但此中有个问题是,因为像素的关系,一张图像有着比力大的维度(比如250 x 250),即一张图片上可能有着5万多个元素,如果根据上一张图片的5万多元素去逐一交互下一张图片的5万多个元素,未免工程过于浩大(而且,即便是同一张图片上的5万多个像素点之间两两做self-attention,你都会发现盘算复杂度超级高)
故为低落处理的复杂度,可以类似ViT把一张图像分别为九宫格(如下图的左下角),如此,处理9个图像块总比一次性处理250 x 250个像素维度 要好不少吧(ViT的出现直接挑衅了此前CNN在视觉范畴长达近10年的绝对统治职位,其原理细节详见本文开头提到的此文第4部门)
当我们明白了一张静态图像的patch表示之后(不管是九宫格,还是16 x 9个格),再来明白所谓的时空Patches就简朴多了,无非就是在纵向上加上时间的维度,比如t1 t2 t3 t4 t5 t6
而一个时空patch可能跨3个时间维度,固然,也可能跨5个时间维度
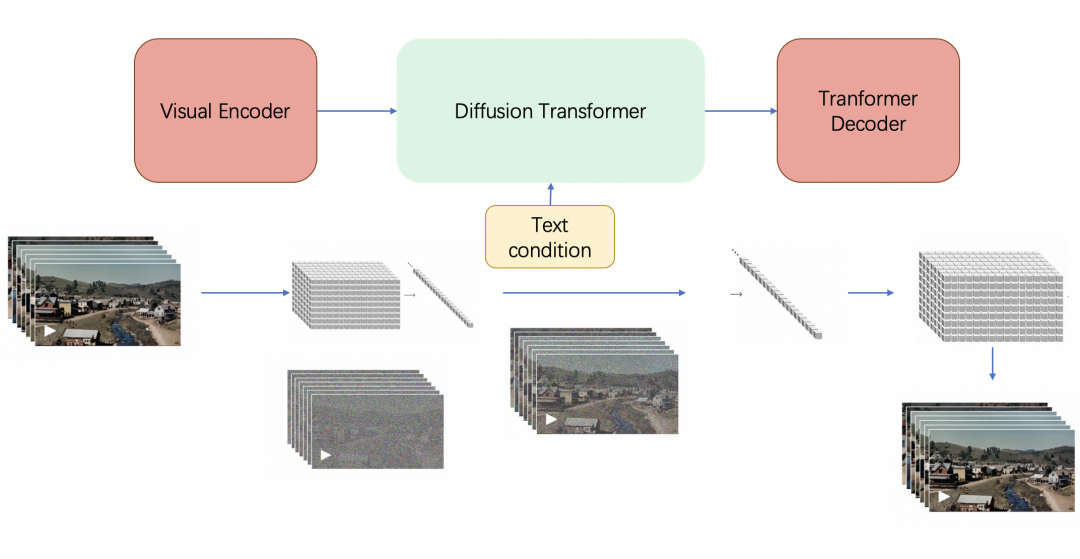
