateBackend("hdfs://node01:8020/check/11")) env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE) env.getCheckpointConfig.setCheckpointTimeout(60000)
env.getCheckpointConfig.setFailOnCheckpointingErrors(false) env.getCheckpointConfig.setMaxConcurrentCheckpoints(1) env.getCheckpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION) val properties = new Properties() properties.setProperty("bootstrap.servers", "node01:9092,node02:9092,node03:9092") properties.setProperty("group.id", "test") properties.setProperty("enable.auto.commit", "false") val kafkaConsumer = new FlinkKafkaConsumer011[String]("test2", new SimpleStringSchema(), properties) kafkaConsumer.setStartFromLatest() kafkaConsumer.setCommitOffsetsOnCheckpoints(true) val kafkaSource: DataStream[String] = env.addSource(kafkaConsumer) val sumData: DataStream[(String, Int)] = kafkaSource.flatMap(_.split(" ")) .map(_ -> 1) .keyBy(0) .sum(1) val set = new util.HashSet[InetSocketAddress]() set.add(new InetSocketAddress(InetAddress.getByName("node01"),7001)) set.add(new InetSocketAddress(InetAddress.getByName("node01"),7002)) set.add(new InetSocketAddress(InetAddress.getByName("node01"),7003)) val config: FlinkJedisClusterConfig = new FlinkJedisClusterConfig.Builder() .setNodes(set) .setMaxIdle(5) .setMaxTotal(10) .setMinIdle(5) .setTimeout(10) .build() sumData.addSink(new RedisSink(config,new MyRedisSink)) env.execute() }}class MyRedisSink extends RedisMapper[(String,Int)] { override def getCommandDescription: RedisCommandDescription = { new RedisCommandDescription(RedisCommand.HSET,"resink") } override def getKeyFromData(data: (String, Int)): String = { data._1 } override def getValueFromData(data: (String, Int)): String = { data._2.toString }}
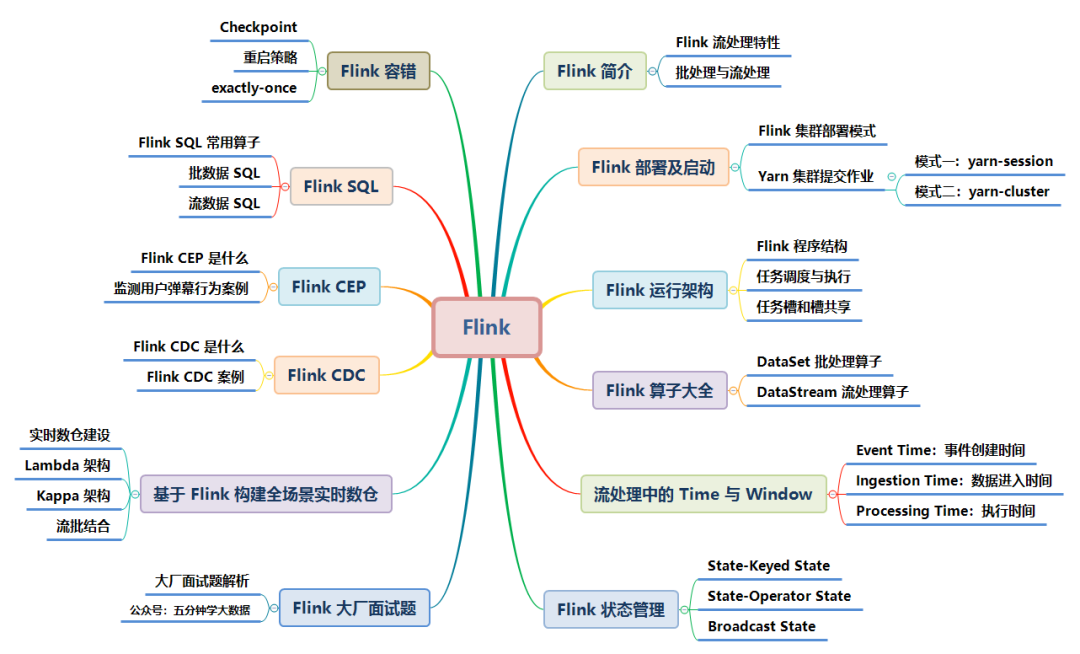
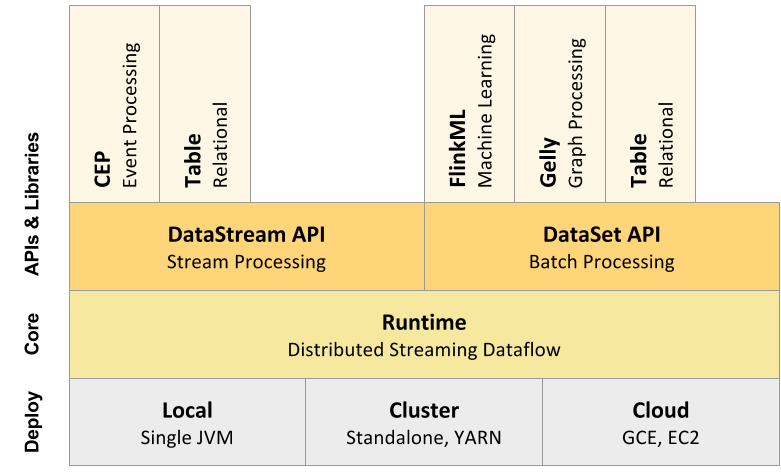
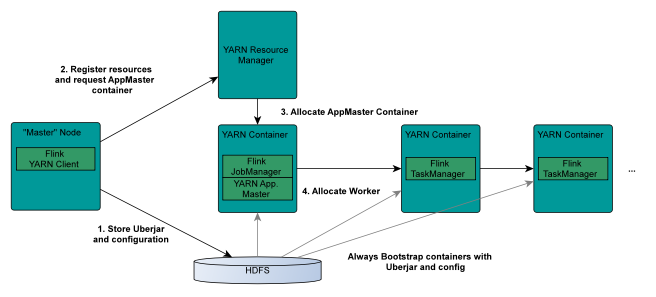
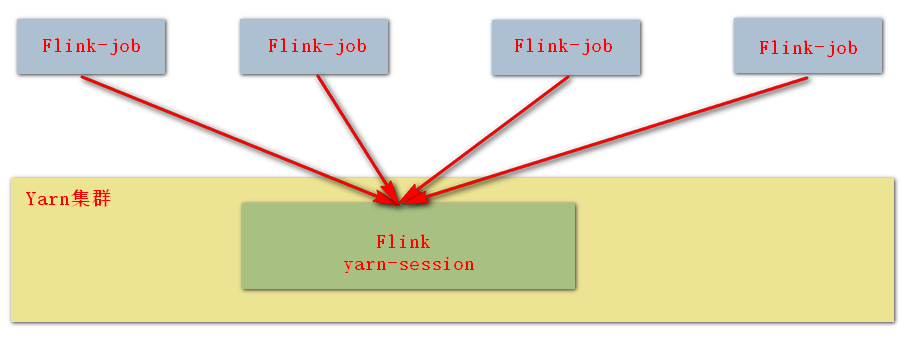
流与批的统一,Flink 底层 Runtime 自己就是一个流与批统一的引擎,而 SQL 可以做到 API 层的流与批统一。
1. Flink SQL 常用算子
