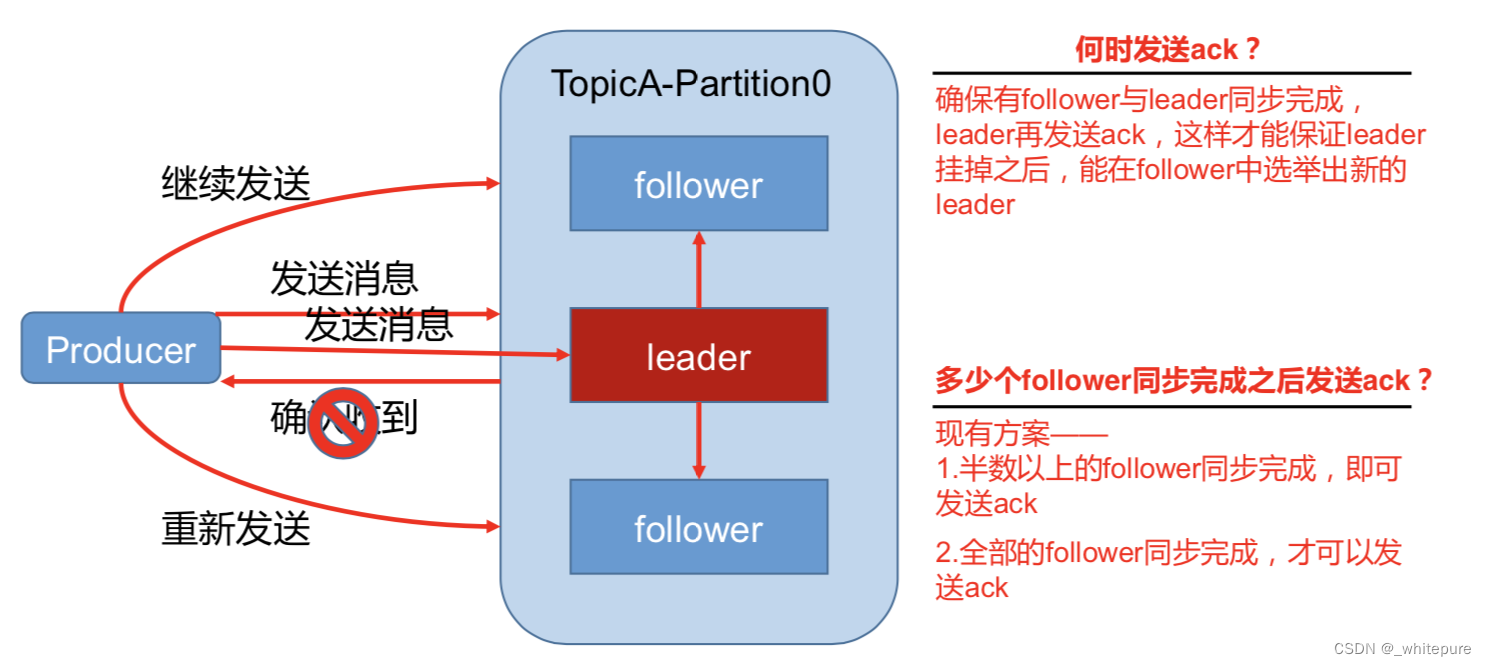
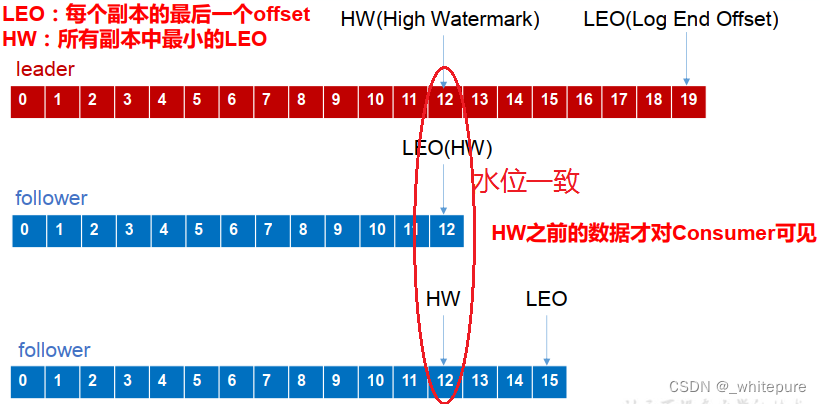
将服务器的 ACK 级别设置为-1,可以包管 Producer 到 Server 之间不会丢失数据,即 At Least Once 语义,至少发送一次;相对的,将服务器 ACK 级别设置为 0,可以包管生产者每条消息只会被发送一次,即 At Most Once 语义,至多发送一次。
至少发送一次可以包管数据不丢失,但是不能包管数据不重复;相对的,至多发送一次可以包管数据不重复,但是不能包管数据不丢失。 但是,对于一些非常重要的信息,比如说买卖业务数据,下游数据消费者要求数据既不重复也不丢失,即 Exactly Once 语义,准确发送一次。
在0.11 版本的 Kafka,引入了一项庞大特性:幂等性。所谓的幂等性就是指生产者不论向 Server 发送多少次重复数据, Server 端都只会持久化一条。幂等性联合 At Least Once 语义,就构成了 Kafka 的 Exactly Once 语义。
