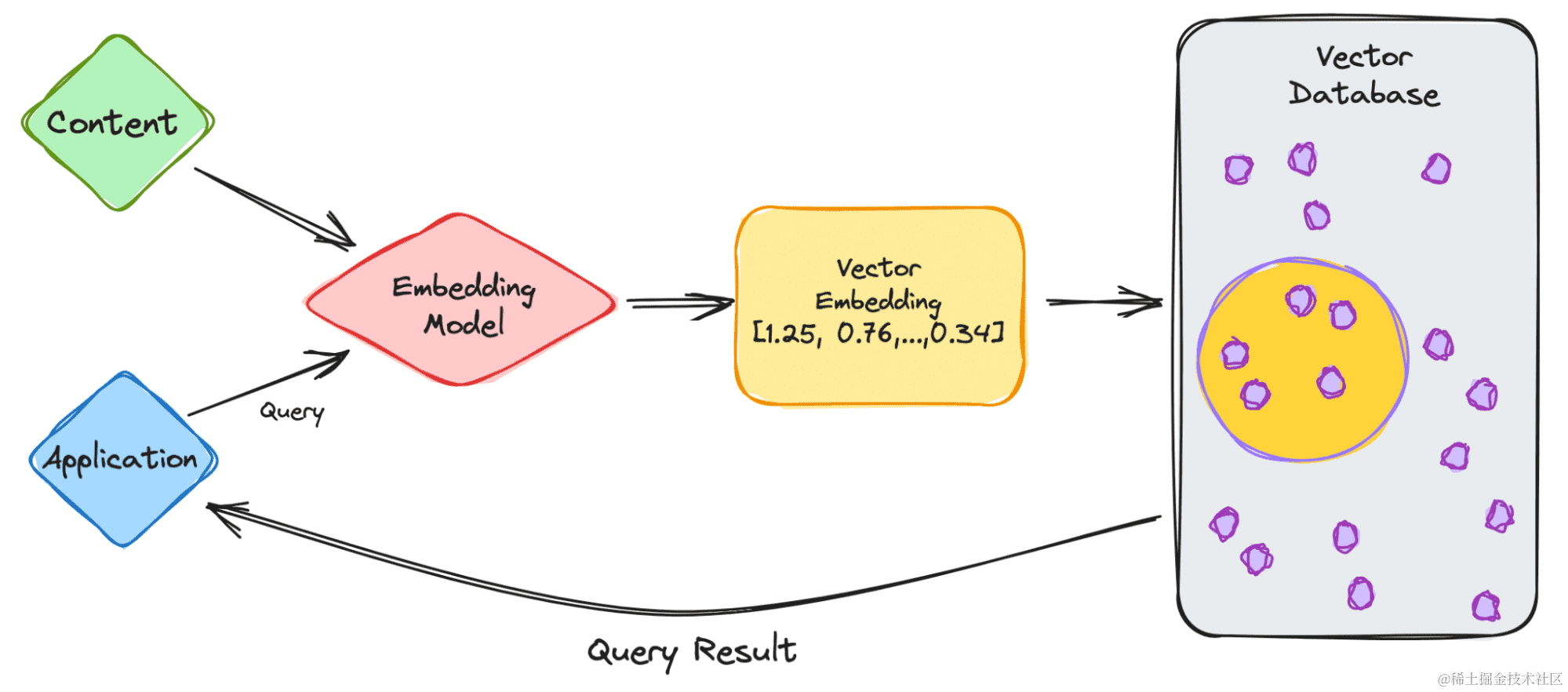
关于基于内容的检索的末了一点越来越重要,并促进了一种新的应用: 使用上下文明白来加强LLMs:通过存储和处置惩罚文本嵌入,向量数据库可以资助LLMs实现更精致化以及上下文相干的检索工作。它们可以资助明白大量文本的语义内容,在回回复杂搜索、维护对话上下文或生成相干内容等任务中起着关键作用。这种应用正迅速成为向量数据库的一个重要场景,展示了其在加强高级AI系统(如LLM)本领方面起到的作用。
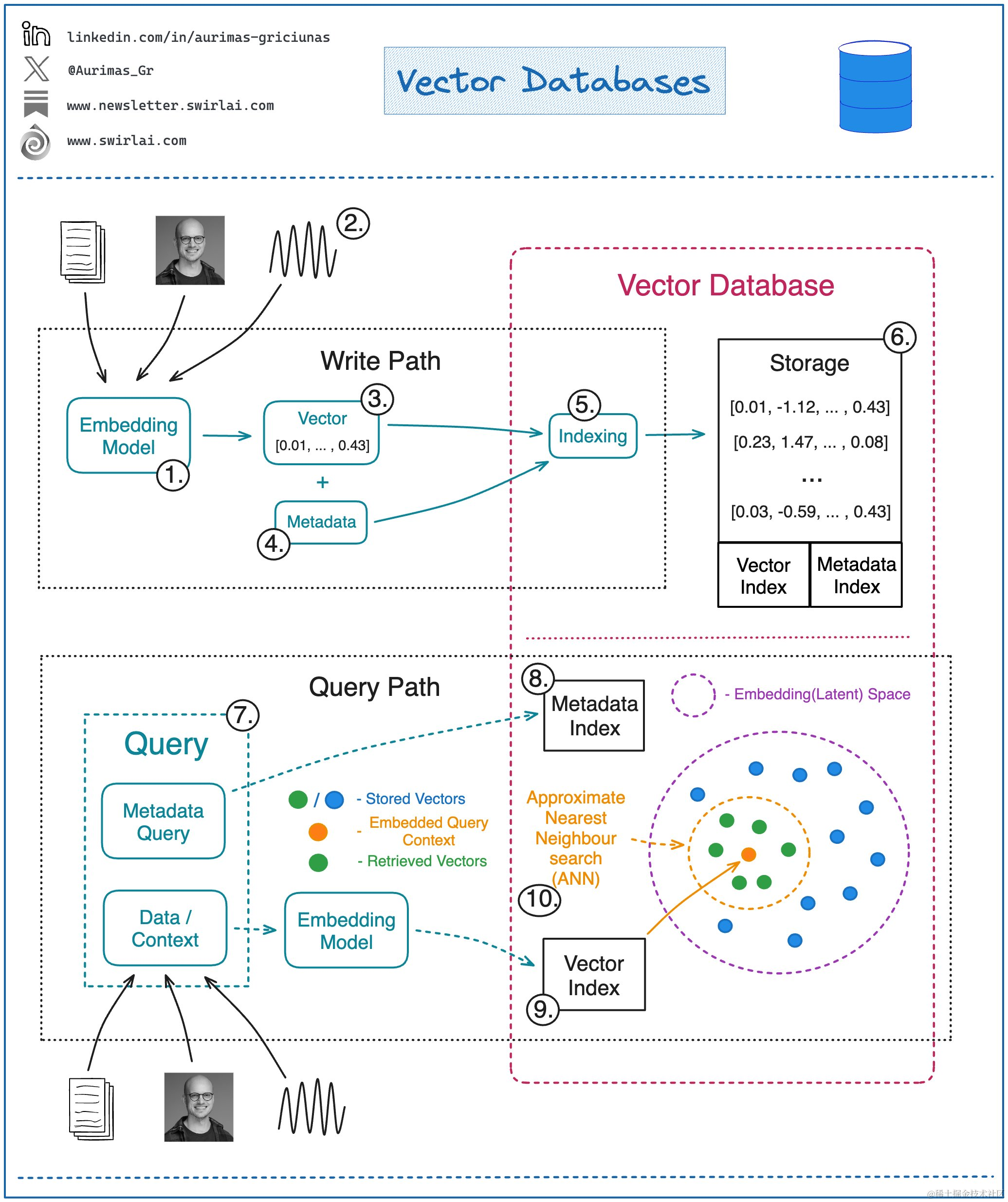
向量数据库 vs 传统数据库
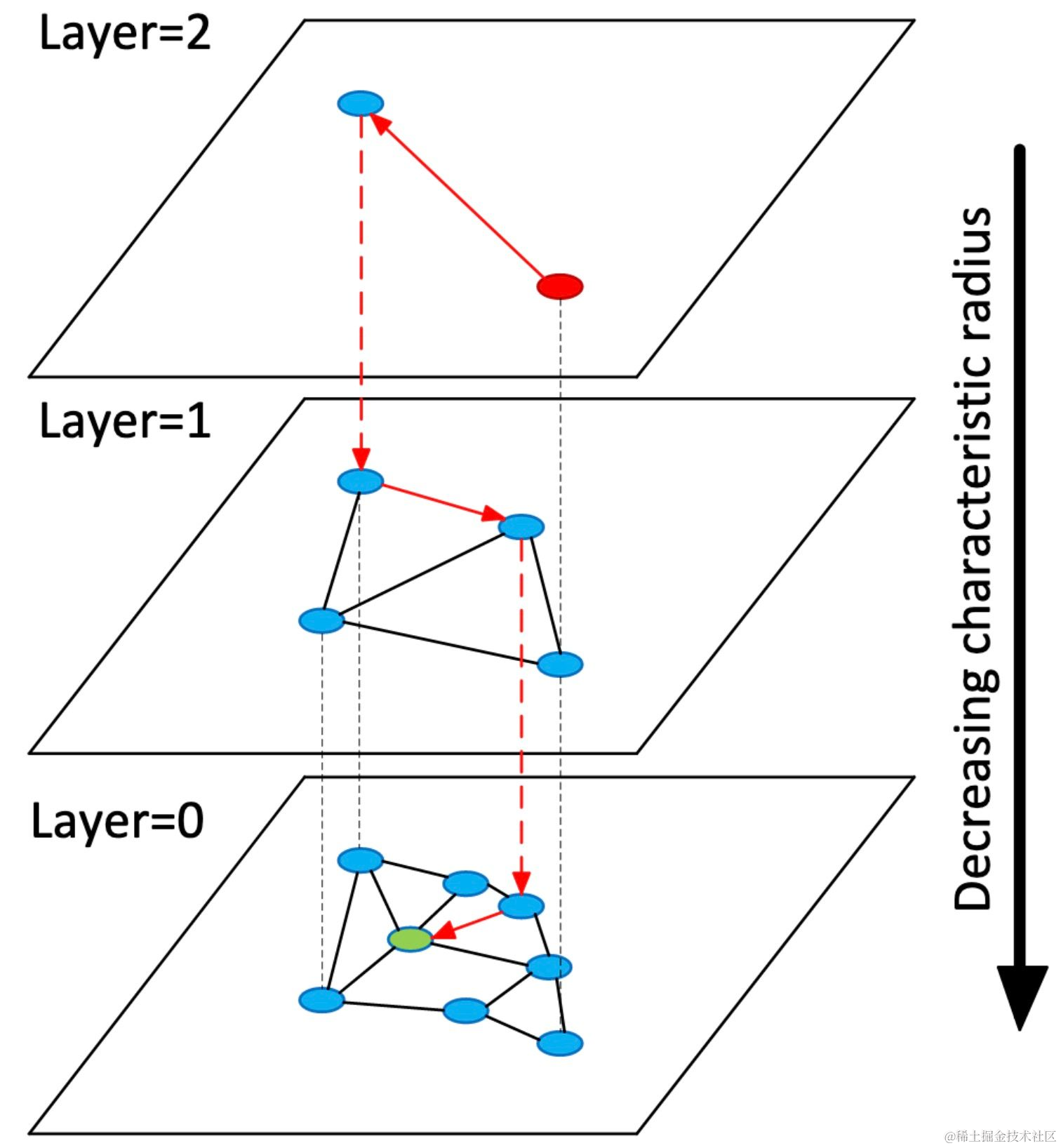
