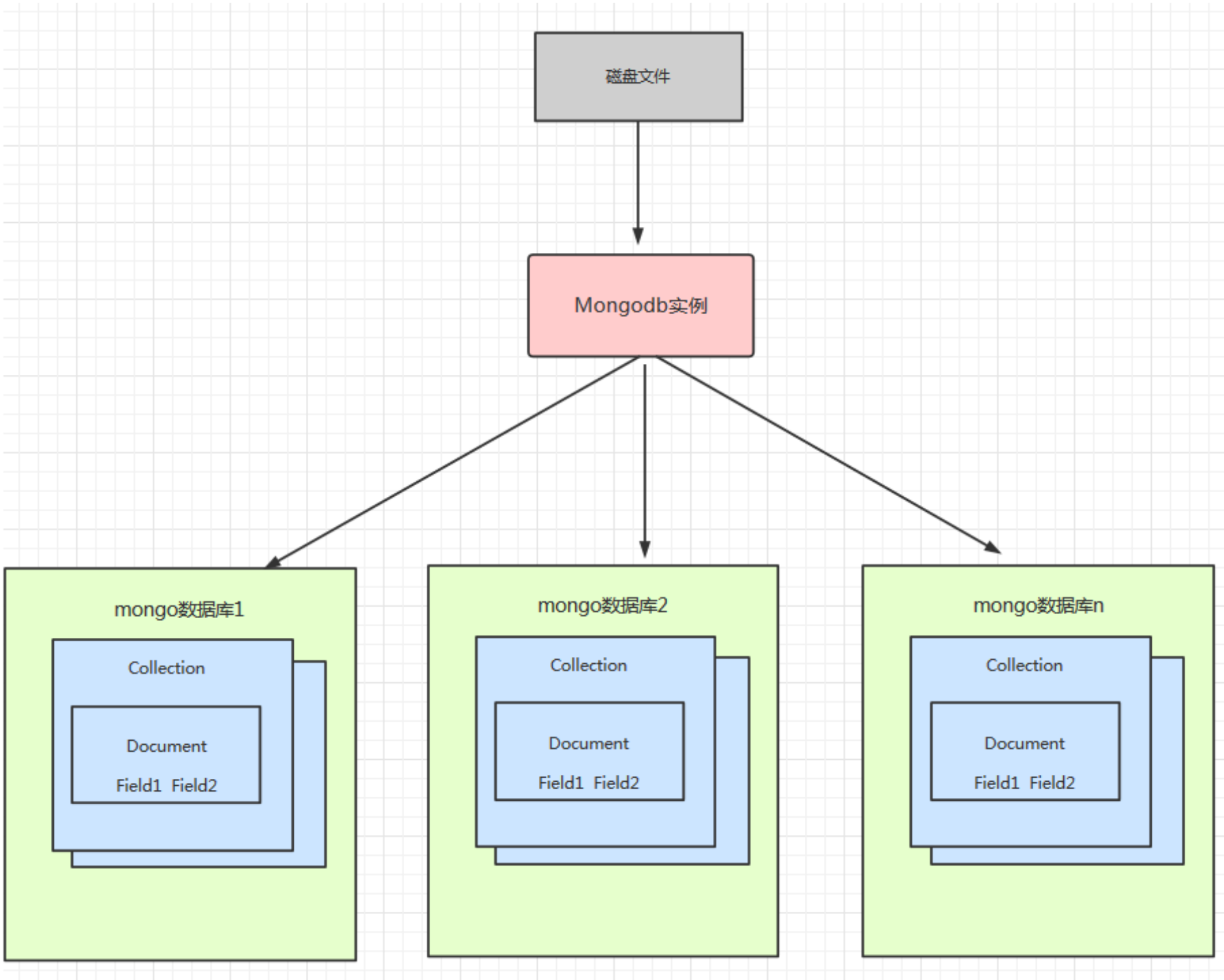
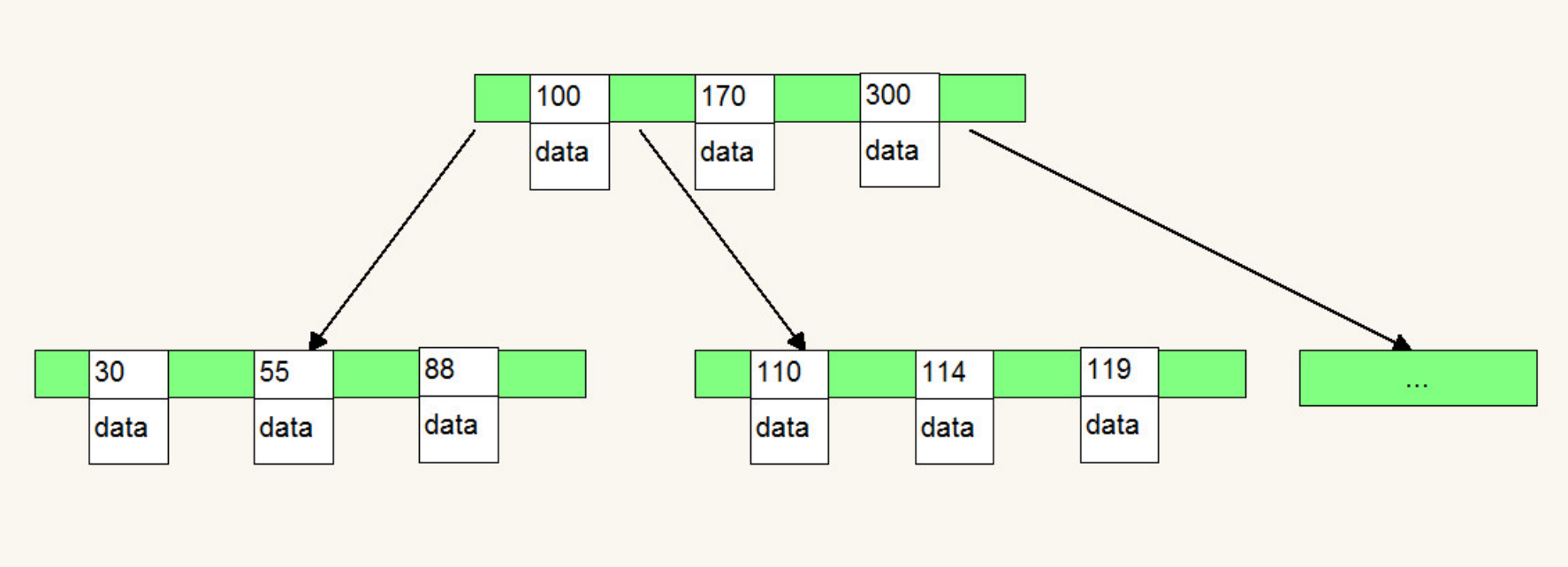
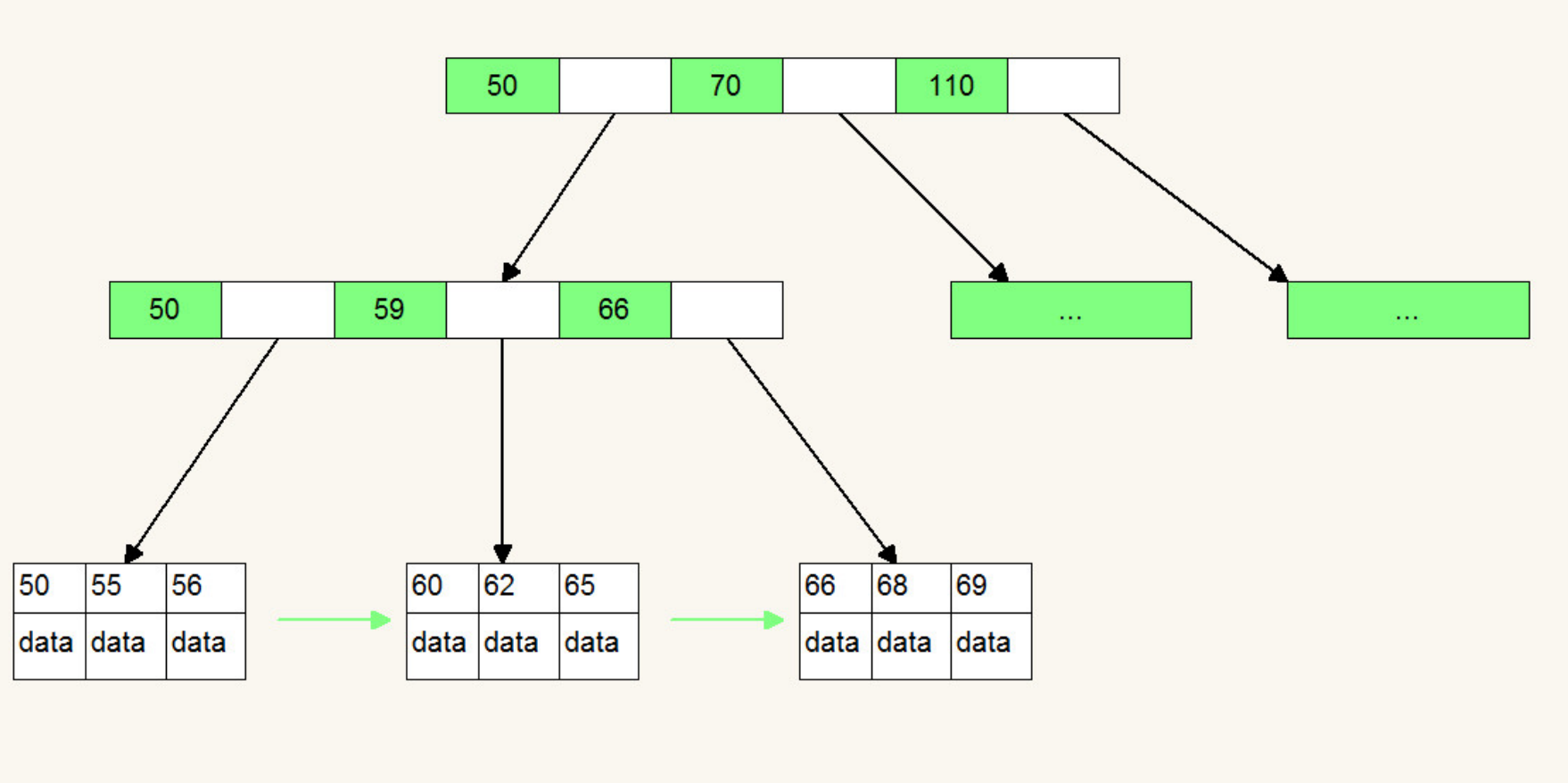
索引是⼀种单独的、物理的对数据库表中⼀列或多列的值进⾏排序的⼀种存储布局,它是某个表中⼀列