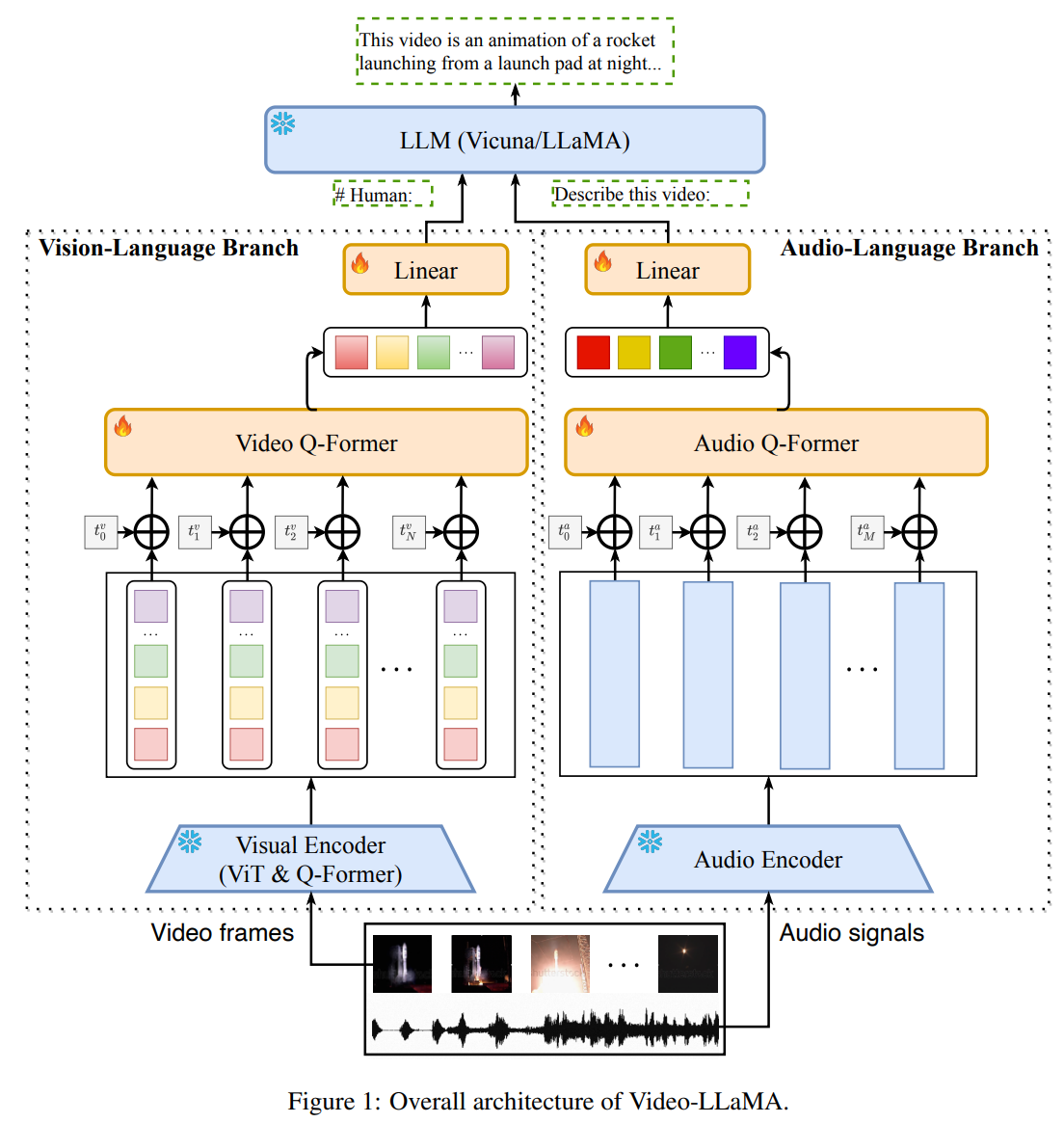
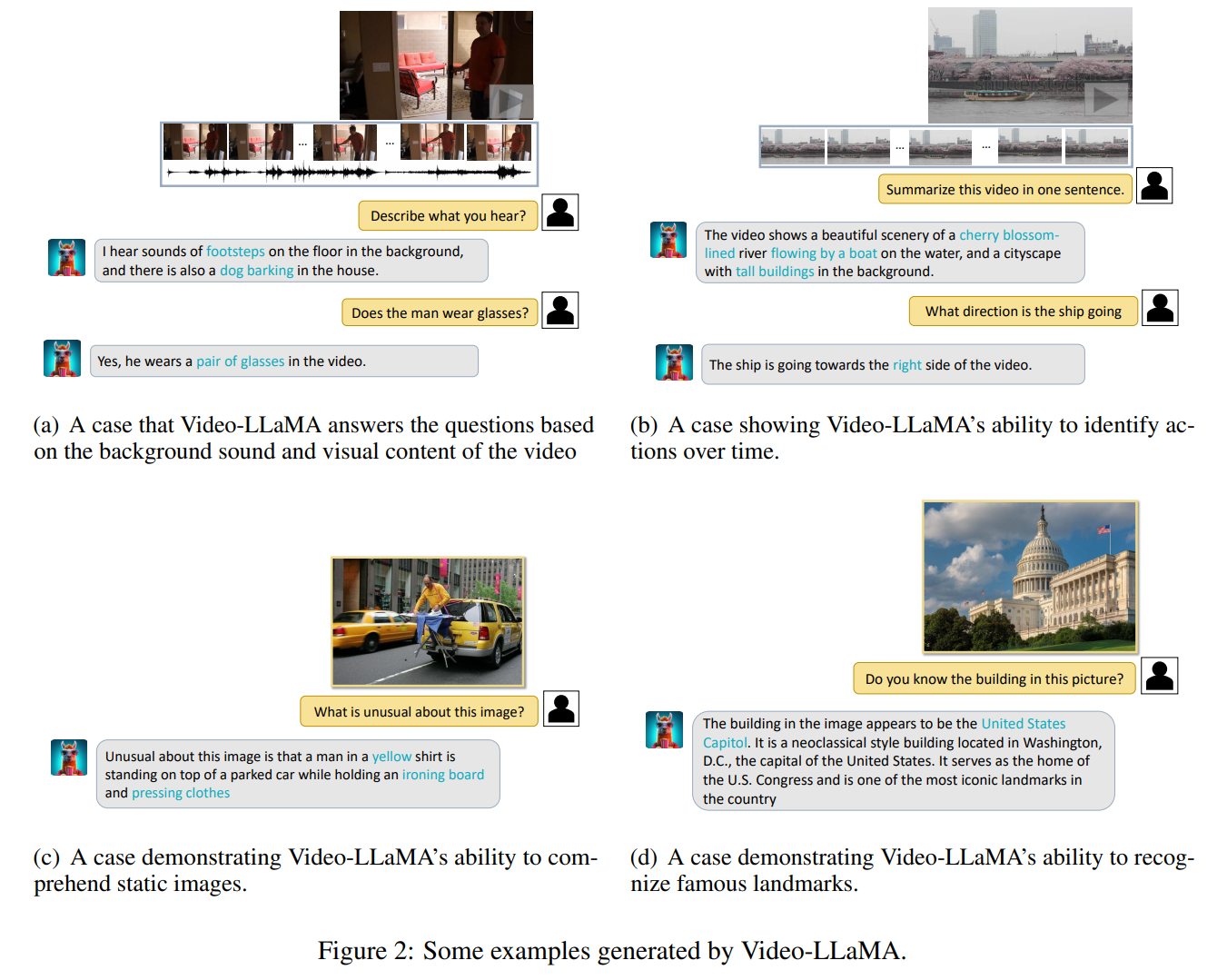
标题: 视频大语言模子调研论文《Video-LLaMA: An Instruction-tuned Audio-Visual [打印本页] 作者: 用户国营 时间: 2024-7-20 18:21 标题: 视频大语言模子调研论文《Video-LLaMA: An Instruction-tuned Audio-Visual 本文是关于论文《Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding》的简要介绍。Video-LLaMA是阿里达摩院的一个多模态大语言模子产品,可以理解视频中视觉和听觉内容。和很多多模态大语言模子类似,模子结构和练习方式中规中矩,但是针对视频这种信息量丰富的数据范例,作者提出了一些创意。
有关本专栏的更多内容,请参考大语言模子文献调研专栏目录