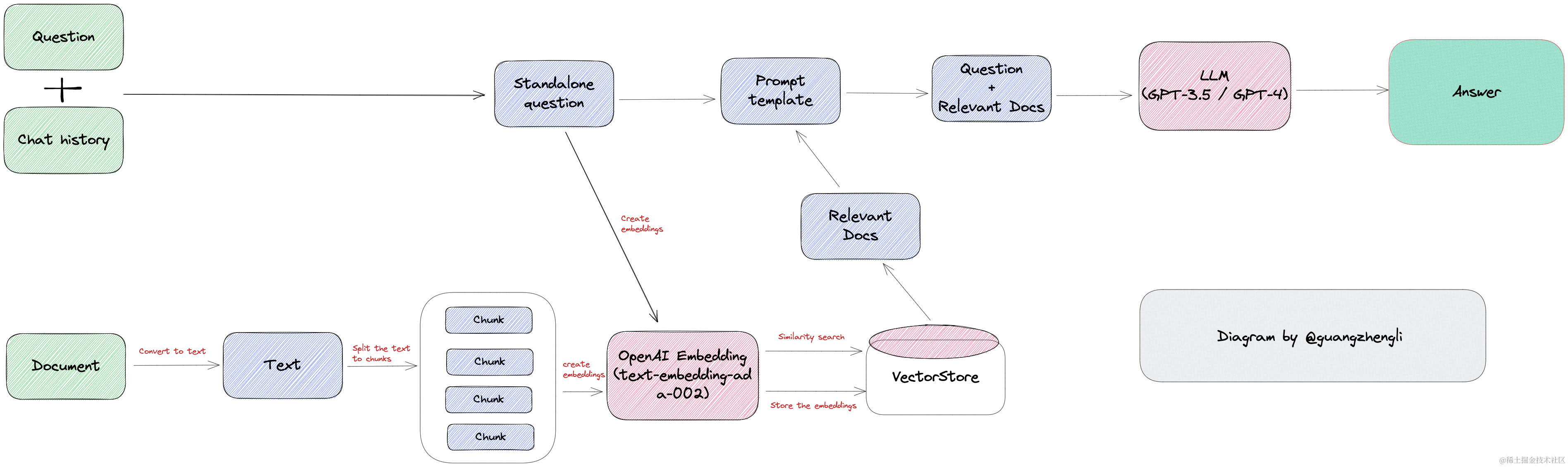
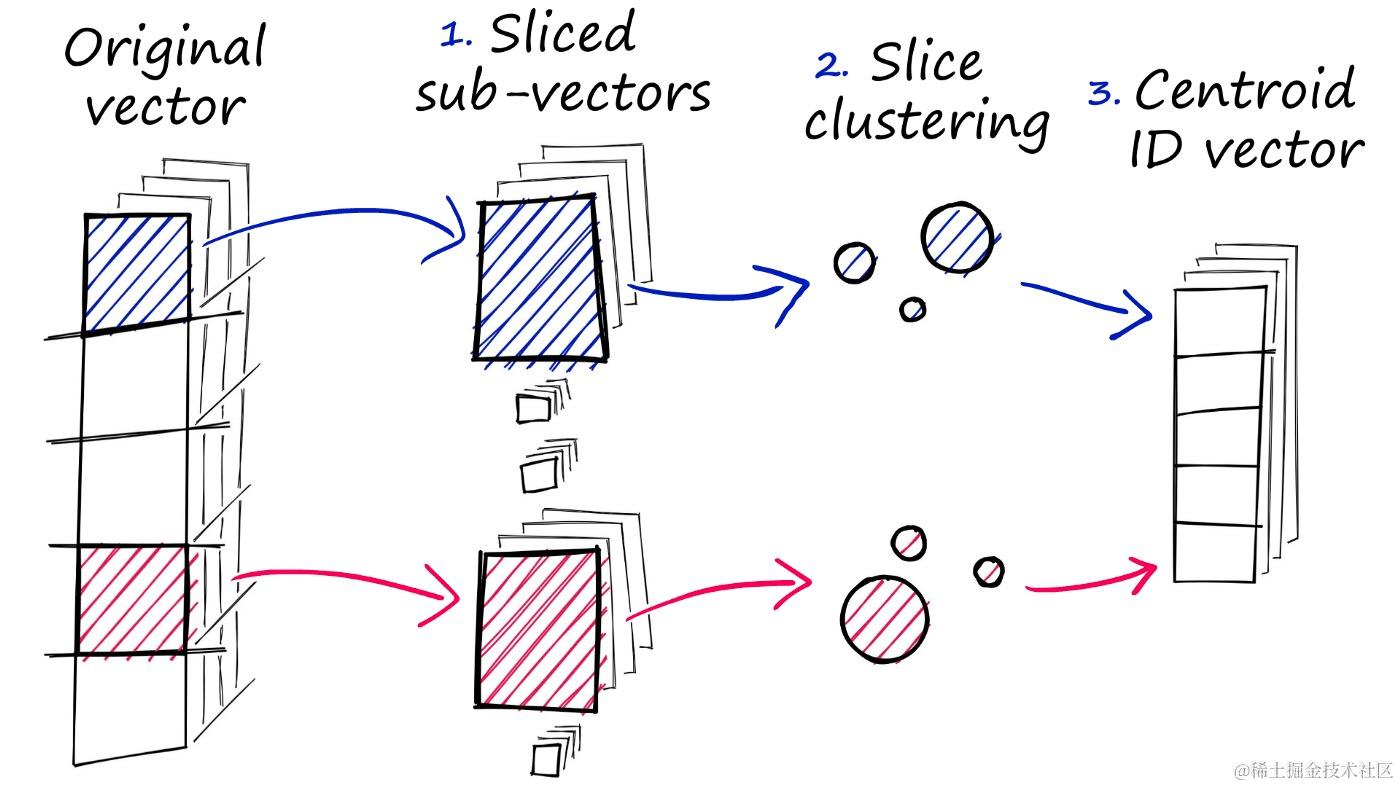
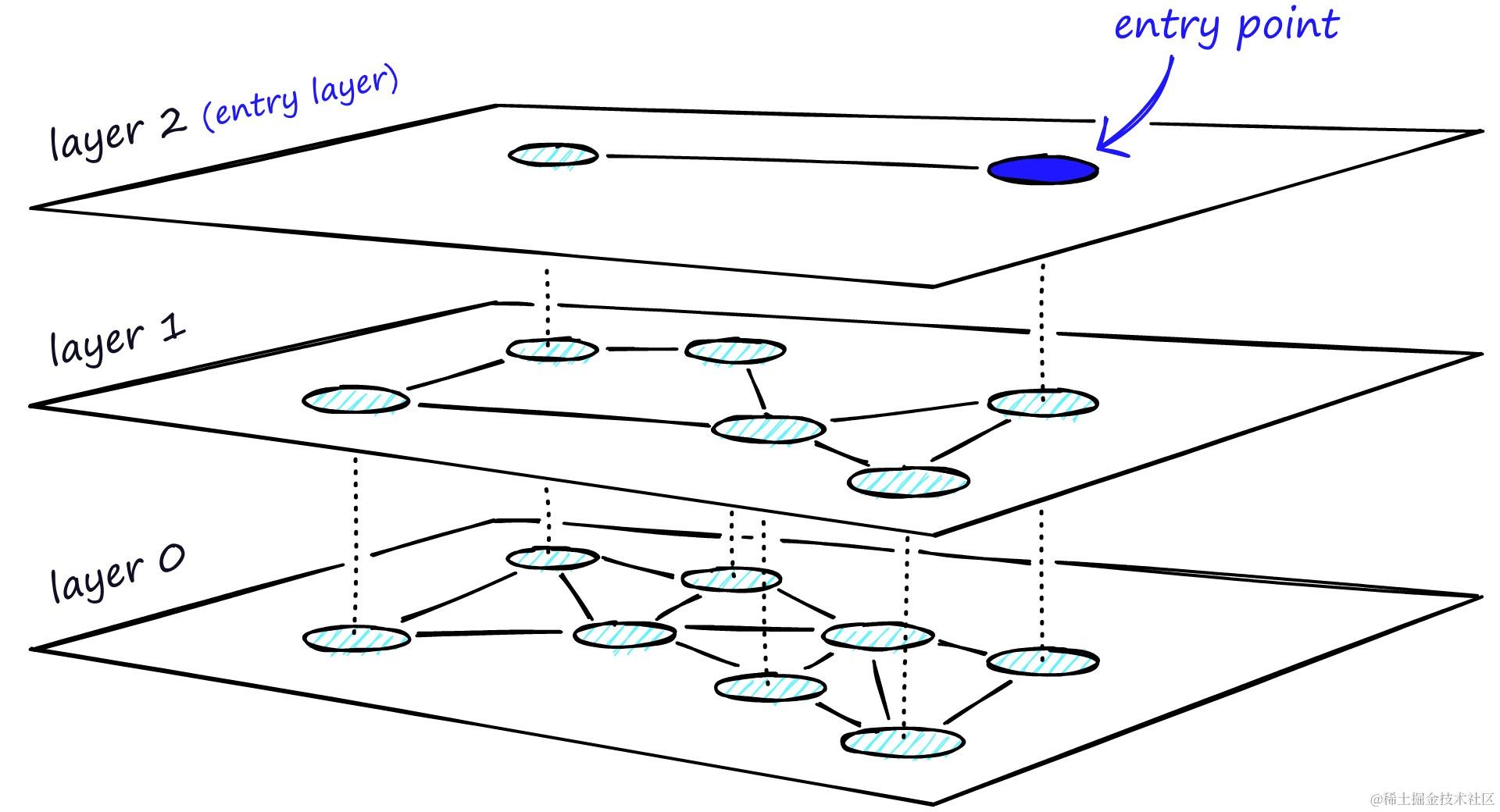
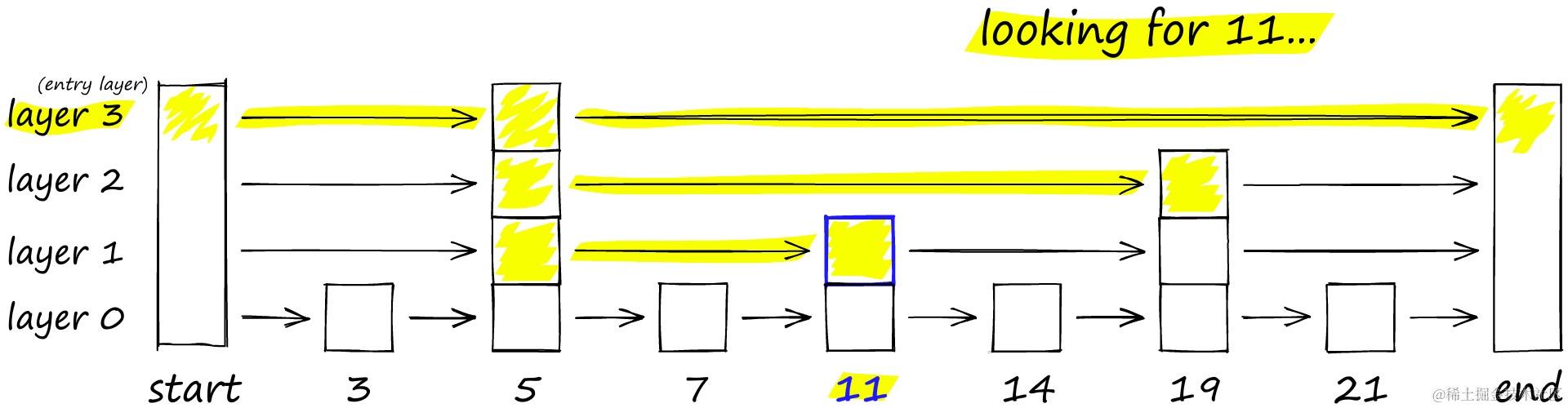
局部敏感哈希(Locality Sensitive Hashing)也是一种使用近似近来邻搜刮的索引技能。它的特点是快速,同时仍然提供一个近似、非穷举的效果。