或若⼲列值的集合和指向这些值数据⻚的逻辑指针清单。
索引⽬标是提⾼数据库的查询服从,没有索引的话,查询会进⾏全表扫描(scan every document in a collection),数据量⼤时严重低落了查询服从。默认环境下Mongo在⼀个集合(collection)创建时,⾃动地对集合的_id创建了唯⼀索引。
3.1 索引范例
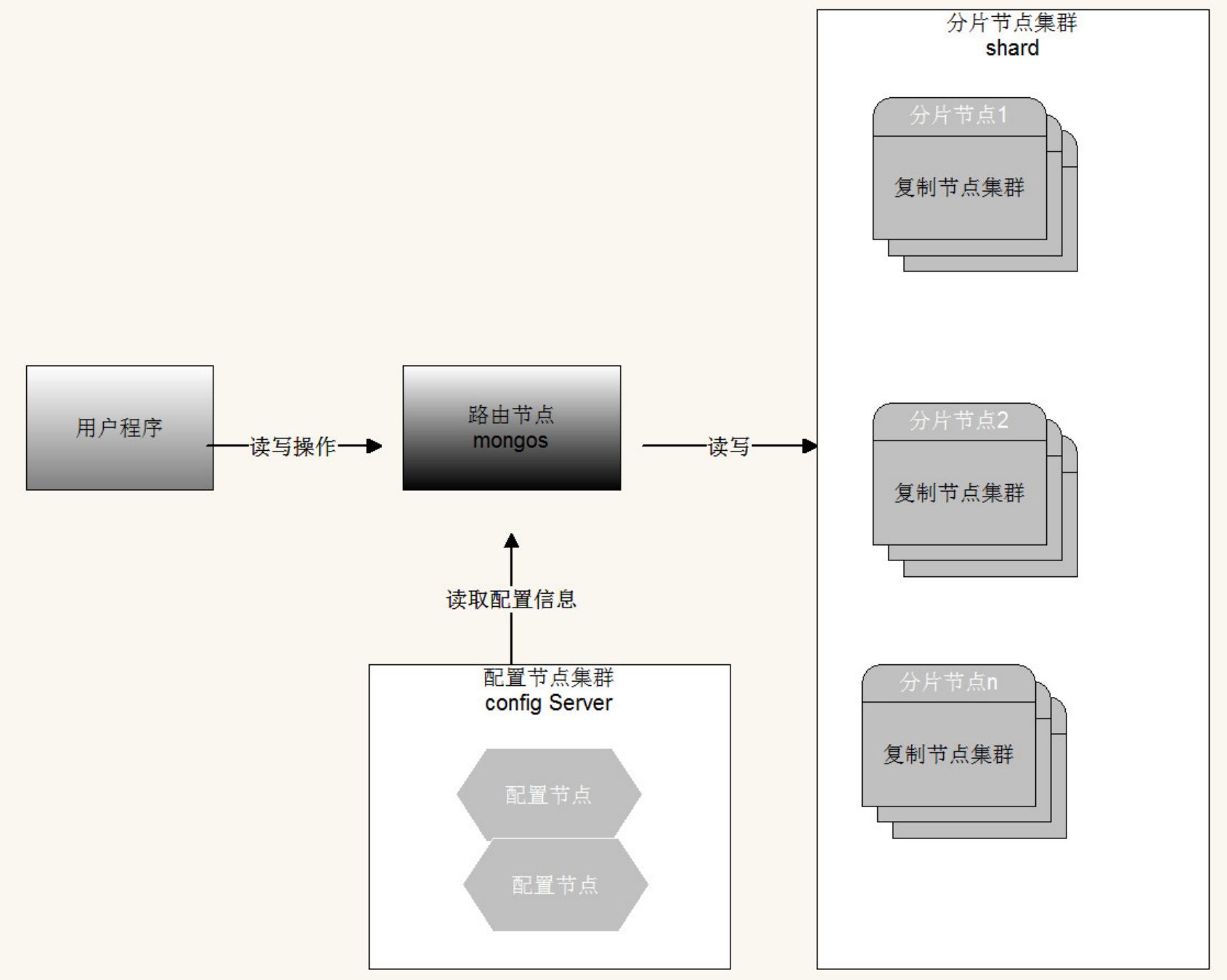
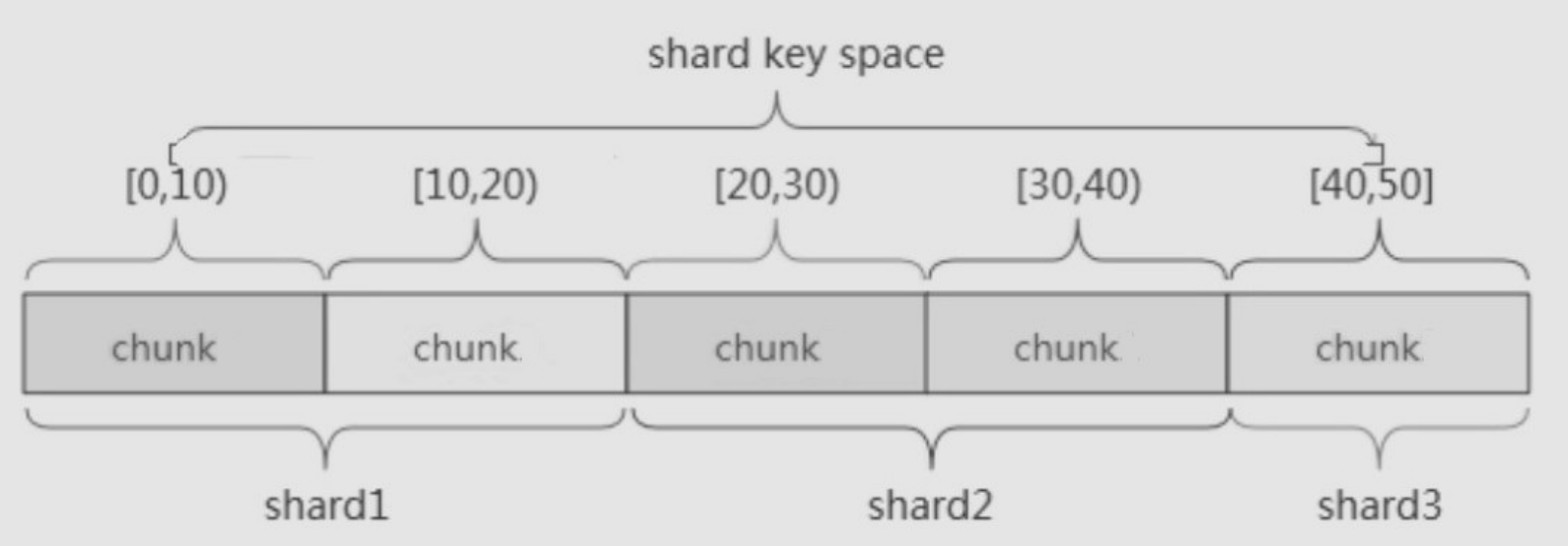
范围分⽚(Range based sharding)
范围分⽚是基于分⽚主键的值切分数据,每⼀个区块将会分配到⼀个范围。