一方面,它类似扩散模子那一套流程,给定输入噪声patches(以及文本提示等调节信息),训练出的模子来预测原始的不带噪声的patches「Sora is a diffusion model, given input noisy patches (and conditioning information like text prompts), it’s trained to predict the original “clean” patches」
类似把视频中的一帧帧画面打上各种马赛克,然后训练一个模子,让它学会去除各种马赛克,且一开始各种失败不要紧,反正有原画面作为ground truth,不断缩小与原画面之间的差异即可
而当把一帧帧图片打上全部马赛克之后,可以根据”文本-视频数据集”中对视频的描述/prompt(注,该描述/prompt不仅仅只是通过CLIP去与视频对齐,还颠末类似DALLE 3所用的重字幕技能加强 + GPT4对字幕的进一步丰富,下节详述),而有条件的去噪
二方面,它把DPPM中的噪声估计器所用的卷积架构U-Net换成了Transformer架构
总之,总的来说,Sora是一个在不同时长、分辨率和宽高比的视频及图像上训练而成的扩散模子,同时采用了Transformer架构,如sora官博所说,Sora is a diffusion transformer,简称DiT
关于DiT的更多细节详见下文第二部门介绍的DiT 1.2 基于DALLE 3的重字幕技能:提拔文本-视频数据质量
与DALLE 3类似,研究团队还利用 GPT 将用户简短的prompt 转换为较长的详细字幕,然后发送给视频模子(Similar to DALL·E 3, we also leverage GPT to turn short user prompts into longer detailed captions that are sent to the video model),这使得 Sora 能够生成正确遵循详细字幕或详细prompt 的高质量视频
业界最早是用卷积那一套处理视频,比如时空3D CNN(Learning spatiotemporal features with 3d convolutional networks),由于3D CNN比图像卷积网络需要较多的盘算量,许多架构在空间和时间维度上进行卷积的因式分解和/或利用分组卷积,且近来,还通过在后续层中引入自留意力来增强模子,以更好地捕捉长程依赖性