LSH 使用一组哈希函数将相似向量映射到“桶”中,从而使相似向量具有相同的哈希值。这样,就可以通过比力哈希值来判定向量之间的相似度。
通常,我们设计的哈希算法都是力求减少哈希碰撞的次数,由于哈希函数的搜刮时间复杂度是 O(1),但是,假如存在哈希碰撞,即两个不同的关键字被映射到同一个桶中,那么就需要使用链表等数据布局来解决辩说。在这种情况下,搜刮的时间复杂度通常是 O(n),此中n是链表的长度。所以为了提高哈希函数的搜刮的效率,通常会将哈希函数的碰撞概率尽可能的小。
但是在向量搜刮中,我们的目的是为了找到相似的向量,所以可以专门设计一种哈希函数,使得哈希碰撞的概率尽可能高,而且位置越近大概越相似的向量越容易碰撞,这样相似的向量就会被映射到同一个桶中。
等搜刮特定向量时,为了找到给定查询向量的近来邻居,使用相同的哈希函数将类似向量“分桶”到哈希表中。查询向量被散列到特定表中,然后与该表中的其他向量进行比力以找到最靠近的匹配项。这种方法比搜刮整个数据集要快得多,由于每个哈希表桶中的向量远少于整个空间中的向量数。
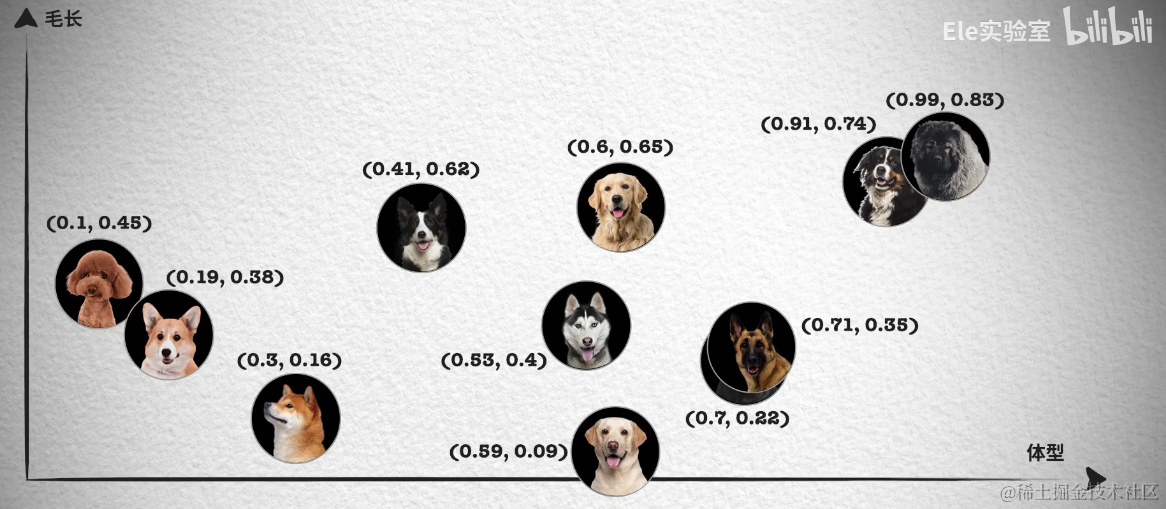
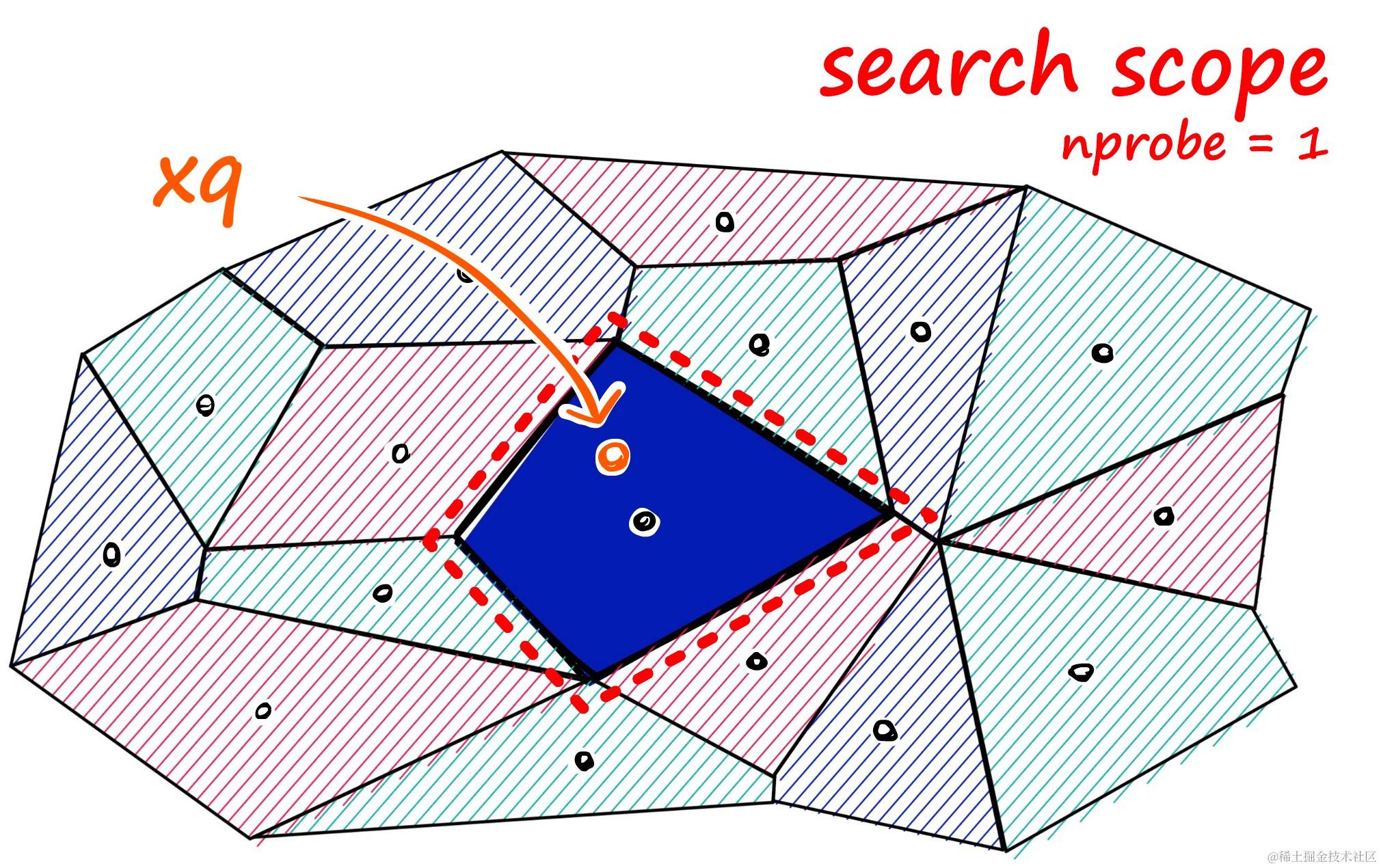