范围分⽚得当满⾜在⼀定范围内的查找,例如查找X的值在[20,30)之间的数据,mongo 路由根据Config server中存储的元数据,可以直接定位到指定的shard的Chunk中。
缺点: 假如shard key有显着递增(或者递减)趋势,则新插⼊的⽂档多会分布到同⼀个chunk,⽆法扩展写的能⼒
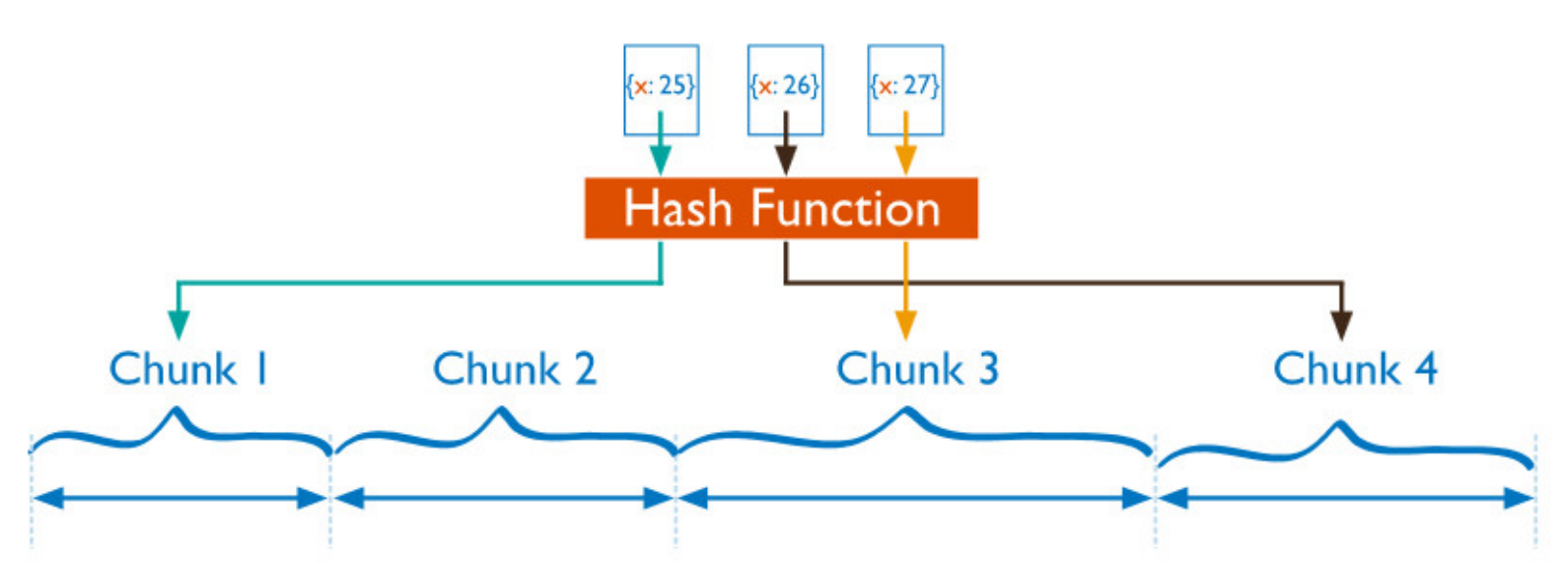
hash分⽚(Hash based sharding)
Hash分⽚是盘算⼀个分⽚主键的hash值,每⼀个区块将分配⼀个范围的hash值。 Hash分⽚与范围分⽚互补,能将⽂档随机的分散到各个chunk,充分的扩展写能⼒,补充了范围分⽚的不⾜,缺点是不能⾼效的服务范围查询,范围查询要分发到后端所有的Shard才能找出满⾜条件的⽂档。