2021年的这两篇论文《Is space-time attention all you need for video understanding?》、《Video transformer network》都是基于transformer做视频明白
而Google于2021年5月提出的ViViT(其对应论文为:ViViT: A Video Vision Transformer)便要尝试在视频中利用ViT模子,且他们充分借鉴了之前3D CNN因式分解等工作,比如考虑到视频作为输入会产生大量的时空token,处理时必须考虑这些长范围token序列的上下文关系,同时要兼顾模子效率问题
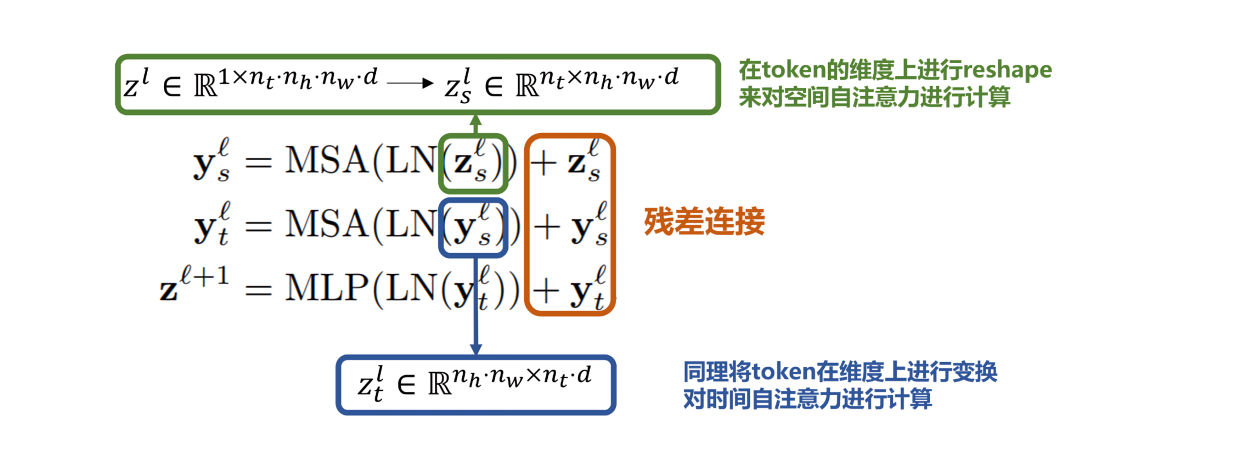
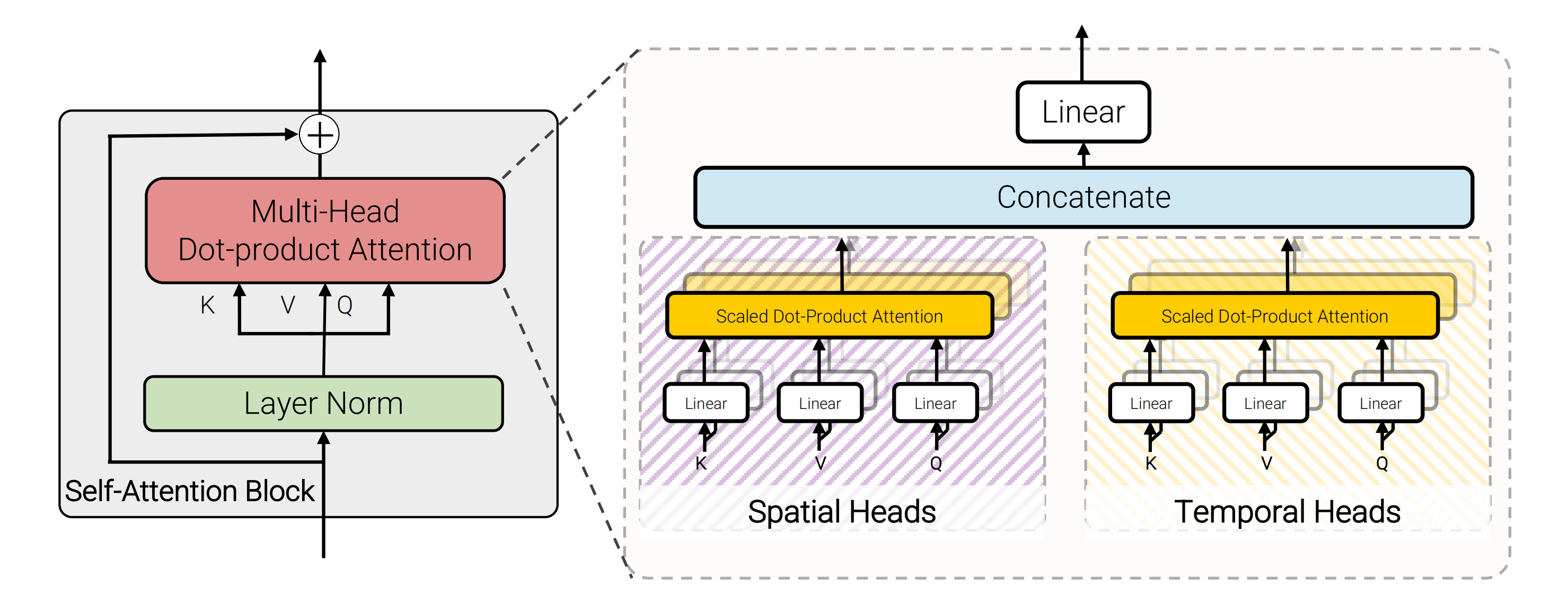
故作者团队在空间和时间维度上分别对Transformer编码器各组件进行分解,在ViT模子的底子上提出了三种用于视频分类的纯Transformer模子,如下图所示