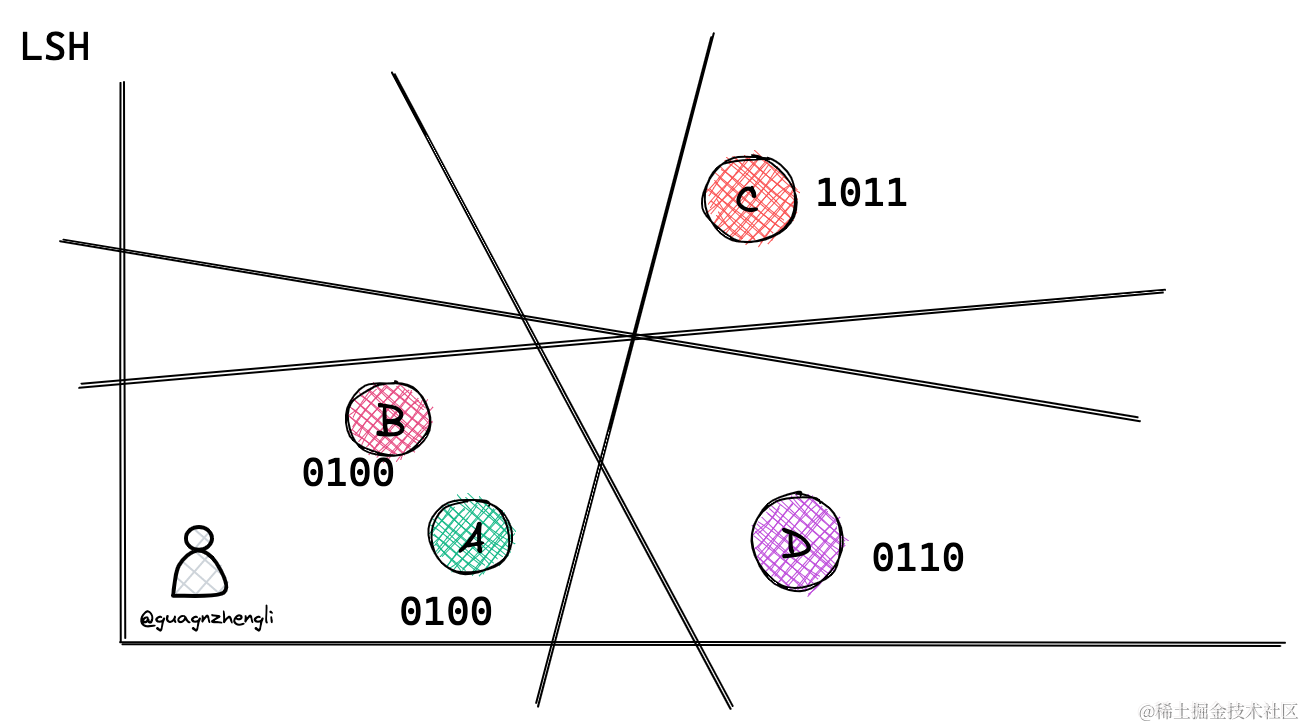
那么这个哈希函数应该怎样设计呢?为了大家更好理解,我们先从二维坐标系解释,如下所图示,在二维坐标系中可以通过随机生成一条直线,将二维坐标系划分为两个地区,这样就可以通过判定向量是否在直线的同一边来判定它们是否相似。例如下图通过随机生成 4 条直线,这样就可以通过 4 个二进制数来表示一个向量的位置,例如 A 和 B 表示向量在同一个地区。
