ToB企服应用市场:ToB评测及商务社交产业平台
标题:
LLaMA-Factory参数的解答
[打印本页]
作者:
熊熊出没
时间:
2024-7-17 15:43
标题:
LLaMA-Factory参数的解答
最新的文章已更新,可以去专栏查找一下
专栏地址:https://blog.csdn.net/m0_69655483/category_12492160.html?spm=1001.2014.3001.5482
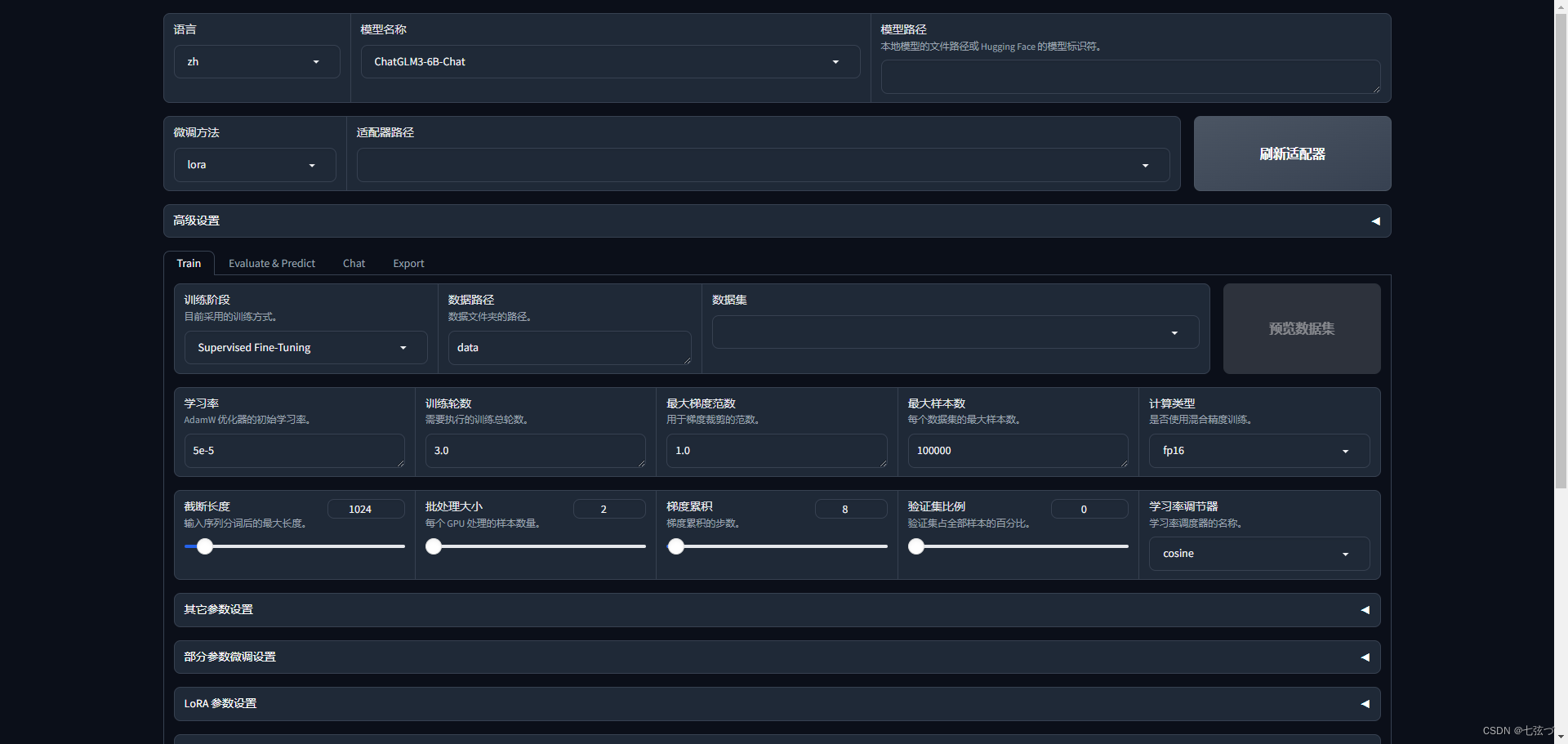
打开LLaMA-Factory的web页面会有一堆参数 ,但不知道怎么选,选哪个,这个文章具体解读一下,每个参数到底是什么寄义
这是个人写的参数解读,我并非该领域的人如果谁人大佬看到有参数不对请反馈一下,或者有补充的也可以!谢谢(后续该文章可能会持续更新)
LLaMA-Factory项目的地址:https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md
微调方法
Full Fine-Tuning(全模型微调)
:
在全模型微调中,将整个预练习模型的参数都解冻,并将它们一起随着新数据的练习而更新。这意味着全部层的权重都将被调解以顺应新任务,这种方法通常需要较大的数据集和计算资源,但在某些情况下可以取得很好的效果。
Freeze Fine-Tuning(冻结层微调)
:
冻结层微调是指在开始微调时保持一些或全部的预练习模型层权重不变。这些被冻结的层将不会在练习过程中更新其权重,只有新添加的层或解冻的层会进行练习。这种方法可以在新任务数据较少时利用,以防止在练习初期过度拟合。
LOFA (Layers Freezing) Fine-Tuning(层冻结微调)
:
LOFA微调是一种介于全模型微调和冻结层微调之间的方法。它答应对模型的不同部门接纳不同的微调策略,即一部门层被冻结而另一部门层被解冻并进行微调。通过根据任务特点选择性地解冻部门层,可以在保留预练习模型部门知识的同时让模型更容易顺应新任务。
练习阶段
Supervised Fine-Tuning(监督微调):
这是一种常见的微调方法,通过将预练习模型应用于新任务并利用有标签数据来微调模型,以优化特定任务的性能。
Reward Modeling(嘉奖建模)
:
这是一种用于强化学习(Reinforcement Learning)的方法,通过界说嘉奖函数来引导智能体学习目标动作或策略。
PPO(Proximal Policy Optimization):
PPO是一种用于练习强化学习模型的优化算法,旨在提高练习效率并实现稳固性。
DPO(Differential Privacy Optimization):