要启用幂等性,只需要将 Producer 的参数中 enable.idempotence 设置为 true 即可。
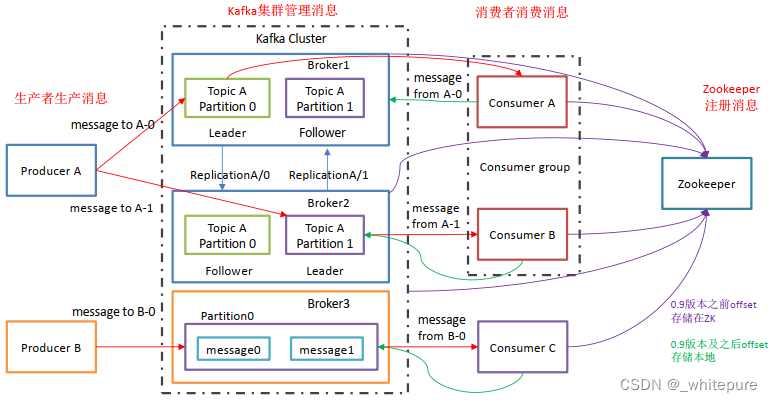
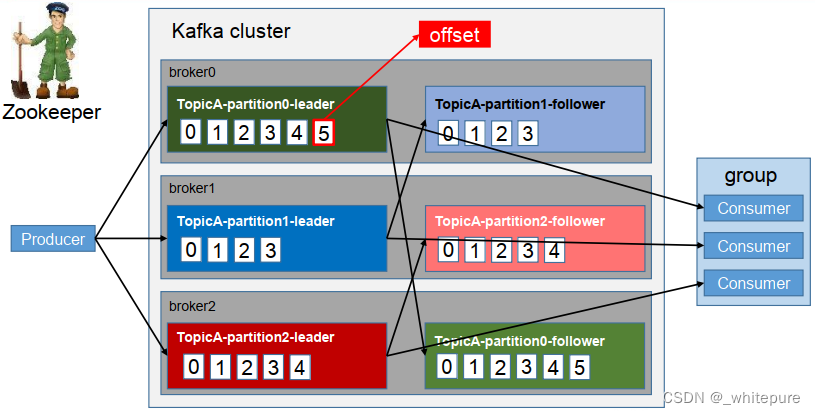
Kafka的幂等性实现实在就是将原来下游需要做的去重放在了数据上游。开启幂等性的 Producer 在初始化的时间会被分配一个 PID,发往同一 Partition 的消息会附带 Sequence Number。而Broker 端会对<ID, Partition, SeqNumber>做缓存,当具有相同主键的消息提交时, Broker 只会持久化一条。但是 PID 重启就会变革,同时不同的 Partition 也具有不同主键,所以幂等性无法包管跨分区跨会话的 Exactly Once。