HNSW(Hierarchical Navigable Small World,分层可导航小世界)图:HNSW是一种构建分层图的索引策略,每层代表数据集中的一个不同粒度。查询从顶层开始,顶层具有较少、更远的点,然后向下移动到更详细的层级。这种方式可以快速遍历数据集,通过快速缩小相似向量的候选集合,大大减少了搜索时间。
倒排文件索引(Inverted File Index,IVF):IVF使用k-means这样的算法将向量空间分为预定义数目的几个聚类。每个向量分配给最近的聚类,在一个搜索中,只会涉及到最相干聚类中的向量。这种方式降低了搜索空间,提升了查询速度。通过将IVF和其他技术(如IVFADC-Inverted File Index with Asymmetric Distance Computation, 就结合了IVF和Quantization)相结合,可以通过进一步降低间隔计算成本来提升性能。
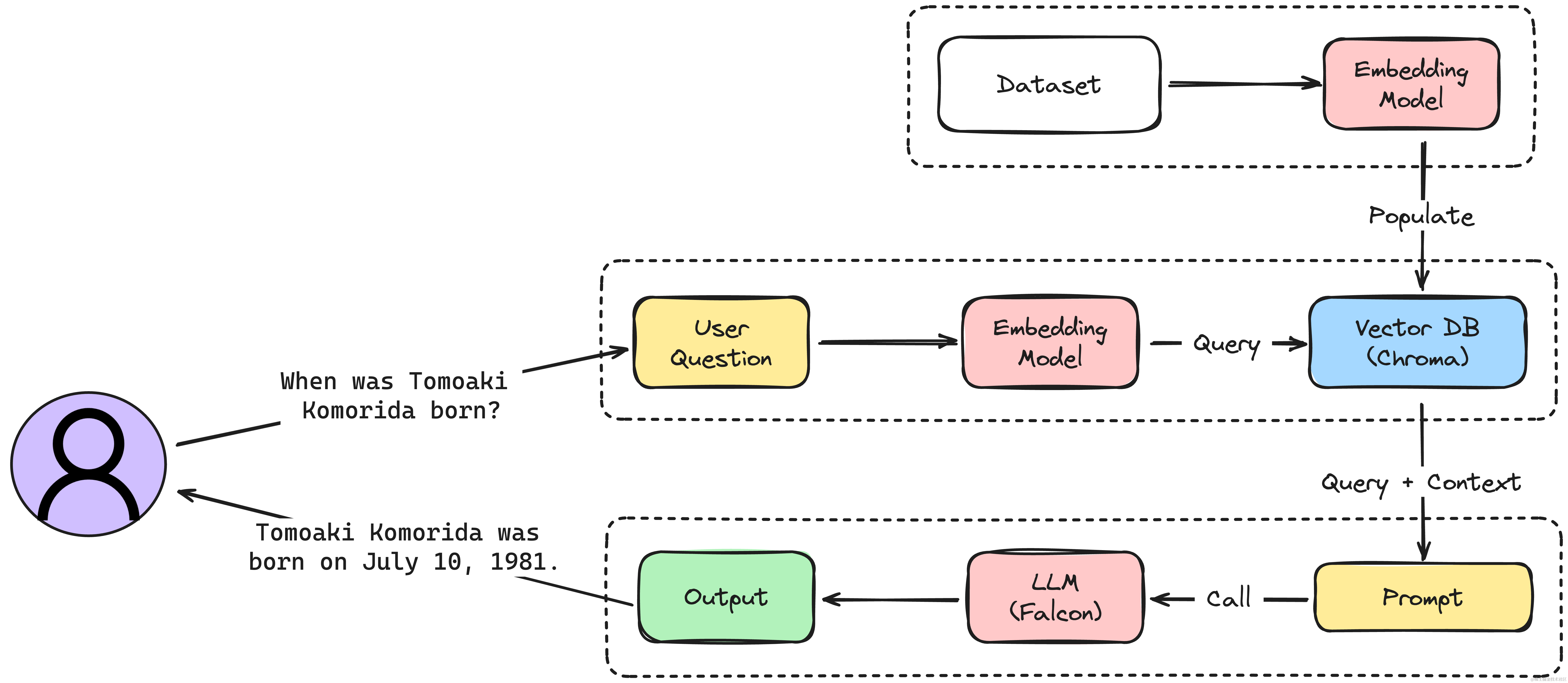
"context": "Komorida was born in Kumamoto Prefecture on July 10, 1981. After graduating from high school, he joined the J1 League club Avispa Fukuoka in 2000. His career involved various positions