DPO是一种优化算法,用于保护数据隐私,并确保在模型练习过程中不会走漏敏感信息。
Pre-Training(预练习):
预练习是指在目标任务上之进步行的练习,通常利用大型数据集和无标签数据以提取更普适的特性,便于迁移学习或微调到特定任务。
AdamW优化器中的学习率
AdamW优化器中的学习率(learning rate)是控告制模型参数更新步长的超参数。学习率决定了在每次参数更新时权重应该调解的幅度,从而影响模型在练习过程中的收敛速度和最终性能。
在AdamW优化器中,学习率是一个紧张的超参数,通常初始化为一个较小的值,它可以随着练习的进行而动态调解。选择符合的学习率有助于制止模型陷入局部最优解或发散,同时还可以提高模型的泛化能力。
调解学习率的过程通常会在练习过程中进行,可能会利用学习率衰减策略(比方指数衰减、余弦退火等)来渐渐减小学习率,以便模型更好地探索损失函数的空间并得到更好的收敛性能。
因此,在AdamW优化器中,学习率是一项关键的超参数,需要仔细选择和调解以确保模型得到良好的收敛性能和最终表现。
学习率参数有那些(这些只是参考)
5e-5:
这个学习率适合于相对较大的数据集或复杂的模型,因为较大的学习率可以更快地收敛,尤其是当练习数据为大规模数据集时。
1e-6
:较小的学习率适用于数据集较小或相对简朴的模型,可以资助模型更稳固地学习数据的模式,制止过度拟合。
1e-3
:适用于快速收敛,通常用于较大的深度神经网络和大型数据集。
1e−4
:适用于中等巨细的数据集和相对简朴的模型。
5e−4
:类似于1e-3和1e-4之间的学习率,适用于中等巨细的网络和数据集。
1e−5
:适用于相对小型的数据集或简朴的模型,有助于制止快速过拟合。
1e−7
:适用于非常小的数据集或非常简朴的模型,有助于更细致地调解参数。
最大梯度范围
最大梯度范数用于对梯度进行裁剪,限制梯度的巨细,以防止梯度爆炸(梯度过大)的问题。选择符合的最大梯度范数取决于您的模型、数据集以及练习过程中碰到的情况。
一样平常来说,常见的最大梯度范数取值在1到5之间,但具体取值要根据您的模型布局和练习数据的情况进行调解。以下是一些常见的最大梯度范数取值建议:
1到5之间
:这是一样平常情况下常见的范围。如果您的模型较深或者碰到梯度爆炸的情况,可以思量选择较小的范围。
1
:通常用于对梯度进行相对较小的裁剪,以制止梯度更新过大,特殊适用于练习稳固性较差的模型。
3到5
:用于对梯度进行中等水平的裁剪,适用于一样平常深度学习模型的练习。
更大值
:对于某些情况,比方对抗练习(Adversarial Training),可能需要更大的最大梯度范数来维持梯度的稳固性。