这个原理很简单,假如两个向量的距离很近,那么它们在直线的同一边的概率就会很高,例如直线穿过 AC 的概率就宏大于直线穿过 AB 的概率。所以 AB 在同一侧的概率就宏大于 AC 在同一侧的概率。
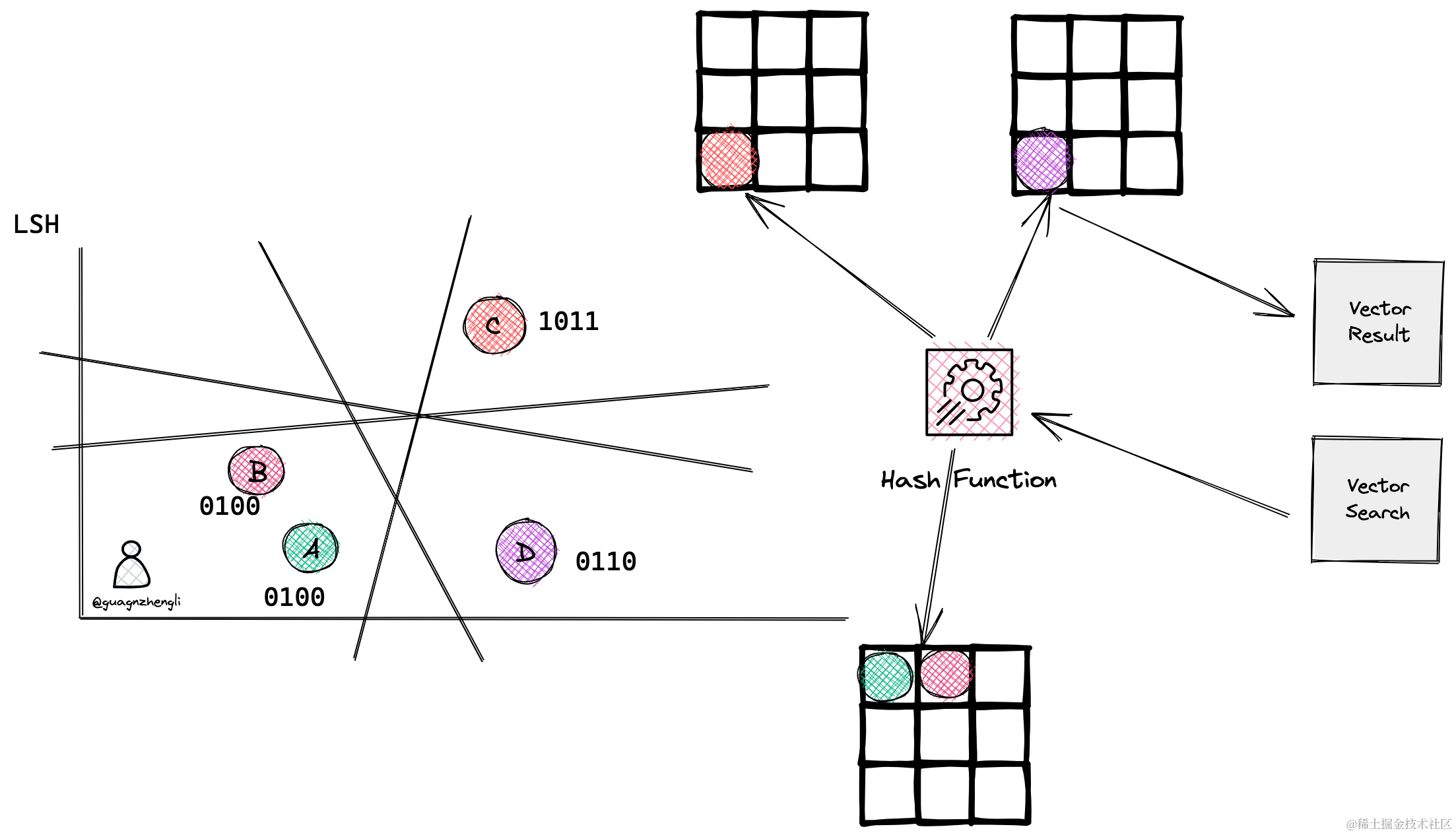
当搜刮一个向量时,将这个向量再次进行哈希函数计算,得到相同桶中的向量,然后再通过暴力搜刮的方式,找到最靠近的向量。如下图假如再搜刮一个向量经过了哈希函数,得到了 0110 的值,就会直接找到和它同一个桶中相似的向量 D。从而大大减少了搜刮的时间。