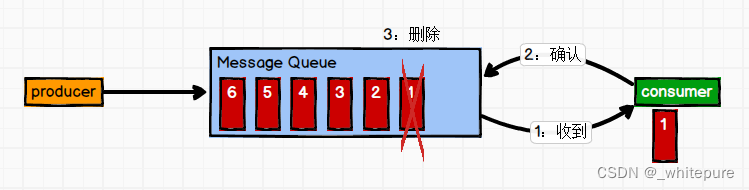
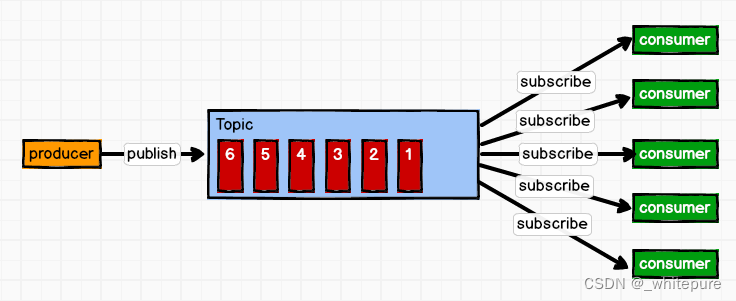
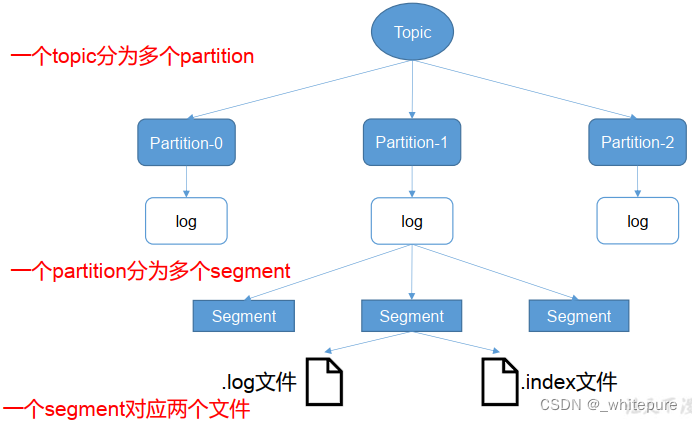
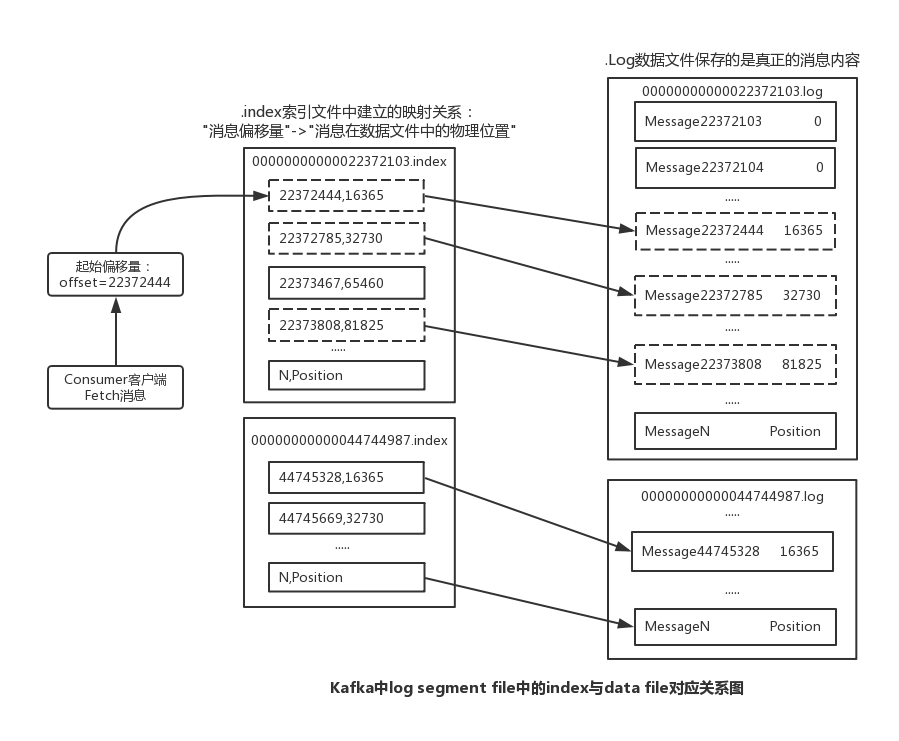
生产者发送消息流程

 ID, Partition, SeqNumber>做缓存,当具有相同主键的消息提交时, Broker 只会持久化一条。但是 PID 重启就会变革,同时不同的 Partition 也具有不同主键,所以幂等性无法包管跨分区跨会话的 Exactly Once。
ID, Partition, SeqNumber>做缓存,当具有相同主键的消息提交时, Broker 只会持久化一条。但是 PID 重启就会变革,同时不同的 Partition 也具有不同主键,所以幂等性无法包管跨分区跨会话的 Exactly Once。