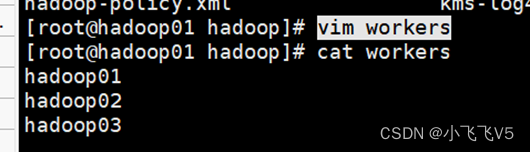
同样通过mobaxterm的上的SFTP功能(或其他工具)上传到/export/software目录下,然后解压到/export/servers目录下
cd /export/software
mobaxterm的上的SFTP功能
tar -zxvf hadoop-3.1.3.tar.gz -C /export/servers/
3. 设置Hadoop体系环境变量
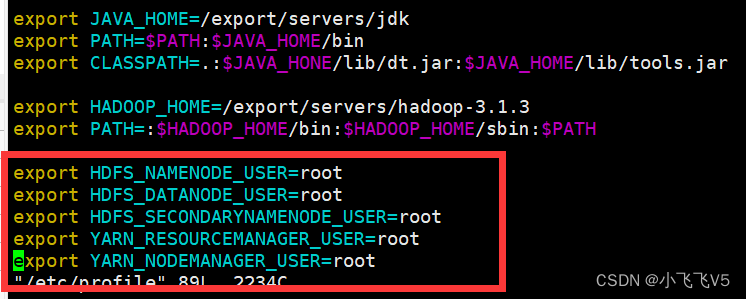
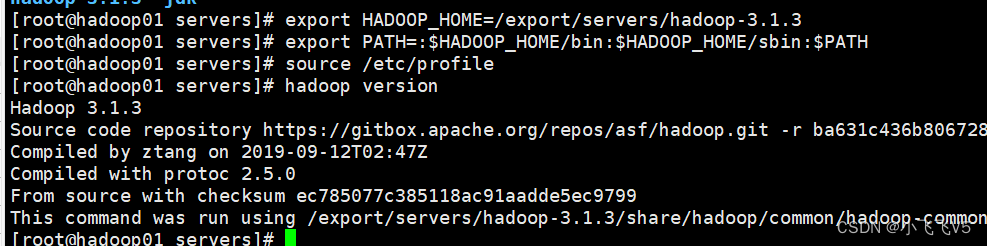
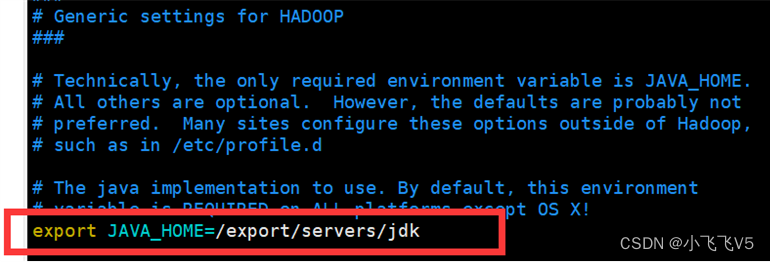
vim /etc/profile
设置环境变量
export HADOOP_HOME=/export/servers/hadoop-3.1.3
export PATH=: H A D O O P _ H O M E / b i n : HADOOP\_HOME/bin: HADOOP_HOME/bin:HADOOP_HOME/sbinPATH
执行该步伐(参考下文中可能碰到的题目,题目1、2为必现题目,建议直接修改)
cd /export/servers/hadoop-3.1.3/share/hadoop/mapreduce
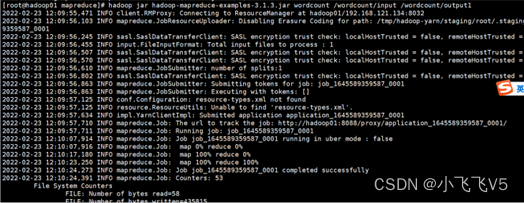
hadoop jar hadoop-mapreduce-examples-3.1.3.jar wordcount /wordcount/input /wordcount/output
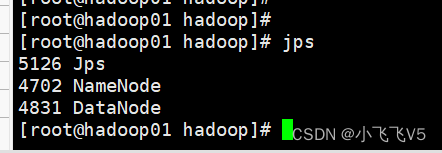
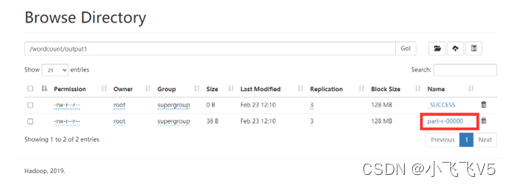
查看结果如下:
注意:
可能碰到的题目1:
找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster 解决方法:
输入 hadoop classpath
复制返回的信息
修改yarn-site.xml
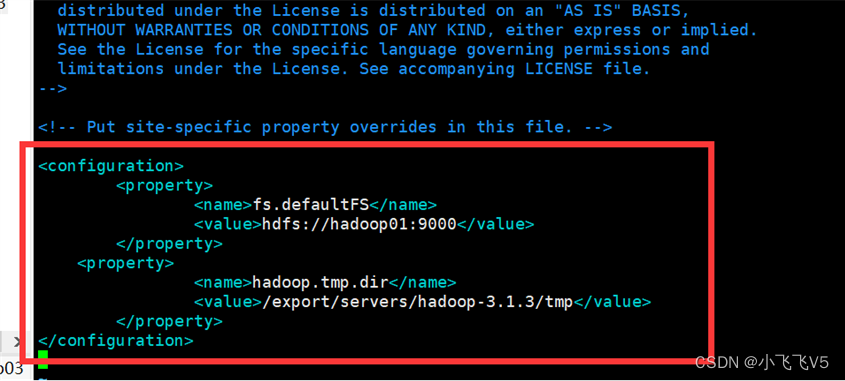
cd /export/servers/hadoop-3.1.3/etc/hadoop
vim yarn-site.xml
新增以下内容
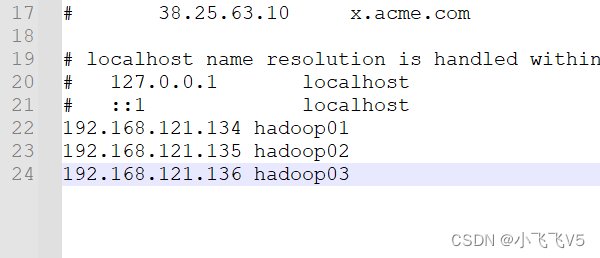
yarn.application.classpath
输入刚才返回的Hadoop classpath路径
可能碰到的题目2:
Container killed on request. Exit code is 143 解决方法:
cd /export/servers/hadoop-3.1.3/etc/hadoop
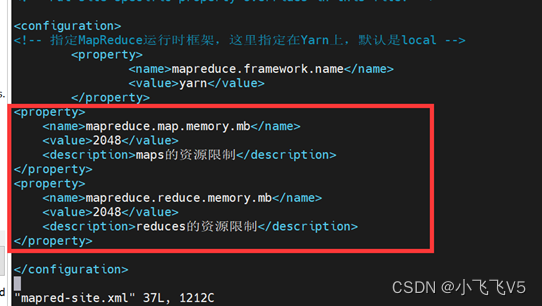
vim mapred-site.xml
mapreduce.map.memory.mb
2048
maps的资源限制
mapreduce.reduce.memory.mb
2048
reduces的资源限制






 PATH
PATH