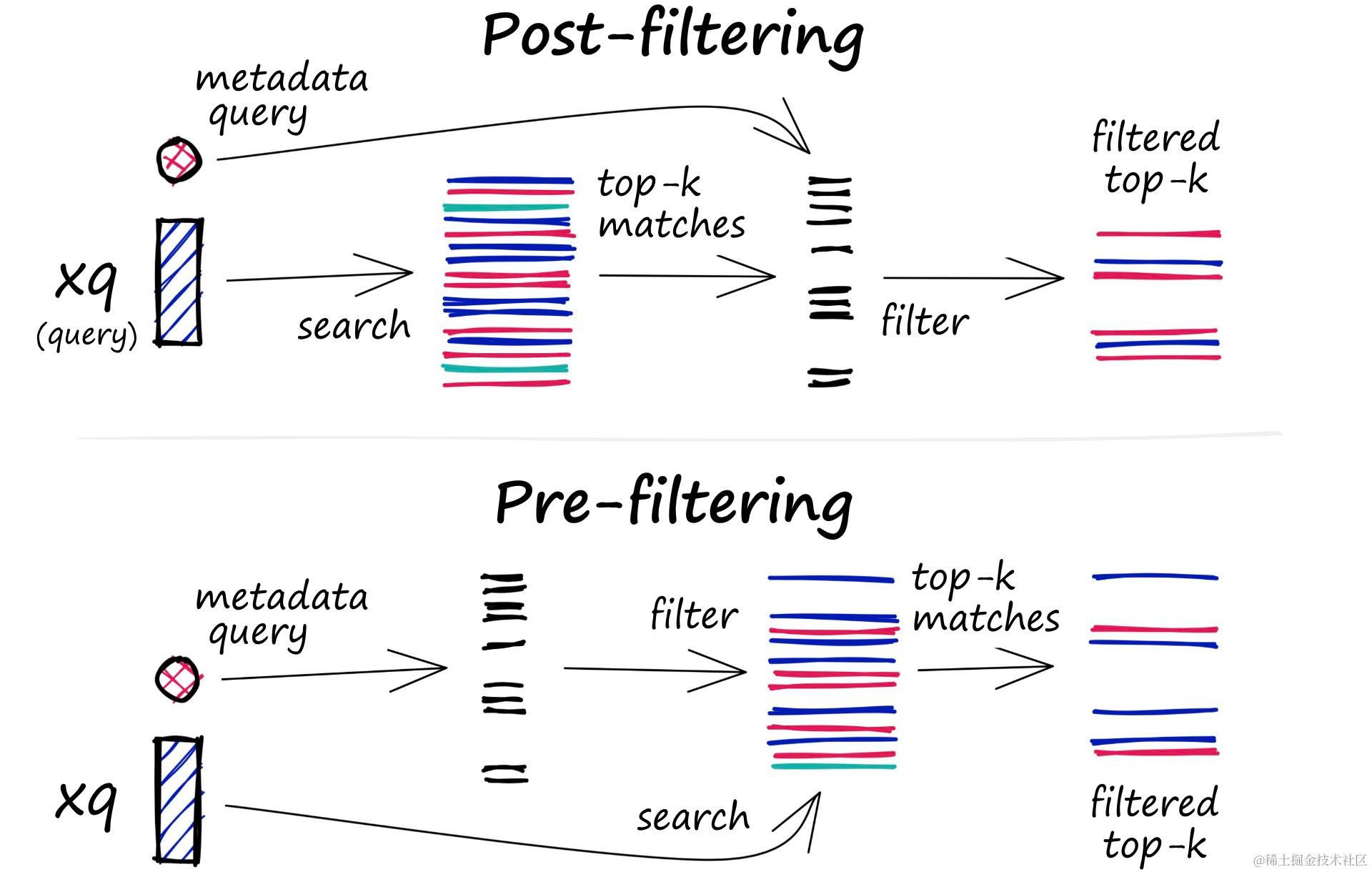
在实际的业务场景中,通常不需要在整个向量数据库中进行相似性搜刮,而是通过部门的业务字段进行过滤再进行查询。所以存储在数据库的向量通常还需要包含元数据,例如用户 ID、文档 ID 等信息。这样就可以在搜刮的时候,根据元数据来过滤搜刮效果,从而得到终极的效果。
为此,向量数据库通常维护两个索引:一个是向量索引,另一个是元数据索引。然后,在进行相似性搜刮本身之前或之后实行元数据过滤,但无论哪种情况下,都存在导致查询过程变慢的困难。