and clubs, from a midfielder at Avispa Fukuoka to a defensive midfielder and center back at clubs such as Oita Trinita, Montedio Yamagata, Vissel Kobe, and Rosso Kumamoto. He also played for Persela Lamongan in Indonesia before returning to Japan and joining Giravanz Kitakyushu, retiring in 2012.",
"response": "Tomoaki Komorida was born on July 10, 1981.",
"category": "closed_qa"
}
复制代码
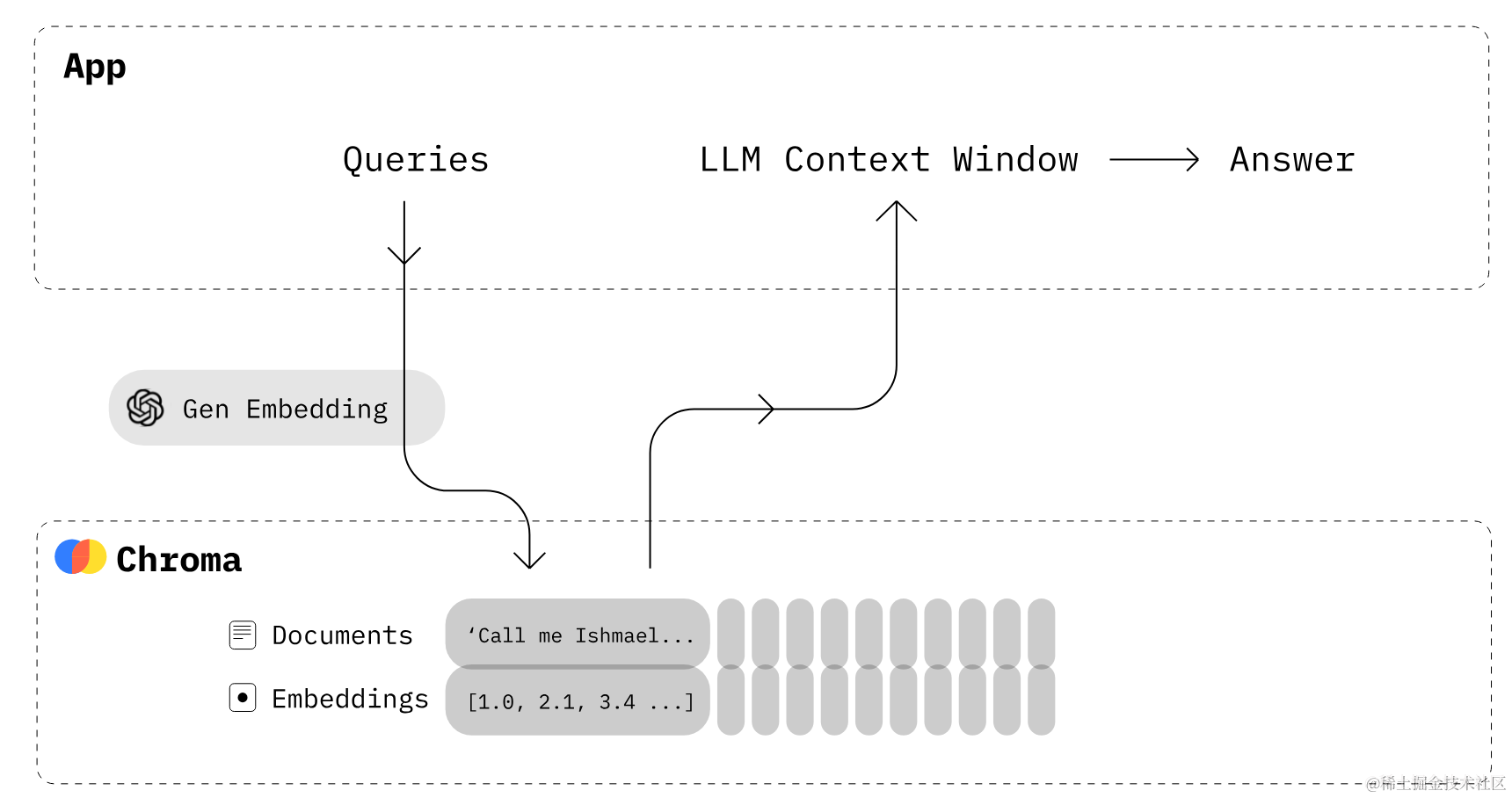
下面,我们将重点为每组指令及其各自的上下文生成词嵌入,并将它们集成到向量数据库ChromaDB中。
Chroma DB是一个开源的向量数据库系统,擅长管理向量嵌入,专为语义查询引擎之类的应用量身定做,这种本领在自然语言处置惩罚和呆板学习领域至关重要。Chroma DB作为一个内存型数据库,支持数据的快速访问和高速处置惩罚。其友好的Python设置加强了对我们项目的吸引力,简化了与我们工作流程的集成。更多拜见Chroma DB 文档。