SELECT:
SELECT 用于从 DataSet/DataStream 中选择数据,用于筛选出某些列。
示例:
SELECT * FROM Table; // 取出表中的所有列
SELECT name,age FROM Table; // 取出表中 name 和 age 两列
与此同时 SELECT 语句中可以使用函数和别名,例如我们上面提到的 WordCount 中:
SELECT word, COUNT(word) FROM table GROUP BY word; WHERE:
WHERE 用于从数据集 / 流中过滤数据,与 SELECT 一起使用,用于根据某些条件对关系做程度分割,即选择符合条件的记载。
示例:
SELECT name,age FROM Table where name LIKE ‘% 小明 %’;
SELECT * FROM Table WHERE age = 20;
WHERE 是从原数据中进行过滤,那么在 WHERE 条件中,Flink SQL 同样支持 =、<、>、<>、>=、<=,以及 AND、OR 等表达式的组合,终极满足过滤条件的数据会被选择出来。而且 WHERE 可以团结 IN、NOT IN 团结使用。举个例子:
SELECT name, age
FROM Table
WHERE name IN (SELECT name FROM Table2)
复制代码
DISTINCT:
DISTINCT 用于从数据集 / 流中去重根据 SELECT 的结果进行去重。
示例:
SELECT DISTINCT name FROM Table;
对于流式查询,计算查询结果所需的 State 可能会无限增长,用户需要自己控制查询的状态范围,以防止状态过大。 GROUP BY:
GROUP BY 是对数据进行分组操作。例如我们需要计算结果明细表中,每个学生的总分。
示例:
SELECT name, SUM(score) as TotalScore FROM Table GROUP BY name; UNION 和 UNION ALL:
UNION 用于将两个结果集归并起来,要求两个结果集字段完全同等,包括字段范例、字段顺序。不同于 UNION ALL 的是,UNION 会对结果数据去重。
示例:
SELECT * FROM T1 UNION (ALL) SELECT * FROM T2; JOIN:
JOIN 用于把来自两个表的数据团结起来形成结果表,Flink 支持的 JOIN 范例包括:
JOIN - INNER JOIN
LEFT JOIN - LEFT OUTER JOIN
RIGHT JOIN - RIGHT OUTER JOIN
FULL JOIN - FULL OUTER JOIN
这里的 JOIN 的语义和我们在关系型数据库中使用的 JOIN 语义同等。
示例:
JOIN(将订单表数据和商品表进行关联)
SELECT * FROM Orders INNER JOIN Product ON Orders.productId = Product.id
LEFT JOIN 与 JOIN 的区别是当右表没有与左边相 JOIN 的数据时候,右边对应的字段补 NULL 输出,RIGHT JOIN 相当于 LEFT JOIN 左右两个表交互一下位置。FULL JOIN 相当于 RIGHT JOIN 和 LEFT JOIN 之后进行 UNION ALL 操作。
示例:
SELECT * FROM Orders LEFT JOIN Product ON Orders.productId = Product.id
SELECT * FROM Orders RIGHT JOIN Product ON Orders.productId = Product.id
SELECT * FROM Orders FULL OUTER JOIN Product ON Orders.productId = Product.id
Flink CEP 是一个基于 Flink 的复杂事件处理惩罚库,可以从多个数据流中发现复杂事件,辨认有意义的事件(例如机会或者威胁),并尽快的做出响应,而不是需要等待几天或则几个月相当长的时间,才发现问题。 2. Flink CEP API
CEP API 的核心是 Pattern(模式) API,它答应你快速界说复杂的事件模式。每个模式包含多个阶段(stage)或者我们也可称为状态(state)。从一个状态切换到另一个状态,用户可以指定条件,这些条件可以作用在邻近的事件或独立事件上。
先容 API 之前先来理解几个概念: 1) 模式与模式序列