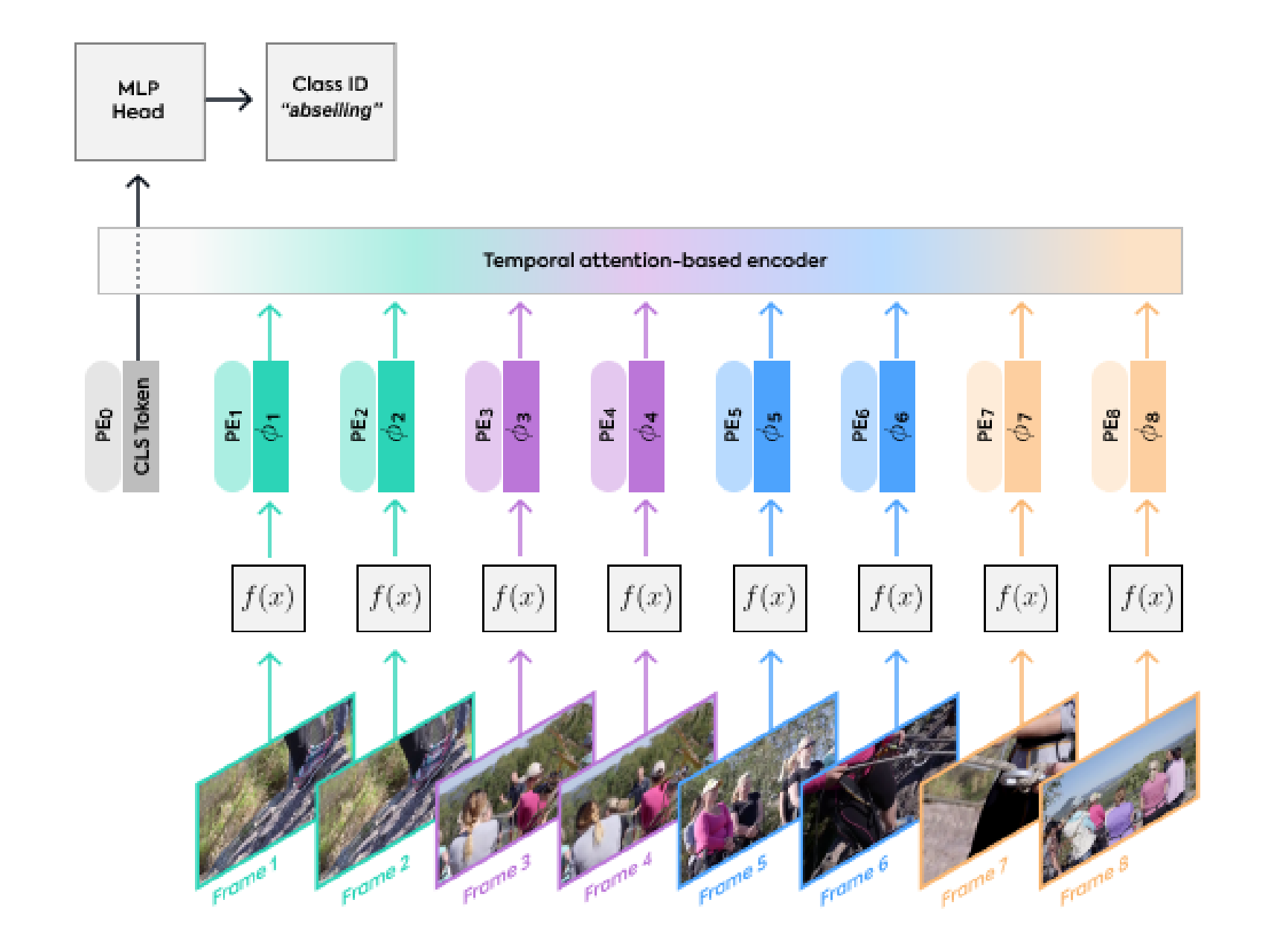
个帧,利用与ViT 相同的方法独立地嵌入每个2D帧(embed each 2D frame independently using the same method as ViT),并将所有这些token连接在一起
具体地说,如果从每个帧中提取
个非重叠图像块(就像 ViT 一样),那么总共将有
个token通过transformer编码器进行传递,这个过程可以被看作是简朴地构建一个大的2D图像,以便按照ViT的方式进行tokenised(这点和本节开头所提到的21年那篇论文space-time attention for video所用的方式一致)
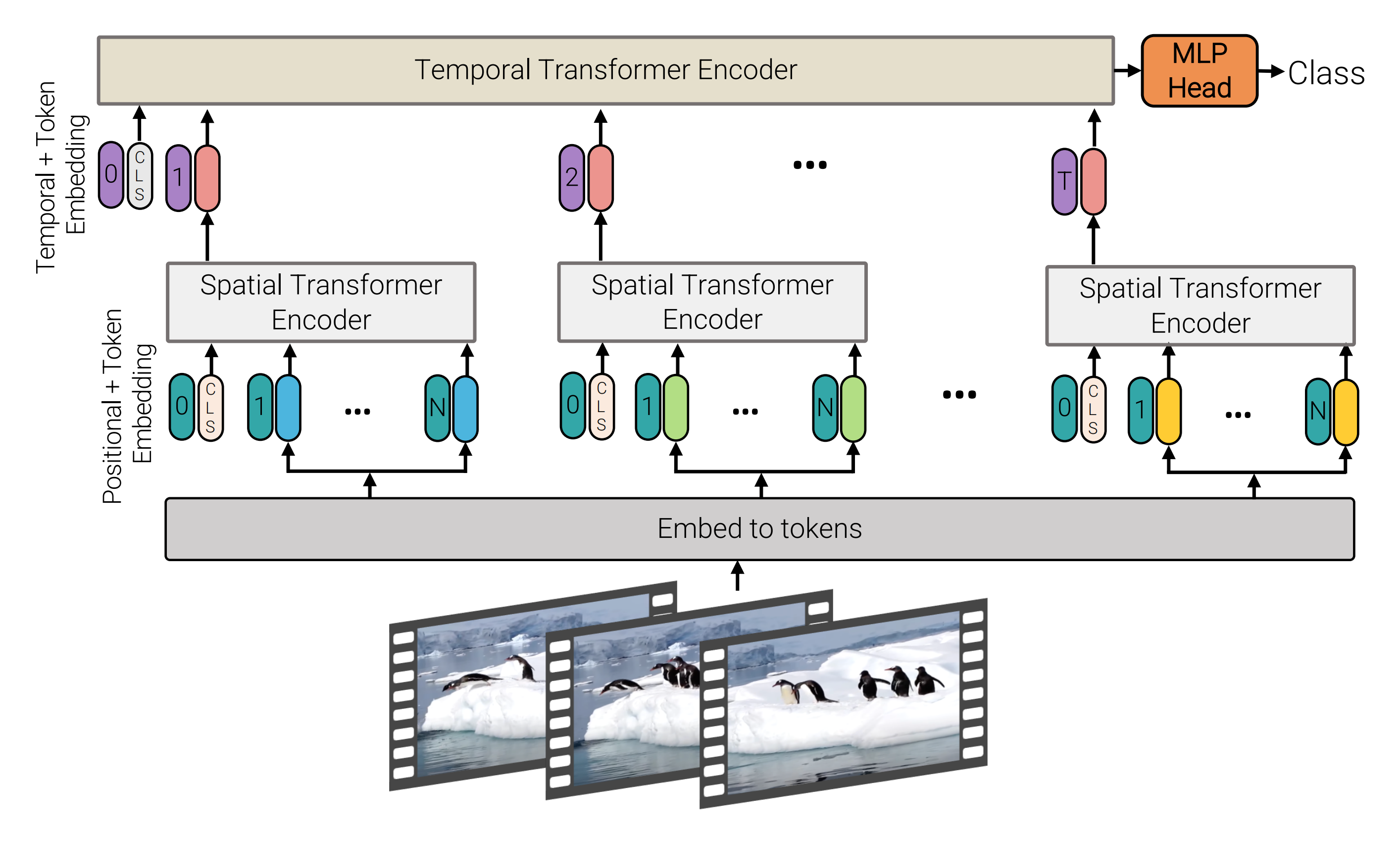
第二种则是把输入的视频分别成多少个tuplet(类似不重叠的带空间-时间维度的立方体)
每个tuplet会变成一个token(因这个tublelt的维度就是: t * h * w,故token包含了时间、宽、高)
颠末spatial temperal attention进行空间和时间建模获得有效的视频表征token