除此之外,访问控制设计的是否充足,例如当构造和业务快速发展时,是否能够快速的添加新的用户和权限控制,是否能够快速的添加新的节点,审计日志是否美满等等,都是需要考虑的因素。
别的,数据库的监控和备份也是一个重要的因素,当数据出现故障时,能够快速的定位题目和恢复数据,是一个成熟的向量数据库必须要考虑的因素。
API & SDK
对比上面的因素选择,API & SDK 可能是通常被忽略的因素,但是在实际的业务场景中,API & SDK 通常是开辟者最关心的因素。由于 API & SDK 的设计直接影响了开辟者的开辟效率和使用体验。一个优秀良好的 API & SDK 设计,通常能够顺应需求的不同变革,向量数据库是一个新的范畴,在如今大部门人不太清楚这方面需求的当下,这一点容易被人忽视。
选型
本文主要介绍了向量数据库的原理和实现,包罗向量数据库的根本概念、相似性搜刮算法、相似性测量算法、过滤算法和向量数据库的选型等等。向量数据库是极新的范畴,目前大部门向量数据库公司的估值乘着 AI 和 GPT 的东风从而飞速的增长,但是在实际的业务场景中,目前向量数据库的应用场景还比力少,抛开浮躁的外衣,向量数据库的应用场景还需要开辟者们和业务专家们去挖掘。