选择最大梯度范数时,建议根据实际情况进行试验和调解,在练习过程中观察模型的表现并根据需要进行调解。但通常情况下,一个合理的初始范围在1到5之间可以作为起点进行实验。
计算类型
在深度学习中,计算类型可以指定模型练习时所利用的精度。常见的计算类型包括:
FP16 (Half Precision)
:FP16是指利用16位浮点数进行计算,也称为半精度计算。在FP16精度下,模型参数和梯度都以16位浮点数进行存储和计算。
BF16 (BFloat16)
:BF16是指利用十六位Brain Floating Point格式,与FP16不同之处在于BF16在指数部门有8位(与FP32相同),而FP16只有5位。BF16通常用于机器学习任务中,尤其是在加快器中更为常见。
FP32 (Single Precision)
:FP32是指利用32位浮点数进行计算,也称为单精度计算。在FP32精度下,模型参数和梯度以32位浮点数进行存储和计算,是最常见的精度。
Pure BF16
:这是指纯粹利用BF16进行计算的模式。
在深度学习练习中,利用更低精度(比方FP16或BF16)可以降低模型的内存和计算需求,加快练习速度,尤其对于大规模模型和大数据集是有益的。然而,较低精度也可能带来数值稳固性问题,特殊是在练习过程中需要小心处理梯度的表达范围,制止梯度消散或爆炸的问题。
选择何种计算类型通常取决于您的硬件支持、练习需求和模型性能。不同精度的计算类型在模型练习过程中会对练习速度、内存斲丧和模型性能产生影响,因此需要根据具体情况进行权衡和选择。
学习率调节器
Linear
:线性衰减学习率,即学习率随着练习步数线性减小。
Cosine
:余弦退火学习率,学习率按照余弦函数的曲线进行调解,渐渐降低而非直接线性减小。
Cosine with restarts
:带重启的余弦退火,学习率的衰减呈现周期性变化,适用于练习过程中逐步放宽约束然后再次加快练习的情况。
Polynomial
:多项式衰减学习率,通过多项式函数来调解学习率,可以是二次、三次等。
Constant
:固定学习率,不随练习步数变化而保持不变。
Constant with warmup
:具有热身阶段的固定学习率,初始阶段固定学习率较大,随后在练习一段时间后降低。
Inverse Square Root
:学习率按照步数的倒数的平方根进行衰减,可以平滑地调解学习率。
Reduce Learning Rate on Plateau
:当验证集上的损失不再减少时,减小学习率,以更细致地优化模型性能。
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/)
Powered by Discuz! X3.4